本文主要是介绍北京市行政村边界shp数据/北京市乡镇边界/北京市土地利用分类数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
北京是一座有着三千多年历史的古都,在不同的朝代有着不同的称谓,大致算起来有二十多个别称。北京地势西北高、东南低。西部、北部和东北部三面环山,东南部是一片缓缓向渤海倾斜的平原。境内流经的主要河流有:永定河、潮白河、北运河、拒马河等,多由西北部山地发源,穿过崇山峻岭,向东南蜿蜒流经平原地区,最后分别汇入渤海。
数据范围:全国行政区划-行政村界
数据类型:面状数据,全国各省市县【村庄-边界】乡村界、乡村范围、村界数据
数据属性:标准12位行政区划编码、村名称、所属地区
分辨率:1:2万--1:5万
数据格式:SHP数据(arcgis矢量数据格式)
五级行政区划:村边界数据产品涵盖五级行政区划:
(一级行政区)省级行政区共31个其中:(台湾、香港、澳门除外);
(二级行政区)地级行政区共334个其中:7个地区、3个盟、30个自治州、294个地级市;
(三级行政区)县级行政区共2851个其中:1355个县、117个自治县、49个旗、3个自治旗、363个县级市、962个市辖区、1个林区、1个特区;
(四级行政区)乡级行政区共40497个其中:11626个乡、1034个民族乡、20117个镇、7566个街道、151个苏木、1个民族苏木、2个县辖区公所;
(五级行政区)村级行政区共约731658个行政村、社区。
12位村级代码,第1~2位,为省级代码;第3~4 位,为地级代码;第5~6位,为县级代码;第7~9位,为乡级代码;第10~12位,为村级代码。。
地理遥感生态网通过获取北京市地面逐日资料,在2000国家大地坐标系下(CGCS2000)基于克里金插值方法,同时结合高程对温度的影响,对气象站点数据进行空间插值,得到逐月的月降水量分布数据,这样就将离散的气象站点资料转换为规则的网格序列,可有效地反映降水要素的空间信息。
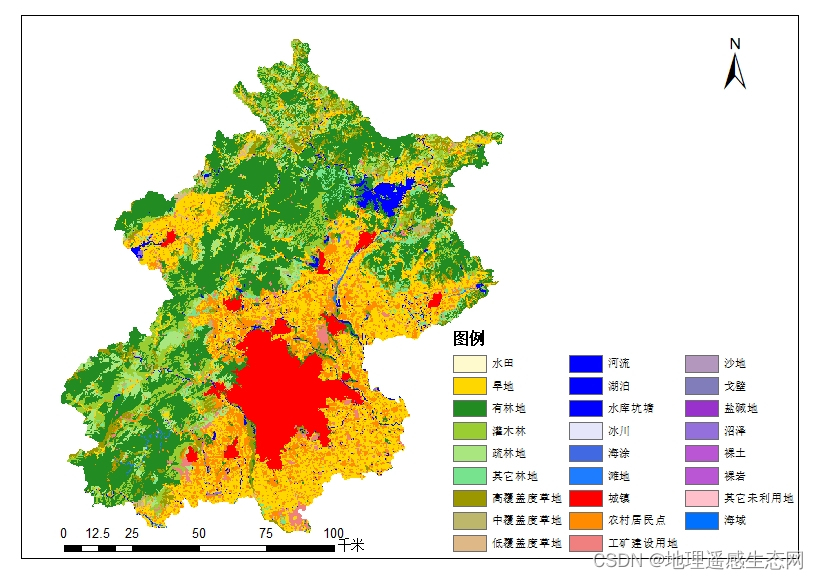
土地利用数据是在根据影像光谱特征,结合野外实测资料,同时参照有关地理图件,对地物的几何形状,颜色特征、纹理特征和空间分布情况进行分析,建立统一解译标志的基础之上,依据多源卫星遥感信息,结合实地调查和其他辅助数据,采用全数字化人机交互作业方法,主要根据对图像光谱、纹理、色调等的认识结合地形图目视解译而成;在内业建立解译标示与实现数据获取的基础上,结合外业实地考察验证,提高土地利用数据精度。
北京市土地利用数据产品是地理遥感生态网平台基于Landsat TM/ETM/OLI遥感影像,采用遥感信息提取方法,并结合野外实测,以及参照国内外现有的土地利用/土地覆盖分类体系,经过波段选择及融合,图像几何校正及配准并对图像进行增强处理、拼接与裁剪,将全国土地利用类型划分为6个一级类,25个二级分类以及部分三级分类的土地利用/土地覆盖数据产品。
原文链接:https://bbs.csdn.net/forums/gisrs?spm=1001.2014.3001.6682
这篇关于北京市行政村边界shp数据/北京市乡镇边界/北京市土地利用分类数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






