本文主要是介绍[LeetCode][426]【学习日记】将二叉搜索树转化为排序的双向链表——前驱节点pre 和 当前节点cur 的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目
426. 将二叉搜索树转化为排序的双向链表
将一个 二叉搜索树 就地转化为一个 已排序的双向循环链表 。
对于双向循环列表,你可以将左右孩子指针作为双向循环链表的前驱和后继指针,第一个节点的前驱是最后一个节点,最后一个节点的后继是第一个节点。
特别地,我们希望可以就地完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中最小元素的指针。
- 示例 1:
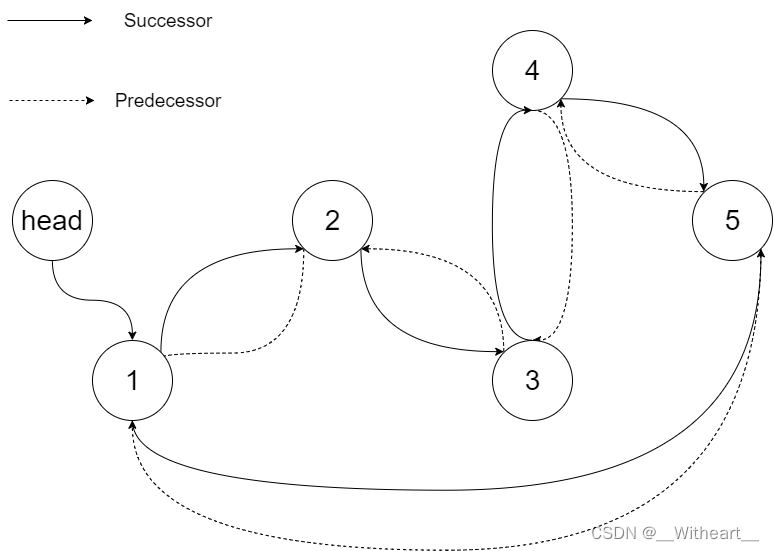
输入:root = [4,2,5,1,3]输出:[1,2,3,4,5]
解释:下图显示了转化后的二叉搜索树,实线表示后继关系,虚线表示前驱关系。
- 示例 2:
输入:
root = [2,1,3]输出:[1,2,3]
- 示例 3:
输入:
root = []输出:[]解释:输入是空树,所以输出也是空链表。
- 示例 4:
输入:
root = [1]输出:[1]
提示:-1000 <= Node.val <= 1000 Node.left.val < Node.val < Node.right.val Node.val 的所有值都是独一无二的 0 <= Number of Nodes <= 2000

解法
解法来源:https://leetcode.cn/leetbook/read/illustration-of-algorithm/lxh893/
思考:
- 本题是二叉搜索树
- 对二叉搜索树,如果采用中序遍历,可得有序序列,因此考虑中序遍历
- 要形成双向链表,结合中序遍历为”左、根、右“的特点,设置 前驱节点pre 和 当前cur 指针会方便节点的指针修改,也就是 pre->right=cur、cur->left=pre
- 在遍历过程中,首先传入 cur->left,然后就对pre 和 cur的指向进行修改,修改完毕后更新pre,最后传入 cur->right
- 最终要形成循环链表,那么应该设置一个头节点head 指向第一个遍历到的节点(最小的节点);最后遍历到的节点就是最大的,也就是尾节点,更新完成后 pre 就是尾节点。此时更新头尾节点的指向使链表循环 head->left=pre pre->right=head
/*
// Definition for a Node.
class Node {
public:int val;Node* left;Node* right;Node() {}Node(int _val) {val = _val;left = NULL;right = NULL;}Node(int _val, Node* _left, Node* _right) {val = _val;left = _left;right = _right;}
};
*/class Solution {
public:Node *pre, *head;void dfs(Node* cur){if(!cur) return;dfs(cur->left);if(!pre) head=cur;else pre->right=cur;cur->left=pre;pre=cur;dfs(cur->right);}Node* treeToDoublyList(Node* root) {if(!root) return nullptr;dfs(root);head->left=pre;pre->right=head;return head;}
};
这篇关于[LeetCode][426]【学习日记】将二叉搜索树转化为排序的双向链表——前驱节点pre 和 当前节点cur 的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




