xmu专题
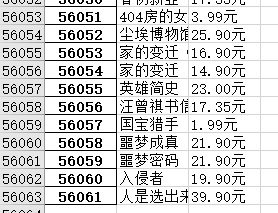
【XMU学科实践二】豆瓣爬虫实践
文章目录 分析豆瓣阅读网站具体步骤构造headersBeautiful soup中的定位函数find() 、find_all() 完整爬虫代码 叠甲:仅供学习。。 XMU的小朋友实在不会了可以参考我的思路,但还是建议自己敲一遍哈。 学科实践二还是挺有意思的! 分析豆瓣阅读网站 豆瓣阅读出版页面 request模块: requests是python实现的简单易