本文主要是介绍头疼!百万级 MySQL 的数据量,如何快速完成数据迁移?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

背景
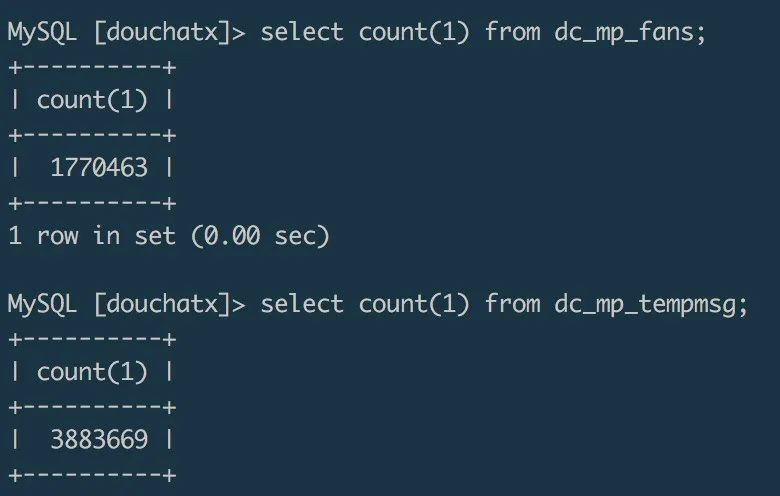
上个月跟朋友一起做了个微信小程序,趁着5.20节日的热度,两个礼拜内迅速积累了一百多万用户,我们在小程序页面增加了收集formid的埋点,用于给微信用户发送模板消息通知。
这个小程序一开始的后端逻辑是用douchat框架写的,使用框架自带的dc_mp_fans表存储微信端授权登录的用户信息,使用dc_mp_tempmsg表存储formid。截止到目前,收集到的数据超过380万,很大一部分formid都已经成功使用给用户发送过模板通知,起到了较好的二次推广的效果。
随着数据量的增大,之前使用的服务器空间开始有点不够用,最近新写了一个专门用于做小程序后台开发的框架,于是想把原来的数据迁移到新系统的数据库。买了一台4核8G的机器,开始做数据迁移。下面对迁移过程做一个简单的记录。
方案选择
mysqldump迁移
平常开发中,我们比较经常使用的数据备份迁移方式是用mysqldump工具导出一个sql文件,再在新数据库中导入sql来完成数据迁移。试验发现,通过mysqldump导出百万级量的数据库成一个sql文件,大概耗时几分钟,导出的sql文件大小在1G左右,然后再把这个1G的sql文件通过scp命令复制到另一台服务器,大概也需要耗时几分钟。在新服务器的数据库中通过source命令来导入数据,我跑了一晚上都没有把数据导入进来,cpu跑满。
脚本迁移
直接通过命令行操作数据库进行数据的导出和导入是比较便捷的方式,但是数据量较大的情况下往往会比较耗时,对服务器性能要求也比较高。如果对数据迁移时间要求不是很高,可以尝试写脚本来迁移数据。虽然没有实际尝试,但是我想过大概有两种脚本方案。
第一种方式,在迁移目标服务器跑一个迁移脚本,远程连接源数据服务器的数据库,通过设置查询条件,分块读取源数据,并在读取完之后写入目标数据库。这种迁移方式效率可能会比较低,数据导出和导入相当于是一个同步的过程,需要等到读取完了才能写入。如果查询条件设计得合理,也可以通过多线程的方式启动多个迁移脚本,达到并行迁移的效果。
第二种方式,可以结合redis搭建一个“生产+消费”的迁移方案。源数据服务器可以作为数据生产者,在源数据服务器上跑一个多线程脚本,并行读取数据库里面的数据,并把数据写入到redis队列。目标服务器作为一个消费者,在目标服务器上也跑一个多线程脚本,远程连接redis,并行读取redis队列里面的数据,并把读取到的数据写入到目标数据库。这种方式相对于第一种方式,是一种异步方案,数据导入和数据导出可以同时进行,通过redis做数据的中转站,效率会有较大的提升。
可以使用go语言来写迁移脚本,利用其原生的并发特性,可以达到并行迁移数据的目的,提升迁移效率。
文件迁移
第一种迁移方案效率太低,第二种迁移方案编码代价较高,通过对比和在网上找的资料分析,我最终选择了通过mysql的select data into outfile file.txt、load data infile file.txt into table的命令,以导入导出文件的形式完成了百万级数据的迁移。
迁移过程
在源数据库中导出数据文件
select * from dc_mp_fans into outfile '/data/fans.txt';
复制数据文件到目标服务器
zip fans.zip /data/fans.txtscp fans.zip root@ip:/data/
在目标数据库导入文件
unzip /data/fans.zip
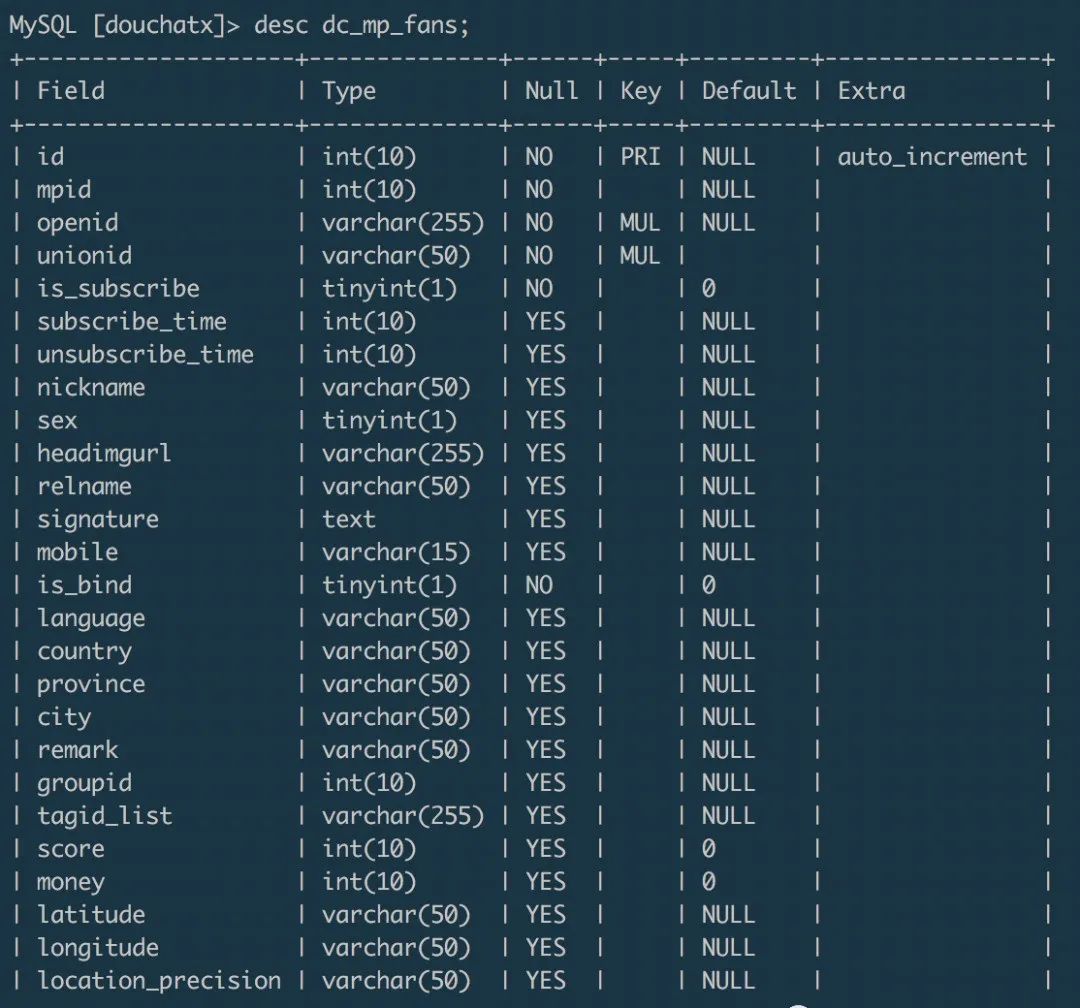
load data infile '/data/fans.txt' into table wxa_fans(id,appid,openid,unionid,@dummy,created_at,@dummy,nickname,gender,avatar_url,@dummy,@dummy,@dummy,@dummy,language,country,province,city,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy);
按照这么几个步骤操作,几分钟内就完成了一个百万级数据表的跨服务器迁移工作。
注意项
mysql安全项设置
在mysql执行load data infile和into outfile命令都需要在mysql开启了secure_file_priv选项, 可以通过show global variables like '%secure%';查看mysql是否开启了此选项,默认值Null标识不允许执行导入导出命令。通过vim /etc/my.cnf修改mysql配置项,将secure_file_priv的值设置为空:
[mysqld] secure_file_priv=''
则可通过命令导入导出数据文件。
导入导出的数据表字段不对应
上面示例的从源数据库的dc_mp_fans表迁移数据到目标数据库的wxa_fans表,两个数据表的字段分别为:- dc_mp_fans
wxa_fans
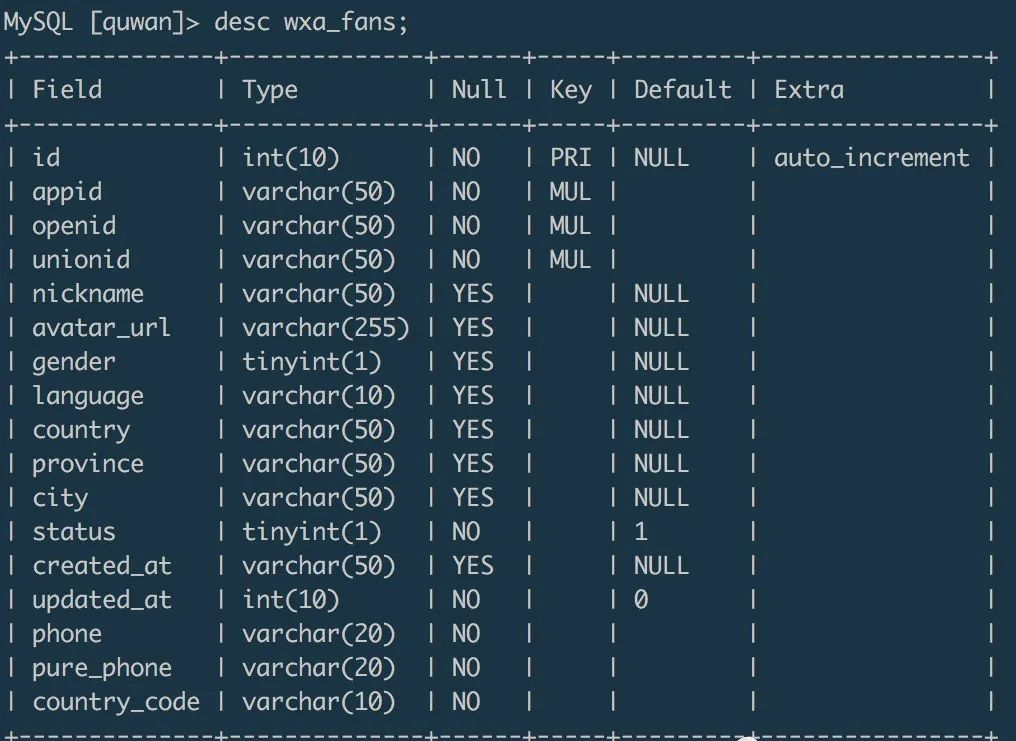
在导入数据的时候,可以通过设置字段名来匹配目标字段的数据,可以通过@dummy丢弃掉不需要的目标字段数据。
总结
结合本次数据迁移经历,总结起来就是:小数据量可以使用mysqldump命令进行导入导出,这种方式简单便捷。- 数据量较大,且有足够的迁移耐心时,可以选择自己写脚本,选择合适的并行方案迁移数据,这种方式编码成本较高。- 数据量较大,且希望能在短时间内完成数据迁移时,可以通过mysql导入导出文件的方式来迁移,这种方式效率较高。
来源:idoubi.cc/2018/06/30/mysql-data-migration
这篇关于头疼!百万级 MySQL 的数据量,如何快速完成数据迁移?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








