本文主要是介绍论文笔记:Multiplex Heterogeneous Graph Convolutional Network,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Multiplex Heterogeneous Graph Convolutional Network
现有的工作忽略了多类型节点之间多重网络的关系异质性和节点嵌入元路径中关系的不同重要性
导致很难捕获到跨不同关系的异构结构信号
什么是多类型节点之间多重网络的关系异质性?
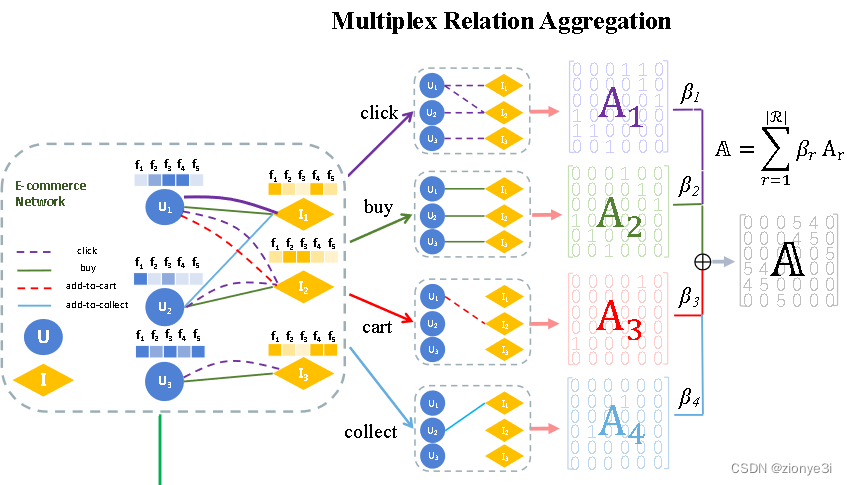
首先要知道什么是多重网络(multiplex network),在一个网络中,用户可能会对一个商品有多种交互,比如点击、购买、评论,这些交互都形成了用户节点与商品节点交互的边,但这些边的类型不同,同一对节点之间有不同类型的边,就构成了一个多重网络。“点击、购买、评论“形成了关系异质性。
节点嵌入元路径中关系的不同重要性?
假设有元路径IUI(Item-User-Item),那Item-User之间的关系有可能是点击、购买、评论,如果是购买Item和Item之间会形成同购(co-purchased)关系,代表这两个Item被一起购买,其他的就是“同点”、“同评”,这些关系在图表征学习中意义是不一样的。
MHGCN
Ⅰ.通过多层卷积聚合,能够自动学习多重异构网络中不同长度的异构元路径交互。
Ⅱ.通过无监督和半监督学习范式,有效地将多重关系结构和属性语义融合到节点embedding中。
先把多重网络分成多个同构网络和二部子网(就是就是把多重网络转化成 ∣ R ∣ |R| ∣R∣个二分图,每个二分图只有一种类型的边, R R R是多重网络中关系类型的集合)
然后重新把二部子网聚合,探索它们在节点表示学习中的重要性
Introduction
本文把具有多重结构和多类型节点和节点信息的网络称为Attributed Multiplex HEterogeneous Networks(AMHENs)
三个现有的挑战:
Ⅰ.现在图表征学习的成功很大程度上依赖于元路径设计的准确性(需要手动设置元路径,可能会需要其他领域的知识),所以如何去设计一个自动学习框架,来学习AMHENs中复杂的基于元路径的关系,仍然是一个挑战。
Ⅱ.每条源路径能被看作关系信息通道,一个有效的元路径依赖编码器是将多重性和异构性融入到表征里的必要条件。
Ⅲ.现有的网络时空效率不够高。
本文的三点贡献:
Ⅰ.提出了MHGCN,捕获节点之间有用的关系感知的拓扑结构信息
Ⅱ.MHGCN结合网络结构和节点属性特征到节点表征中
Ⅲ.广泛的实验
Methodology
MHGCN分成两部分:多重关系聚合和多层图卷积
多重关系聚合通过区分各个关系的重要性来聚合多重异构网络中异构节点的多重关系
多层图卷积通过聚合邻居的特征来学习低维度的节点表征,自动捕获不同长度的异构元路径信息
Multiplex Relation Aggregation
先根据边的类型把图分成 ∣ R ∣ |R| ∣R∣个子图,会对每个子图分配一个权重 β r β_r βr,代表关系 r r r在图中的重要性
然后聚合具有不同权重的关系图 A = ∑ r = 1 R β r A r A=\sum_{r=1}^{R}\beta_rA_r A=∑r=1RβrAr
其中 β r \beta_r βr是可学习参数,根据不同的下流任务而改变, A = ∑ r = 1 R A r A=\sum_{r=1}^{R}A_r A=∑r=1RAr
Multilayer Graph Convolution Module
先前的工作需要手动地定义元路径,然后在采样的异质元路径上学习节点表征。
但人工手动的元路径的设置和采样是一个复杂的任务,在大型网络里,拥有大量的元路径,需要花费很多时间去采样如此大的元路径。同时选择正确的元路径也是很困难的。
而元路径的设置对节点表征有很大影响,所以元路径的设置很大程度上决定了在下游任务中embedding的表现。
这里的采样(Sample)如何理解?
我的理解是,如果节点类型有U(User)和I(Item)的话,长度为 n n n的元路径就有 2 n 2^n 2n条,但显然 U U . . . U UU...U UU...U和 I I . . I II..I II..I这种不是我们想要的,但之前的工作只能人工采样来排除这种不理想的元路径,来设置 U I U I . . . UIUI... UIUI...或者 I U I U . . . IUIU... IUIU...这种有用的元路径。
基于以上动机,这个模块目标就是能够自动地(automatically)捕获长的短的元路径信息。
文中用两层Simplifying GCN来阐述这个模块是如何工作的,Simplifying代表不用激活函数的GCN,对于第一层
H ( 1 ) = A ⋅ X ⋅ W ( 1 ) H^{(1)}=A \cdot X \cdot W^{(1)} H(1)=A⋅X⋅W(1)
H ( 1 ) H^{(1)} H(1)是第一层的输出, X ∈ R n × m X\in R^{n\times m} X∈Rn×m是节点属性矩阵, W ( 1 ) W^{(1)} W(1)是第一层的参数, A A A是长度为1的所有元路径的重要程度(权重)的聚合,那么对于第二层:
H ( 2 ) = A ⋅ H ( 1 ) ⋅ W ( 2 ) = A ⋅ ( A ⋅ X ⋅ W ( 1 ) ) ⋅ W ( 2 ) = A 2 ⋅ X ⋅ W ( 1 ) ⋅ W ( 2 ) H^{(2)}=A\cdot H^{(1)}\cdot W^{(2)}=A\cdot (A\cdot X \cdot W^{(1)})\cdot W^{(2)}=A^2\cdot X\cdot W^{(1)}\cdot W^{(2)} H(2)=A⋅H(1)⋅W(2)=A⋅(A⋅X⋅W(1))⋅W(2)=A2⋅X⋅W(1)⋅W(2)
W ( 2 ) W^{(2)} W(2)是GCN第二层的参数, A 2 A^{2} A2就是长度为2的所有元路径的重要程度(权重)的聚合,考虑到不同长度的元路径的重要性可能不同,所以 W l W^l Wl就发挥了这个作用,用来衡量长度为 l l l的元路径的重要性。然后把两层的输出融合,就得到最后模块的输出。
H = 1 2 ( H 1 + H 2 ) H= \frac{1}{2}(H^1+H^2) H=21(H1+H2)
如果想要学习所有长度小于 l l l的元路径,扩展到 l l l层GCN即可。
为什么不使用激活函数?一些思考
首先不使用激活函数的话网络的时空效率会变高,也回应了前面的第二个挑战,这也是文中给出来的解释。
还有不使用激活函数的话这个模块就变成了一个线性映射,所以达到了一个效果就是第 l l l层有邻接矩阵 A A A的 l l l次幂。如果邻居矩阵存储的是0和1,那么 ( A l ) u v (A^l)_{uv} (Al)uv代表的是顶点 u u u到顶点 v v v的长度为 l l l的路径数量。此时邻居矩阵 A u v A_{uv} Auv存储的是节点 u u u对于节点 v v v的重要程度,那么 ( A l ) u v (A^l)_{uv} (Al)uv代表的是所有顶点 u u u到顶点 v v v的长度为 l l l的路径权重的乘积的累加。
这篇关于论文笔记:Multiplex Heterogeneous Graph Convolutional Network的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






