本文主要是介绍【XMU学科实践二】豆瓣爬虫实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 分析豆瓣阅读网站
- 具体步骤
- 构造headers
- Beautiful soup中的定位函数find() 、find_all()
- 完整爬虫代码
叠甲:仅供学习。。
XMU的小朋友实在不会了可以参考我的思路,但还是建议自己敲一遍哈。
学科实践二还是挺有意思的!
分析豆瓣阅读网站
豆瓣阅读出版页面

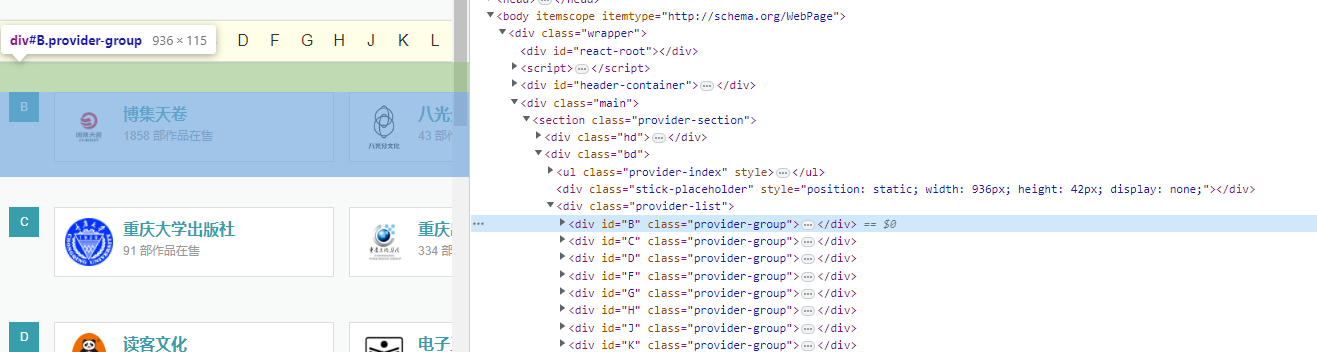
request模块:
requests是python实现的简单易用的HTTP库,官网地址:http://cn.python-requests.org/zh_CN/latest/
requests.get(url)可以发送一个http get请求,返回服务器响应内容。
BeautifulSoup库:
BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库。网址:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml
BeautifulSoup(markup, “html.parser”)或者BeautifulSoup(markup, “lxml”),推荐使用lxml作为解析器,因为效率更高。
具体步骤
构造headers
Request Headers 请求头参数; 客户端请求服务端时,会发送Request Headers即请求头给服务端
user-agent 用户代理,服务器从此处知道客户端的操作系统类型和版本,电脑CPU类型,浏览器 种类版本,浏览器渲染引擎,等等。这是爬虫当中最最重要的一个请求头参数,所以一定要伪造,甚⾄至多个。如果不进行伪造,而直接使用各种爬虫框架中自定义的user-agent,很容易被封禁。
url:爬取的地址

response = requests.get(url,headers=headers)
requests.get():通过URL去向服务器发出请求,服务器再把相关内容封装成一个Response对象返回
Response对象下有四个常用的方法(status_code、content、text、encoding)
Beautiful soup中的定位函数find() 、find_all()
网页中有用的信息通常存在于网页的文本或各种不同标签的属性值,为了获取这些网页信息,需要一些查找方法获取这些文本值或标签属性,BeautifulSoup内置了一些查找方法
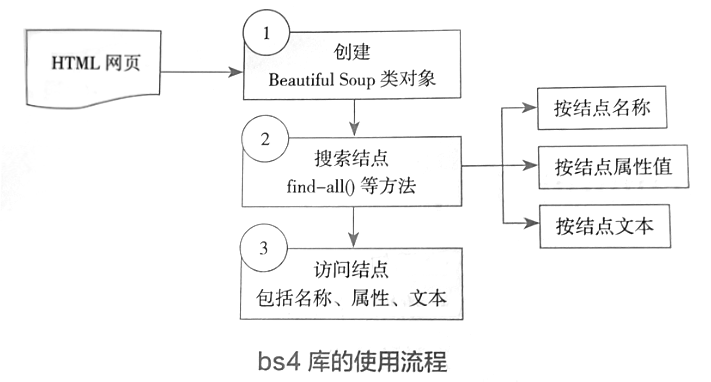
(1) find()方法:用于查找符合查询条件的第一 个标签节点。
(2) find_all()方法:查找所有符合查询条件的标签节点,并返回一个列表。
BeautifulSoup用法详解
完整爬虫代码
我23年3月的时候,是把豆瓣全部爬取了()一共5w6k条
import sys
import numpy as np
sys.path.append('/home/aistudio/external-libraries')
import json
import re
import requests
import pandas as pd
import datetime
from bs4 import BeautifulSoup
import base64
import os
import random
import time
#代理池
proxy_list = ['127.0.0.1:15732','192.168.56.1.15732'
]
proxy = random.choice(proxy_list)
proxies = {
'http': proxy,
'https': proxy,
}
user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER','Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0']
headers = { 'User-Agent': random.choice(user_agents),
}
url='https://read.douban.com/provider/all'
cookie={'cookie':'bid=kRRUP5Adrsc; _ga=GA1.3.1583431493.1679359048; _gid=GA1.3.240421151.1679359048; _ga=GA1.1.1583431493.1679359048; page_style="mobile"; dbcl2="215291240:+lGgZ069L0g"; _pk_ses.100001.a7dd=*; ck=AT7V; _ga_RXNMP372GL=GS1.1.1679406549.4.1.1679408190.60.0.0; _pk_id.100001.a7dd=0f38c905a23f4f70.1679359049.4.1679408190.1679402067.; _gat=1'}
try:response = requests.get(url,headers=headers,cookies=cookie,proxies=proxies)#将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象, 可以传入一段字符串soup = BeautifulSoup(response.text,'lxml') #返回所有的<div>所有标签publishes = soup.find_all('div',{'class':'provider-group'})pbs=[]item_list=[]#print(publishes)#enumerate爬虫中的遍历#遍历所有出版社#pb为当前出版社for index,pb in enumerate(publishes):#if (index<=1):if True:pb_list={}pb_list['item_name']=pb.find_next('div').textp=pb.find_next('ul')li_s=p.find_all('li')#li_s存储了当前出版社的所有数据。#print(li_s)for li in li_s:item_li={}#item_li为进入当前出版社内页书单的链接item_li['href']='https://read.douban.com'+li.find_next('a').get('href')url2=item_li['href']response2=requests.get(url2,headers=headers,cookies=cookie,proxies=proxies)soup2 = BeautifulSoup(response2.text,'lxml') #遍历当前出版社的所有书单页面while soup2.find('li',class_='next')!=None:#booklist为当前页面的所有<div class=info>的书籍数据booklist=soup2.find_all('div',{'class':'info'})#print(booklist)#print(publishes2)#遍历当前页面的所有书籍#book为当前的书籍数据for book in booklist:if(book.find('h4',class_='title')==None):continuetitle =book.find('h4',class_='title').textitem_li['name']=titleif(book.find('div',class_='sales-price')!=None):price=book.find('div',class_='sales-price').textitem_li['price']=priceelif(book.find('span',class_='discount-price')!=None):price=book.find('span',class_='discount-price').textitem_li['price']=priceelif(book.find('span',class_='price-tag')!=None):price=book.find('span',class_='price-tag').textitem_li['price']=priceelse:continue#输出查看print(f"《{title}》:{price}")#1000行截断,保存成xlsx比较好#item_list用来存储要求得的书名和价格的list型数据结构,一维item_list.append([title,price])t = random.random() #随机大于0 且小于1 之间的小数time.sleep(t)temp2=soup2.find('li',class_='next')#若存在后页if temp2.find('a')!=None:#跳转到下一页url3=url2+temp2.find('a').get('href')response2=requests.get(url3,headers=headers,cookies=cookie,proxies=proxies)soup2 = BeautifulSoup(response2.text,'lxml') else:break df=pd.DataFrame(item_list)df.columns=['书籍名称','价格']print(df)#保存到excel文件中df.to_excel("爬虫数据.xlsx")
except Exception as e:print(e)
这篇关于【XMU学科实践二】豆瓣爬虫实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



