本文主要是介绍论文阅读:Diffusion Model-Based Image Editing: A Survey,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Diffusion Model-Based Image Editing: A Survey
论文链接
GitHub仓库
摘要
这篇文章是一篇基于扩散模型(Diffusion Model)的图片编辑(image editing)方法综述。作者从多个方面对当前的方法进行分类和分析,包括学习策略、用户输入、和适用的任务等。为了进一步评估文本引导的图片编辑算法,作者提出了一个新的基准,EditEval,采用了一个创新的指标:LMM Score。最后,作者分析了当前方法的局限和未来可能的研究方向。
介绍
首先,什么是图片编辑?图片编辑是对输入的图片进行外观上、结构上或者内容上进行轻微乃至重大的修改的一类方法。
其次,什么是扩散模型?受平衡热力学启发,扩散模型逐渐向数据中添加噪声,然后学习从随机噪声开始反转这个过程,直至生成的数据符合源数据的分布。
扩散模型被广泛地应用于各个领域,包括图片生成、视频生成、图片修复和图片编辑。这篇文章对基于扩散模型的图片编辑方法做了综合的分析和总结。根据这些方法的学习策略、输入条件和一些列的编辑任务对它们进行分类。
从学习策略角度,分为三个主要的类别: 基于训练和的方法training-based approaches,测试-时间微调方法testing-time fine-tuning approaches,和无需训练微调方法training and finetuning free approaches。
从输入条件角度,分为10个不同的类别,包括文本text,掩码 mask,参考图片reference (Ref.) image, 类class,布局layout,姿态pose,草图 sketch,分割图segmentation (Seg.) map,音频 audio,和拖拽点dragging points。
从图片编辑任务方面,可以分为3个大类:语义编辑semantic editing, 风格编辑stylistic editing,和 结构编辑structural editing,覆盖了12个特定类别。
相关工作
Conditional Image Generation
不同于图片编辑,其修改现有的一张图片的部分,条件图片生成在特定条件的指引下,从头生成新的图片。早期的工作主要是class-conditioned image generation(条件为“类”的图片生成),后来的一些工作借助classifier-free guidance,可以支持更多的条件,比如文本条件。
Text-to-Image (T2I) Generation.
GLIDE是第一个条件图片生成扩散模型。类似的Imagen使用了级联框架在像素空间生成高分辨率图片。后续的工作LDM将像素空间替换为低维潜在空间,大大降低了计算开销,以此为基础的模型包括Stable Diffusion 1 & 2 & XL,DALL-E 2等。
Additional Conditions.
除了使用文本作为条件,还有一些工作使用其它输入条件,比如候选框grounding boxes,分割掩码segmentation masks,depth maps,normal maps, canny edges(边缘边), pose(姿态), 和sketches(草图)等。
Customized Image Generation.(定制化图片生成)
定制化图片生成和图片编辑的任务比较接近,其生成具有特定性质的图片,通常以具有相同主题的一些图片作为指引条件,代表工作有Textual Inversion [106] ,DreamBooth [107],和 DreamBooth [107]。
Image Restoration and Enhancement 图片修复与增强
Image restoration (IR)图片修复的目的是提高各种被污染退化的图片的质量。下面介绍一些基于扩散模型的图片修复工作。
Input Image as a Condition. 以输入图片作为条件的:super-resolution (SR) 和 deblurring [12], [13], [29], [118], [119]
**Restoration in Non-Spatial Spaces. ** 一些工作聚焦于其它空间,比如Refusion [63][120],WaveDM [67]和WaveDM [67]等。(没看懂和前面image input的区别)
T2I Prior Usage. 向预训练的文生图模型添加一些针对图片修复的层或者编码器,然后进行微调后,这些文生图模型也同样可以用于图片修复Image Restoration (IR)。
**Projection-Based Methods.**这些方法通过提取图片中内在的结构和纹理(textures)来完善生成的图片以保证数据的一致性。
Decomposition-Based Methods. 基于分解的方法 这些方法把图片修复看做一个线性反转的过程,代表工作包括Denoising Diffusion Restoration Models (DDRM) [66],Diffusion Null-space Model (DDNM) [68]等。
分类
不同于图片生成(image generation)从零生成一个新的图片,和图片修复与增强(image restoration and enhancement)致力于修复和提高退化了的图片的质量,图片编辑(imge editing)在外观appearance,结构structure,内容content, 包括
增加物体adding objects, 替换背景replacing backgrounds, 和修改纹理altering textures等多个方面修改图片。
根据学习的策略,扩散模型上的图片编辑方法可以分为3类:基于训练和的方法training-based approaches,测试-时间微调方法testing-time fine-tuning approaches,和无需训练微调方法training and finetuning free approaches。
从输入条件的角度,可以分为10个不同的类别,包括文本text,掩码 mask,参考图片reference (Ref.) image, 类class,布局layout,姿态pose,草图 sketch,分割图segmentation (Seg.) map,音频 audio,和拖拽点dragging points。
从图片编辑的任务方面,可以分为12个特定的编辑类别,并可以被分为3个大类:语义编辑semantic editing, 风格编辑stylistic editing,和结构编辑structural editing:
- 语义编辑Semantic Editing:该类任务修改图片的内容和叙述故事,影响图片描绘的故事场景、上下文和主题元素。其包括以下小类:物体增加object addition (Obj. Add.),物体移除object removal (Obj. Remo.),物体替换 object replacement (Obj.Repl.), 背景修改background change (Bg. Chg.) 和情绪表达修改emotional expression modification (Emo. Expr. Mod.)。
- 风格编辑Stylistic Editing:该类任务注重增强或者转换图片的视觉风格和审美元素而不修改其叙述内容。其包括如下小类:颜色修改color change (Color Chg.),纹理修改texture change (Text. Chg.)和 整体风格修改overall style change (Style Chg.)。
- Structural Editing:该类任务注重图片中的空间重安排spatial arrangement,布置positioning,角度viewpoints和元素特征characteristics of elements,强调场景中物体的组织和呈现。其包括如下的小类:物体移动object movement (Obj.
Move.),物体尺寸和性状改变object size and shape change (Obj. Size. Chg.),物体动作和姿态改变object action and pose change (Obj. Act. Chg.),和角度改变perspective/viewpoint change (Persp./View. Chg.)。
基于训练的方法TRAINING-BASED APPROACHES
作者将基于训练的方法,根据他们的应用领域、训练所需的条件、监督的类型分为4个主要的类别,如图2所示。此外,在每个主要类中,进一步根据它们核心的编辑策略将它们分为不同类型的方法。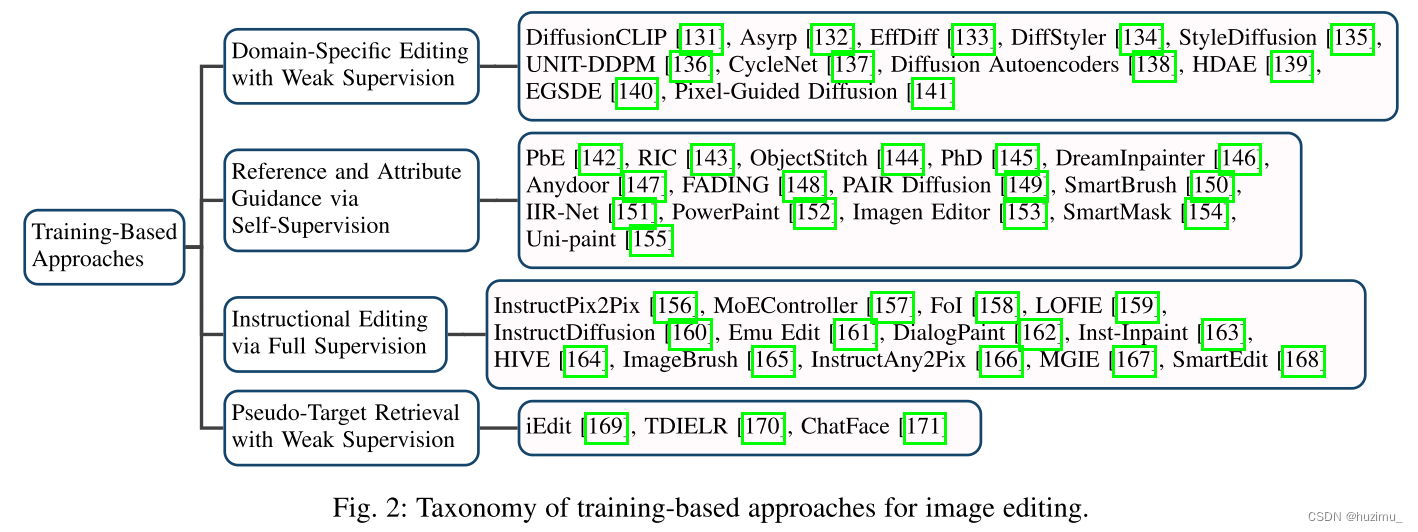
Domain-Specific Editing with Weak Supervision
基于扩散模型的一个挑战是其在大规模数据集上大量的计算开销。为了解决这个问题,一些早期的工作通过在小规模的专用数据集上的弱监督训练扩散模型。这些数据集高度专注于特定领域,比如用于人脸操纵的CelebA[236]和FFHQ [2],用于动物面部编辑和转换的AFHQ [237],用于物体修改的 LSUN [238]和用于风格转换的 WikiArt [239]。根据这些方法弱监督的类型,作者又将其分为4个类别。
CLIP Guidance. 一些方法使用CLIP引导使用文本作为条件的图片编辑。一个典型的代表是DiffusionCLIP [131],其允许在训练和新的数据上使用CLIP。具体来说,它首先将图片使用DDIM转化为latent noise,然后在反转扩散过程中微调预训练的扩散模型,以调整图片的属性,并使用一个源提示词和目的提示词之间的CIIP损失函数约束该过程。
循环正则化Cycling Regularization. 由于扩散模型能够进行域转换,因此循环框架也可以应用在扩散模型上。例如, UNIT-DDPM [136] 使用循环一致性来规范非配对图片-到-图像翻译的训练,在扩散模型中定义了一个双通道的马尔科夫链。
Projection and Interpolation. 该类方法将图片投影(projection),然后进行插值(interpolation)处理。例如,Diffusion Autoencoders[138]介绍了一个语义编码器来将输入图片匹配到一个语义嵌入,其作为扩散模型的条件用于重构。在训练语义编码器和条件生成模型之后,任何图片都可以被投影到这个语义空间用于插值。
Classifier Guidance. 一些方法引入了额外的预训练分类器来提高图片编辑的性能。比如, EGSDE [140]使用一个energy function 来引导真实的非配对图片-到-图片翻译的采样。
Reference and Attribute Guidance via Self-Supervision
该类方法通过自监督方式提取图片属性或者其他信息作为条件,用来训练基于扩散模型的图片编辑模型。这类方法可以被分为两个类别:reference-based image composition和attribute-controlled image editing。
Reference-Based Image Composition.
Attribute-Controlled Image Editing.
Instructional Editing via Full Supervision
Pseudo-Target Retrieval with Weak Supervision
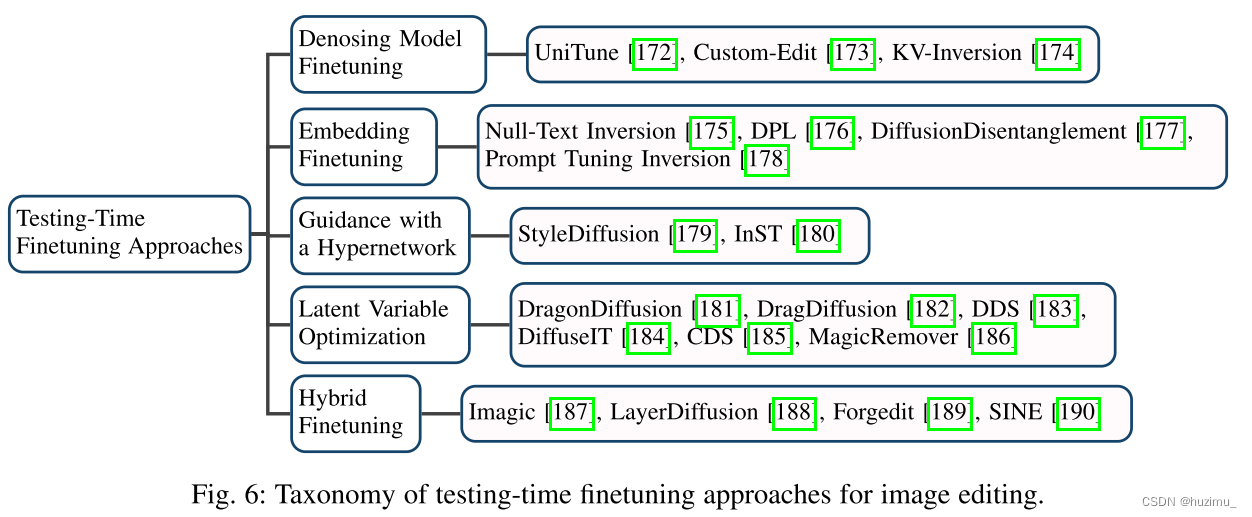
测试-时间微调方法TESTING-TIME FINETUNING APPROACHES
根据微调的部位和方式,又可以将该大类分为5个小类,如图6所示。
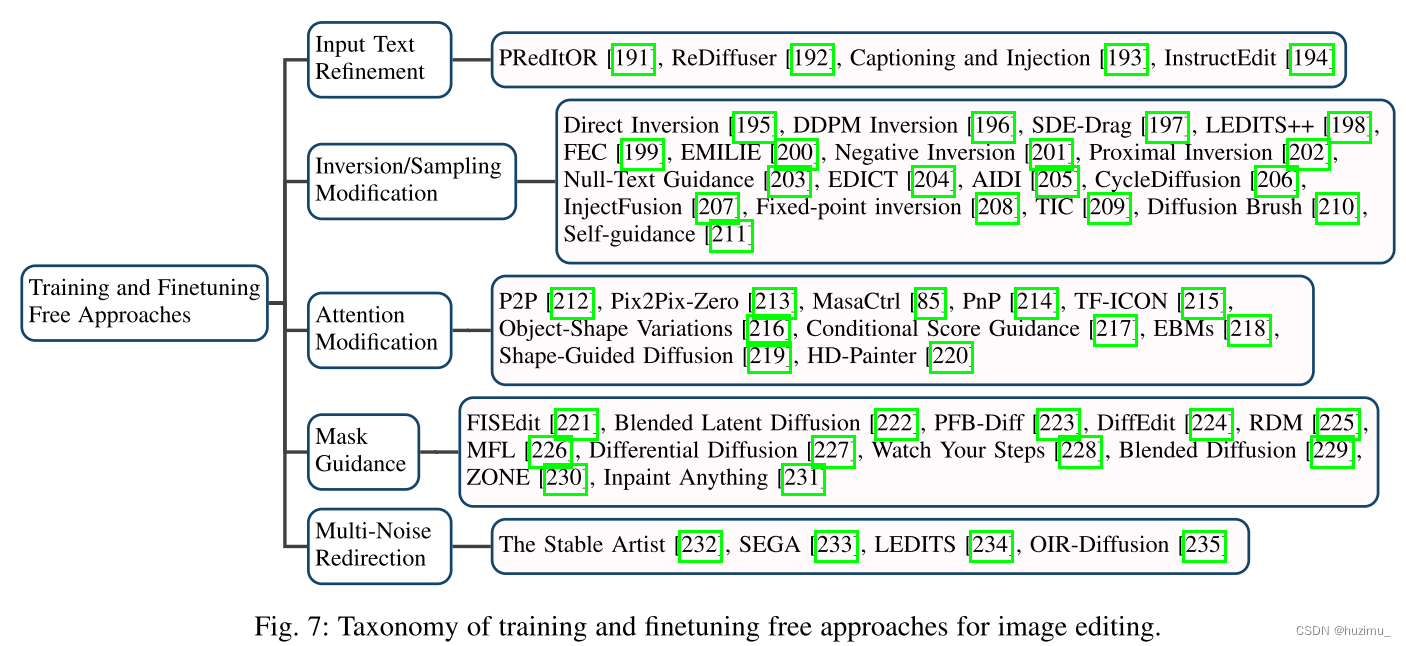
无需训练和微调的方法TRAINING AND FINETUNING FREE APPROACHES
该类方法在编辑的过程中无需训练喝微调,因此更为高效和低成本。根据这些方法具体修改的地方,可以将它们分为5个小类,如图7所示。(着重关注)
挑战和未来的研究方向CHALLENGES AND FUTURE DIRECTIONS
- Fewer-step Model Inference.
- Efficient Models.
- Complex Object Structure Editing.
- Complex Object Structure Editing.
- Unrobustness of Image Editing.
- Faithful Evaluation Metrics.
这篇关于论文阅读:Diffusion Model-Based Image Editing: A Survey的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









