本文主要是介绍HDFS的全量块汇报以及Hadoop在2.x版本提供的限流优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
HDFS的全量块汇报以及Hadoop在2.x版本提供的限流优化
问题背景
在DataNode与NameNode的交互中,有大量的数据得不到处理,使得DataNode的增量块汇报不能及时处理,文件出现不能正常关闭等现象。在DataNode与NameNode的交互中,有三种形式,心跳报告,增量快汇报,全量块汇报。其中处理全量块汇报需要的时间和资源是其他汇报的数倍,且全量块汇报不需要立即处理,在HDFS中减少全量块汇报,使得系统有更多的资源去处理增量块汇报。
全量块汇报的流程
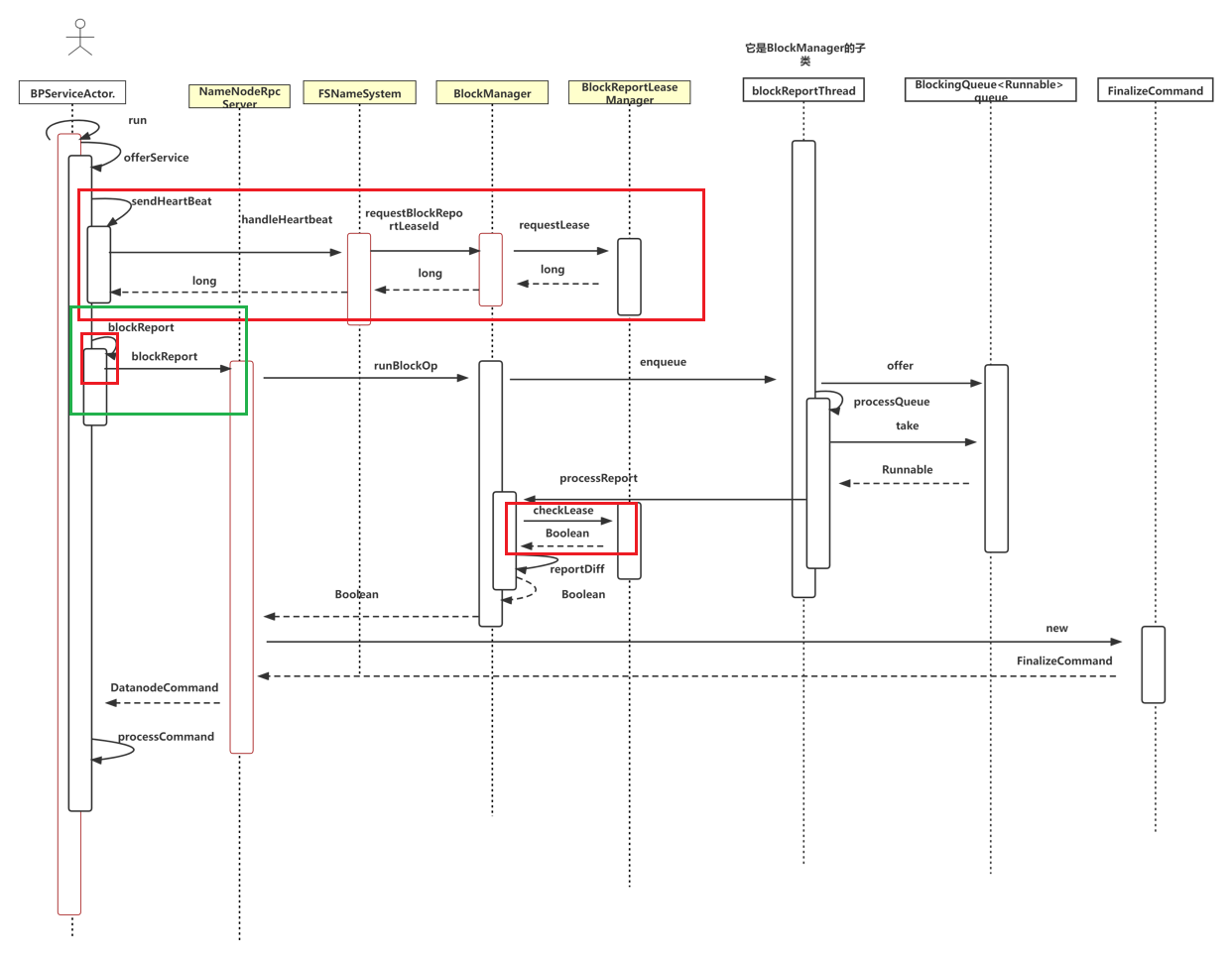
集群中可能存在多个NameNode,DataNode端的单个BPServiceActor负责DataNode与单个NameNode的RPC交互,每个BPServiceActor的实例都是一个独立运行的线程, 在线程的run方法中,调用了offerService方法,以负责日常的rpc汇报,定期向Namenode发送心跳、 增量块汇报、 全量块汇报以及缓存块汇报。我们本次只讨论全量块汇报。
上图中用颜色标出来的是优化部分,后节再进行讲解。
全量块汇报在NameNode端的处理流程
在DataNode端,调用blockReport方法将全量块汇报给NameNode。NameNode端并没有直接处理请求,而是将请求包装成线程放入到特定的阻塞队列中,交给BlockManager的子类blockReportThread来处理,从名字可以看出来,它是一个线程类,专门处理DataNode的汇报请求,它的任务就是将请求放入队尾,将队首的请求拿出进行处理。
因为在NameNode中是单一锁,也就是内部只有一个锁。NameNode需要根据全量块汇报,来调整内部的数据,所以是写锁。每次从队列取出进行处理时,需要先占用写锁,处理完再释放写锁。
NameNodeRpcServer. blockReport方法中,将请求包装成线程放入到队列中,实际的执行方法是BlockManager.processReport方法。
for (int r = 0; r < reports.length; r++) {final BlockListAsLongs blocks = reports[r].getBlocks();//// BlockManager.processReport accumulates information of prior calls// for the same node and storage, so the value returned by the last// call of this loop is the final updated value for noStaleStorage.//final int index = r;noStaleStorages = bm.runBlockOp(new Callable<Boolean>() {@Overridepublic Boolean call() throws IOException {return bm.processReport(nodeReg, reports[index].getStorage(),blocks, context, (index == reports.length -。 1));}});}
BlockManager.blockReportThread. processQueue 方法,使用写锁从队列中取出请求进行处理,保证一致性。
private void processQueue() {while (namesystem.isRunning()) {try {Runnable action = queue.take();// batch as many operations in the write lock until the queue// runs dry, or the max lock hold is reached.namesystem.writeLock();try {do {action.run();action = queue.poll();} while (action != null);} finally {namesystem.writeUnlock();}} }}
全量块汇报在NameNode端的实际处理
实际处理是调用BlockManager.processReport方法来处理全量块汇报。
对于Datanode周期性的块汇报,processReport()方法会调用私有的processReport()方法处理。这个方法会调用reportDiff()方法,将块汇报中的副本与当前NameNode内存中记录的副本状态做对比,然后产生5个操作队列。
- toAdd–上报副本与NameNode内存中的记录的数据块有相同的时间戳以及长度,那么将上报副本添加到toAdd队列中。对于toAdd队列中的元素,调用addStoredBlock()方法将副本添加到NameNode内存中。
- toRemove–副本在NameNode内存中的DatanodeStorageInfo对象上存在,但是块汇报时并没有上报该副本,那么将副本添加到toRemove队列中。对于toRemove队列中的元素,调用removeStoredBlock()方法将数据块从NameNode内存中删除。
- toInvalidate–BlockManager的blocksMap字段中没有保存上报副本的信息,那么将上报副本添加到toInvalidate队列中。对于toInvalidate队列中的元素,调用addToInvalidates()方法将该副本加入BlockManager.invalidateBlocks队列中,然后触发Datanode节点删除该副本。
- toCorrupt–上报副本的时间戳或者文件长度不正常,那么将上报副本添加到corruptReplicas队列中。对于corruptReplicas队列中的元素,调用markBlockAsCorrupt()方法处理。
- toUC–如果上报副本对应的数据块处于构建状态,则调用addStoredBlockUnderConstruction()方法构造一个ReplicateUnderConstruction对象,然后将该对象添加到数据块对应的BlockInfoUnderConstruction对象的replicas队列中。
BlockManager.processReport方法
private Collection<Block> processReport(final DatanodeStorageInfo storageInfo,final BlockListAsLongs report) throws IOException {// Normal case:// Modify the (block-->datanode) map, according to the difference// between the old and new block report.Collection<BlockInfoContiguous> toAdd = new LinkedList<BlockInfoContiguous>();Collection<Block> toRemove = new TreeSet<Block>();Collection<Block> toInvalidate = new LinkedList<Block>();Collection<BlockToMarkCorrupt> toCorrupt = new LinkedList<BlockToMarkCorrupt>();Collection<StatefulBlockInfo> toUC = new LinkedList<StatefulBlockInfo>();reportDiff(storageInfo, report,toAdd, toRemove, toInvalidate, toCorrupt, toUC);DatanodeDescriptor node = storageInfo.getDatanodeDescriptor();// Process the blocks on each queuefor (StatefulBlockInfo b : toUC) { addStoredBlockUnderConstruction(b, storageInfo);}...for (BlockToMarkCorrupt b : toCorrupt) {markBlockAsCorrupt(b, storageInfo, node);}return toInvalidate;}
全量块汇报DataNode端的后续处理
NameNode端处理汇报,会给DataNode返回DatanodeCommand, DataNode使用processCommand方法来根据DatanodeCommand进行相应的处理。
DatanodeCommand是datanode向namenode发送心跳、报告块后会返回的结构,datanode会对收到的命令进行相应的操作,该结构的主要属性是action,是命令对应的操作,这些操作在DatanodeProtocol中定义:
DNA_UNKNOWN = 0:未知操作
DNA_TRANSFER = 1:传输块到另一个datanode,创建DataTransfer来传输每个块,请求的类型是OP_WRITE_BLOCK,使用BlockSender来发送块和元数据文件,不对块进行校验
DNA_INVALIDATE = 2:不合法的块,将所有块删除
DNA_SHUTDOWN = 3:停止datanode,停止infoServer、DataXceiverServer、DataBlockScanner和处理线程,将存储目录解锁,DataBlockScanner结束可能需要等待1小时
DNA_REGISTER = 4:重新注册
DNA_FINALIZE = 5:完成前一次更新 ,调用DataStorage的finalizeUpgrade方法完成
DNA_RECOVERBLOCK = 6:请求块恢复,创建线程来恢复块,每个线程服务一个块,对于每个块,调用recoverBlock来恢复块信息
全量块汇报的action是DNA_FINALIZE = 5,即调用DataStorage的finalizeUpgrade方法完成数据的更新(具体逻辑后续补充),删除上次集群更新过程中所做的备份。
BPServiceActor.offerService方法
private void offerService() throws Exception {while (shouldRun()) {List<DatanodeCommand> cmds = null;cmds = blockReport(fullBlockReportLeaseId);processCommand(cmds == null ? null : cmds.toArray(new DatanodeCommand[cmds.size()]));} // while (shouldRun())} // offerService全量块拆分(HDFS-5153)
Hadoop社区在很早的时候就发现了这个问题,它提出的一个改进思路是:既然一整个大的FBR行为会造成很大的性能问题,那么我们是否可以将它拆分成多个小部分的块,并且分多次RPC进行发送呢?基于这个思路,社区在HDFS-5153: Datanode should send block reports for each storage in a separate message.实现了基于每个Storage的块汇报实现。在此优化下,当DataNode发现自身全量块汇报的总数大于阈值块汇报数(默认为100w)时,会将块按照每个Storage存储目录进行汇报,这样一个大的FBR RPC就变为了多次小的RPC行为。这样的话,远端NameNode处理DataNode的FBR压力会小许多。,相关逻辑代码如下:
List<DatanodeCommand> blockReport(long fullBrLeaseId) throws IOException {try {if (totalBlockCount < dnConf.blockReportSplitThreshold) {// Below split threshold, send all reports in a single message.DatanodeCommand cmd = bpNamenode.blockReport(bpRegistration, bpos.getBlockPoolId(), reports,new BlockReportContext(1, 0, reportId, fullBrLeaseId));numRPCs = 1;numReportsSent = reports.length;if (cmd != null) {cmds.add(cmd);}} else {// Send one block report per message.for (int r = 0; r < reports.length; r++) {StorageBlockReport singleReport[] = { reports[r] };DatanodeCommand cmd = bpNamenode.blockReport(bpRegistration, bpos.getBlockPoolId(), singleReport,new BlockReportContext(reports.length, r, reportId,fullBrLeaseId));numReportsSent++;numRPCs++;if (cmd != null) {cmds.add(cmd);}}}}
}
BR Lease的管理控制(HDFS-7923)
我们是否能在NameNode端做特殊处理,能够使得它避免长时间忙碌于FBR的处理之中呢?为此,社区在block report中引入了租约的概念来控制DataNode的全量块汇报行为,简称BR Lease。在BR Lease机制下,只有那些获得了NameNode所授予的BR Lease的DataNode节点,才能进行FBR行为。有了这层控制,NameNode就能够减缓底层大量DataNode所带来的FBR操作压力了。
就是我们新加了BlockReportLeaseManager类利用租约来控制DataNode来进行全量块汇报,使得NameNode同时只接收一定数量DataNode的全量块汇报,默认是6。
BlockReportLeaseManager负责有以下2类功能:
1 分配DataNode租约Id
2 处理块汇报前验证DataNode提供的租约Id是否有效BlockReportLeaseManager对DataNode的BR Lease做了额外两项的限制:
1 当前最多允许的Lease分配数,进而限制DataNode的FBR上报数,DataNode只有拿到Lease Id才能进行下一步的FBR。
2 每个Lease有其过期时间,过期时间设置是为了限制Lease的有效使用时间范围,借此避免DataNode长时间占用Lease。
BR Lease的使用流程
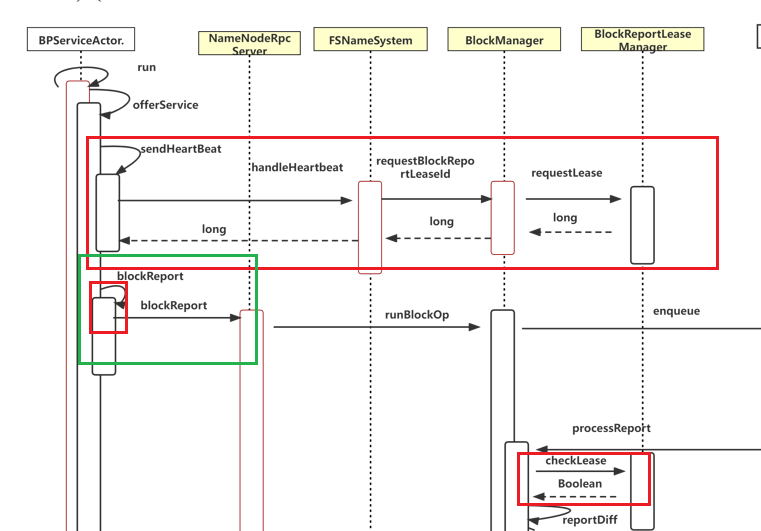
如上图所示,在DataNode进行心跳汇报的时候,会向NameNode请求全量块汇报的租约(BlockReportLease),直到调用BlockReportLeaseManager.requestLease方法来检查是否存放可以分发的租约,可以则分发租约,不可以则返回零。在DataNode接收到租约的ID,在下次进行全量块汇报时,先判断租约ID是否为零,不为零则进行全量块汇报。汇报后,BlockManager会在processReport方法中调用blockReportLeaseManager.checkLease来检查租约。
BPServiceActor.offerService方法
//心跳报告请求Lease IDlong fullBlockReportLeaseId = 0;if (sendHeartbeat) { boolean requestBlockReportLease = (fullBlockReportLeaseId == 0) &&scheduler.isBlockReportDue(startTime);resp = sendHeartBeat(requestBlockReportLease);assert resp != null;if (resp.getFullBlockReportLeaseId() != 0) {fullBlockReportLeaseId = resp.getFullBlockReportLeaseId();}}//Lease ID不为零,即ID有效,进行汇报if ((fullBlockReportLeaseId != 0) || forceFullBr) {cmds = blockReport(fullBlockReportLeaseId);fullBlockReportLeaseId = 0;}
BlockReportLeaseManager.requestLease
public synchronized long requestLease(DatanodeDescriptor dn) {NodeData node = nodes.get(dn.getDatanodeUuid());if (node == null) {node = registerNode(dn);//添加到map中去}remove(node);//在链表中进行移除if (numPending >= maxPending) {return 0;}numPending++;node.leaseId = getNextId();pendingHead.addToEnd(node);//添加到链表中return node.leaseId;}
BlockManager.processReport
public boolean processReport(final DatanodeID nodeID,final DatanodeStorage storage,final BlockListAsLongs newReport, BlockReportContext context,boolean lastStorageInRpc) throws IOException {if (context != null) {if (!blockReportLeaseManager.checkLease(node, startTime,context.getLeaseId())) {return false;}}}
BlockReportLeaseManager.checkLease
public synchronized boolean checkLease(DatanodeDescriptor dn,long monotonicNowMs, long id) {if (id == 0) {//强制访问return true;}NodeData node = nodes.get(dn.getDatanodeUuid());if (node == null) {LOG.info("BR lease 0x{} is not valid for unknown datanode {}",Long.toHexString(id), dn.getDatanodeUuid());return false;}if (node.leaseId == 0) {LOG.warn("BR lease 0x{} is not valid for DN {}, because the DN " +"is not in the pending set.",Long.toHexString(id), dn.getDatanodeUuid());return false;}if (id != node.leaseId) {LOG.warn("BR lease 0x{} is not valid for DN {}. Expected BR lease 0x{}.",Long.toHexString(id), dn.getDatanodeUuid(),Long.toHexString(node.leaseId));return false;}return true;}
Q&A
1在NameNode端为什么要将请求处理放入到队列中。
为了控制cpu的运行情况,放入到队列中,保证了每次cpu每次只允许一个请求处理运行,防止大量占用CPU。还减少了锁的争抢,因为HDFS内部是单一锁,将请求处理放入到队列中,一次只有一个请求处理占用锁,减少了锁的争抢。
借鉴于《深度剖析Hadoop HDFS》
这篇关于HDFS的全量块汇报以及Hadoop在2.x版本提供的限流优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



