本文主要是介绍【关于时间序列的ML】项目 1 :使用 Python 进行 Covid-19 病例 预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
使用 Python 进行 Covid-19 病例预测的机器学习项目
数据准备
数据可视化
使用 Python 预测未来 30 天的 Covid-19 病例
在本文中,我将向您介绍一个在接下来的 30 天内使用 Python 预测 Covid-19 病例的机器学习项目。这些类型的预测模型有助于准确预测流行病,这对于获取有关传染病可能传播和后果的信息至关重要。
政府和其他立法机构依靠这些机器学习预测模型和想法来提出新政策并评估应用政策的有效性。
使用 Python 进行 Covid-19 病例预测的机器学习项目
在接下来的 30 天内,我将通过导入必要的 Python 库和数据集来开始使用 Python 进行 Covid-19 病例预测的任务:
数据集1:
Kaggle: Your Home for Data Science
数据集2:
Kaggle: Your Home for Data Science
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as pxfrom fbprophet import Prophet
from sklearn.metrics import r2_scoreplt.style.use("ggplot")df0 = pd.read_csv("CONVENIENT_global_confirmed_cases.csv")
df1 = pd.read_csv("CONVENIENT_global_deaths.csv")数据准备
现在下一步是数据准备,我将通过组合上述数据集来简单地准备新数据,然后我们将可视化数据的地理图以查看我们将要使用的内容:
world = pd.DataFrame({"Country":[],"Cases":[]})
world["Country"] = df0.iloc[:,1:].columns
cases = []
for i in world["Country"]:cases.append(pd.to_numeric(df0[i][1:]).sum())
world["Cases"]=casescountry_list=list(world["Country"].values)
idx = 0
for i in country_list:sayac = 0for j in i:if j==".":i = i[:sayac]country_list[idx]=ielif j=="(":i = i[:sayac-1]country_list[idx]=ielse:sayac += 1idx += 1
world["Country"]=country_list
world = world.groupby("Country")["Cases"].sum().reset_index()
world.head()
continent=pd.read_csv("continents2.csv")
continent["name"]=continent["name"].str.upper()| Country | Cases | |
|---|---|---|
| 0 | Afghanistan | 45716.0 |
| 1 | Albania | 35600.0 |
| 2 | Algeria | 79110.0 |
| 3 | Andorra | 6534.0 |
| 4 | Angola | 14920.0 |
数据可视化
现在在这里我将准备三个可视化。一个将是地理可视化,以可视化 Covid-19 的全球传播。那么下一个可视化将是查看世界上每天发生的 Covid-19 病例。然后最后一个可视化将是查看世界上每天 Covid-19 的死亡病例。
现在让我们通过查看 Covid-19 的全球传播情况来开始数据可视化:
world["Cases Range"]=pd.cut(world["Cases"],[-150000,50000,200000,800000,1500000,15000000],labels=["U50K","50Kto200K","200Kto800K","800Kto1.5M","1.5M+"])
alpha =[]
for i in world["Country"].str.upper().values:if i == "BRUNEI":i="BRUNEI DARUSSALAM"elif i=="US":i="UNITED STATES" if len(continent[continent["name"]==i]["alpha-3"].values)==0:alpha.append(np.nan)else:alpha.append(continent[continent["name"]==i]["alpha-3"].values[0])
world["Alpha3"]=alphafig = px.choropleth(world.dropna(),locations="Alpha3",color="Cases Range",projection="mercator",color_discrete_sequence=["white","khaki","yellow","orange","red"])
fig.update_geos(fitbounds="locations", visible=False)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()
现在让我们看看世界各地的日常案例:
count = []
for i in range(1,len(df0)):count.append(sum(pd.to_numeric(df0.iloc[i,1:].values)))df = pd.DataFrame()
df["Date"] = df0["Country/Region"][1:]
df["Cases"] = count
df=df.set_index("Date")count = []
for i in range(1,len(df1)):count.append(sum(pd.to_numeric(df1.iloc[i,1:].values)))df["Deaths"] = countdf.Cases.plot(title="Daily Covid19 Cases in World",marker=".",figsize=(10,5),label="daily cases")
df.Cases.rolling(window=5).mean().plot(figsize=(10,5),label="MA5")
plt.ylabel("Cases")
plt.legend()
plt.show() 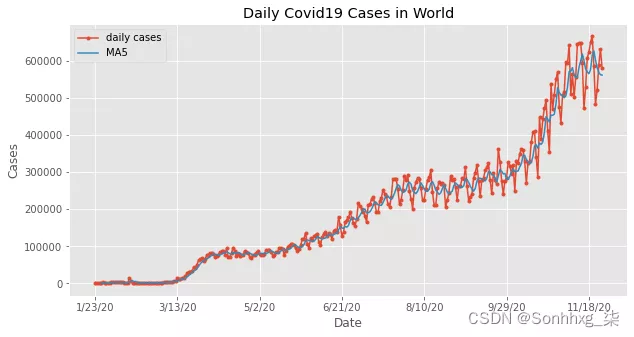
现在让我们来看看 Covid-19 的每日死亡病例:
df.Deaths.plot(title="Daily Covid19 Deaths in World",marker=".",figsize=(10,5),label="daily deaths")
df.Deaths.rolling(window=5).mean().plot(figsize=(10,5),label="MA5")
plt.ylabel("Deaths")
plt.legend()
plt.show() 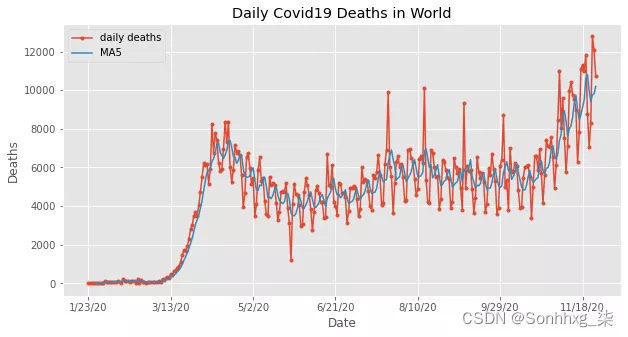
使用 Python 预测未来 30 天的 Covid-19 病例
现在,我将使用 Facebook 先知模型在接下来的 30 天内使用 Python 进行 Covid-19 病例预测任务。Facebook 先知模型使用时间序列方法进行预测。
让我们看看我们如何在接下来的 30 天内使用 Facebook 先知模型通过 Python 进行 Covid-19 病例预测:
class Fbprophet(object):def fit(self,data):self.data = dataself.model = Prophet(weekly_seasonality=True,daily_seasonality=False,yearly_seasonality=False)self.model.fit(self.data)def forecast(self,periods,freq):self.future = self.model.make_future_dataframe(periods=periods,freq=freq)self.df_forecast = self.model.predict(self.future)def plot(self,xlabel="Years",ylabel="Values"):self.model.plot(self.df_forecast,xlabel=xlabel,ylabel=ylabel,figsize=(9,4))self.model.plot_components(self.df_forecast,figsize=(9,6))def R2(self):return r2_score(self.data.y, self.df_forecast.yhat[:len(df)])df_fb = pd.DataFrame({"ds":[],"y":[]})
df_fb["ds"] = pd.to_datetime(df.index)
df_fb["y"] = df.iloc[:,0].valuesmodel = Fbprophet()
model.fit(df_fb)
model.forecast(30,"D")
model.R2()forecast = model.df_forecast[["ds","yhat_lower","yhat_upper","yhat"]].tail(30).reset_index().set_index("ds").drop("index",axis=1)
forecast["yhat"].plot(marker=".",figsize=(10,5))
plt.fill_between(x=forecast.index, y1=forecast["yhat_lower"], y2=forecast["yhat_upper"],color="gray")
plt.legend(["forecast","Bound"],loc="upper left")
plt.title("Forecasting of Next 30 Days Cases")
plt.show() 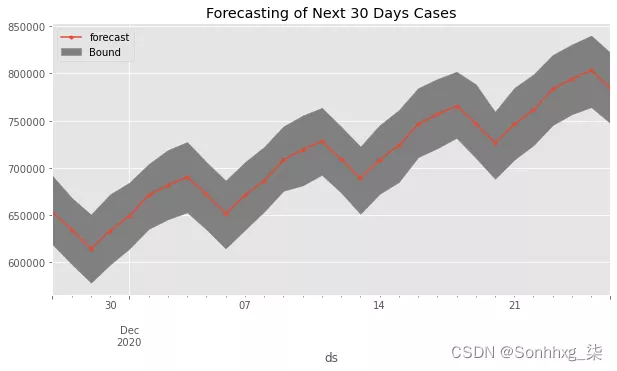
我希望您喜欢这篇关于使用 Python 编程语言预测未来 30 天 Covid-19 病例的文章。请随时在下面的评论部分提出您宝贵的问题。
这篇关于【关于时间序列的ML】项目 1 :使用 Python 进行 Covid-19 病例 预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






