本文主要是介绍基于SpringBoot的CNKI数据精炼与展示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目 录
摘 要 I
Abstract II
引 言 1
1 相关技术 3
1.1 SpringBoot框架 3
1.1.1 Spring框架介绍 3
1.1.2 SpringBoot框架介绍 3
1.2 MyBatis框架 4
1.3 Echarts框架 5
1.4 Bootstrap框架 5
1.5 JQuery技术 6
1.6 本章小结 6
2 系统分析 7
2.1 功能需求分析 7
2.1.1 门户模块需求分析 7
2.1.2 搜索研究模块需求分析 8
2.1.3 人群研究模块需求分析 9
2.1.4 需求研究模块需求分析 10
2.1.5 趋势研究模块需求分析 10
2.2 非功能需求 11
2.3 本章小结 12
3 系统设计 13
3.1 系统总体设计 13
3.1.1 系统体系结构 13
3.1.2 系统层次结构 13
3.1.3 系统目录结构 14
3.1.4 系统功能结构 15
3.2 系统详细设计 15
3.2.1 系统功能设计 15
3.2.2 数据库设计 17
3.3 本章小结 20
4 系统实现 21
4.1 开发环境 21
4.2 开发规范 21
4.3 数据库实现 21
4.4 SpringBoot项目搭建 21
4.5 功能实现 22
4.6 本章小结 28
5 系统测试 29
5.1 测试计划 29
5.2 用例测试 29
5.3 压力测试 30
5.4 本章小结 32
结 论 33
致 谢 34
参考文献 35
附录:源程序清单 37
摘 要
大数据时代的背景下,当人们面对海量数据的时候,仅凭文本传递与分析数据非常的低速、低效,而基于数据挖掘、理解数据基础上的数据可视化,成为叙事手段一个新的发展方向和突破。
目前在市场上暂未发现有对文献数据信息可视化方面的产品,唯一存在相似的就是知网自身的计量可视化分析系统,这对科研工作者开始一个新的研究,有非常大的帮助和意义,然而这套系统的功能还是不够全面,所展示出的数据图表较少。本文针对当前存在的此种迫切需求开发基于SpringBoot的CNKI数据精炼与展示系统,通过样式更美丽、功能更全面、用户体验更良好的图表展示出文献间的关系。
通过对数据可视化的业务流程调研,使用Java作为基础语言,使用SpringBoot+Mybatis构造系统架构,使用Echarts+Bootstrap作为视图层框架,使用MySQL作为数据库,在阿里云上布置Tomcat为服务器,开发并实现了基于SpringBoot的CNKI数据精炼与展示系统。本文采用的技术,使开发变得更敏捷,使系统更加高效、扩展性更好。通过系统性的开发编码,严密的用例、压力测试,基于SpringBoot的CNKI数据精炼与展示系统中各模块均已成功实现,并已投入使用。
关键词:Springboot; ECharts; 数据可视化
Abstract
Under the background of big data era, when people are faced with massive data, only text transfer and analysis data is very low-speed and inefficient, and data visualization based on data mining and understanding data has become a new development direction and breakthrough of narrative means.
At present, there is no product for the visualization of literature data information in the market. The only similarity is the measurement visualization analysis system of HowNet itself, which is of great help and significance for researchers to start a new research. However, the function of this system is not comprehensive enough, and the data charts displayed are few. In this paper, we develop a spring boot based CNKI data refining and display system for the current urgent needs, and show the relationship between documents through more beautiful style, more comprehensive function and better user experience.
Through the investigation of data visualization business process, using Java as the basic language, using springboot + mybatis to construct the system architecture, using echarts + bootstrap as the view layer framework, using MySQL as the database, and arranging Tomcat as the server on Alibaba cloud, the CNKI data refining and display system based on springboot is developed and implemented. The technology adopted in this paper makes the development more agile and makes the system more efficient and extensible. Through systematic development coding, rigorous use cases and stress testing, all modules of CNKI data refining and display system based on springboot have been successfully implemented and put into use.
Keywords: Springboot; ECharts; data visualizatio
引 言
大数据时代的到来,我们的生活产生数据,数据改变着我们的生活,数据可视化也应运而生[1],它通过样式更美丽、功能更全面、用户体验更良好的图表,为用户带来视觉盛宴的同时减低理解难度,实现用图表加数字的方式给用户讲故事的目的。
在国外,数据可视化已经发展了一段时间,他们使用数据可视化的方式进行发布信息,从而提高用户获取信息的体验。我国利用数据可视化的发展刚见起色。前些年,常借助于折线图、饼状图等形式来美化版面,并使用文字加图画的形式宣扬某一种信息[2]。近些年才开始使用旭日图、热力图等形式来优化信息图表,走上了数据可视化的发展道路。目前在市场上暂未发现有对文献数据信息可视化方面的产品,唯一存在相似的就是知网自身的计量可视化分析。然而这套系统的功能还是不够全面,所展示出的数据图表较少。本文针对当前存在的此种迫切需求开发基于SpringBoot的CNKI数据精炼与展示系统。
本系统拟采用JavaWeb技术进行设计,使用SpringBoot作为Java后台开发框架,使用Mybatis作为持久层框架对数据库操作进行了统一管理,并利用Mybatis官方提供的逆向工程方法生成entity层、dao层及xml文件,使用JQuery作为前端的脚本语言,使用Bootstrap作为CSS框架,使用Echarts作为可视化图表框架,将thymeleaf页面结合JQuery+Bootstrap+ Echarts以及Ajax完成页面相关功能,这些技术的结合使开发变得更加的敏捷,并且可以效的提高开发效率和降低耦合性,同时使用开源的MySql作为本系统的储存数据库,使用阿里云学生机作为服务器,解决方案丰富且开发成本低廉。
本系统采用分层模式,将整个系统分为五个层次:controller、dao、entity、service、view,并使每个层次进行分离,有利于对业务进行单独管理,为程序二次开发提供更多便利。本系统设计并完成七个模块:门户模块、搜索研究模块、需求研究模块、趋势研究模块、人群研究模块、系统自检模块、文献信息爬取模块。
本文的大致结构是:引言,描述本系统的选题背景和开发意义;第一章为相关技术,对开发此系统Java框架、持久层框架、页面技术、爬虫技术进行了综述;第二章为需求分析,通过对系统进行需求分析,综述了本系统所需要的开发环境和运行环境,以及需要完成的功能;第三章为系统设计,综述了系统体系结构、层次结构、功能结构、系统功能、数据库的设计;第四章为功能实现,综述了开发环境、开发规范、数据库实现、项目搭建、核心功能实现;第五章为系统测试,综述了用例测试及压力测试;最后对论文及系统做了总结。
1 相关技术
本系统使用Windows10的操作系统,Eclipse2017进行的开发。采用Bootstrap和ECharts技术来对界面进行主要的功能展示,使用Ajax来进行数据的交互访问,使用jQuery库提升用户体验。后台使用SpringBoot框架,使用MVC设计模式进行代码的编写[3],使用MySQL数据库来对海量数据进行存储。
1.1 SpringBoot框架
1.1.1 Spring框架介绍
Spring框架思想起源于2002年Rod Jahnson所著的书籍。并在《Expert One-on-One J2EE Development without EJB》书中更进一步阐述了在不使用EJB开发JavaEE企业级应用的一些设计思想和具体的做法。Spring的目的是解决EJB开发JavaEE的代码重复、配置复杂而单调、学习的艰苦、开发效率低的问题,为JavaBean提供了良好的配置框架,使JavaEE的开发变得简单且愉悦。
1.1.2 SpringBoot框架介绍
SpringBoot是于2014年4月由Pivotal团队开源的一种基于Spring的全新框架,它基于Spring4.0设计[4],在Spring框架原有的优秀特性上,基于“约定大于配置”的思想,大大简化了Spring应用程序各个方面的配置。在开发SpringBoot项目时只需要很少的配置,就可以创建一个稳定的、优秀的、产品级别的Spring应用,极大地提高了开发效率,并且可以添加更多的微服务,而不会互相影响[5]。
同时,SpringBoot框架还具有以下几个优点:
(1)SpringBoot提供了可以针对大多数Spring应用常用功能的相关配置。绝对没有代码生成,不需要XML配置。
(2)SpringBoot自带了Tomcat应用服务器,使项目的部署和管理都非常方便。
(3)SpringBoot提供编码预备功能,如指标、运行状况检查和外部化配置。
(4)SpringBoot提供了创新性的POM启动方式,大大简化Maven配置并且可以自动配置Spring。
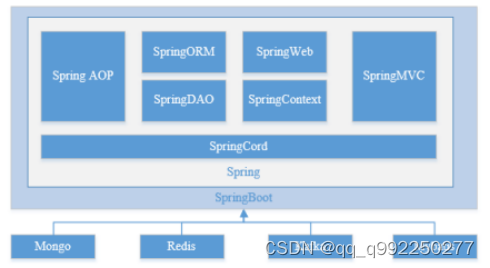
图1.1 SpringBoot框架示意图
1.2 MyBatis框架
在JavaEE程序开发过程中,程序对数据库的操作通常通过JDBC数据库连接技术实现。随着敏捷开发观点的提出、计算机技术的不断发展,开发人员对JDBC进行封装,形成基于Java的持久层框架Ibatis。
Ibatis在2001年由Clinton Begin发起的开放源代码项目,2016年6月被Google托管,Ibatis3.x正式改名为Mybatis3.x,之后一直沿用名称Mybatis。
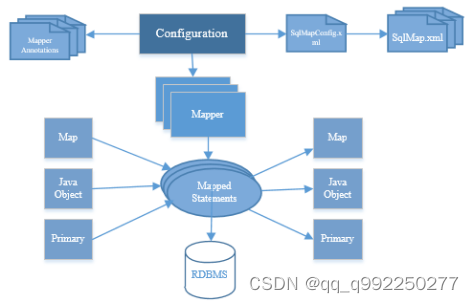
图1.2 Mybatis框架示意图
如图1.2所示,Mybatis框架具有以下几个特点:
(1)加载配置:配置文件和有些注解都可以改变Mybatis的配置参数,程序运行时Mybatis会将需要执行的SQL与入参出参配置信息,加载为MappedStatement,并将其放入内存中,以便调用。
(2)自动SQL解析:Mybatis会根据请求的参数及SQL语句id,找到相应的MappedStatement对象,并自动解析为所执行的SQL。
(3)SQL执行:将最终得到的SQL和参数拿到数据库进行执行,得到操作数据库的结果。
(4)结果映射:将数据库的结果按照所设的映射配置进行转换,转换为Java基本类型、JavaBean、HashMap等类型后将结果进行返回。
同时Mybatis框架还具有无第三方依赖,对SQL语句管理与优化更加方便,解除了应用程序代码和SQL语句的耦合[6],支持动态SQL编写,支持ORM字段关系维系,学习成本低等特点。
1.3 Echarts框架
Echarts最初有百度公司前端数据可视化团队EFE进行开发,开源后使得它得以快速发展,2013年6月发布后得到了业界高度关注和好评,虽然已经有了种类繁多的图表库,但Echarts具有颠覆性的功能设计和技术特征,使其迅速成为国内数据可视化领域的“后起之秀”。2017年又由Apache赞助,成为Apache开源基金会孵化的项目。
Echarts是基于Html5 Canvas类库,纯JavaScript语言的开源图表库,底层依赖于轻量级的Canvas类库ZRender,基于BSD开原协议,可以流畅的运行在手机端和电脑端[7],兼容性强大,能够提供直观、生动、可交互、可高度个性化定制的数据可视化图表[8]。
同时Echarts还具提供了常规统计的盒形图[9],可视化的地图、热力图、关系图、旭日图[10],提供了图例、视觉映射、数据区域缩放、tooltip、数据刷选等开箱即用的交互组件[11]。
1.4 Bootstrap框架
Bootstrap最初由Twitter公司的几个前端开发工作人员于2010年6月创建的工具包,2011年8月由Twitter公司将其开源,至今Bootstrap已发展到包括几十个组件,是一种精致的、经典的、得到充分认可的,并已成为最受欢迎的Web前端框架之一。
Bootstrap学习成本低,可以让所有开发者快速的上手开发,可以适配所有设备,可以流畅的运行在手机端和电脑端,兼容性强大。Bootstrap提供了一个带有链接样式、栅格系统、背景的基本结构[12],并且自带了全局CSS设置,自带了基本的HTML样式,
1.5 JQuery技术
jQuery库是一个快速、简洁的对浏览器兼容性较强的JavaScript库[13],jQuery的宗旨是用更少的代码,做更多的事情。jQuery对JavaScript进行封装,为使用者提供一种简便的解决方案,可以更方便的处理HTML,可以很轻易的将结构与行为分离。jQuery具有独特的链式语法和短小清晰的多功能接口,具有高效灵活的CSS选择器,并且可对CSS选择器进行扩展,拥有便捷的插件扩展机制和丰富的插件[14],jQuery能够修改dom节点为页面增加更多效果。
1.6 本章小结
本章主要介绍了基于SpringBoot的CNKI数据精炼与展示系统在开发过程中将会使用到的技术,后台开发框架使用SpringBoot,持久化框架使用Mybatis,使用JQuery作为前端的脚本语言,使用Bootstrap作为CSS框架,使用Echarts作为可视化图表框架。
2 系统分析
本章基于第一章介绍的相关技术,详细的描述了基于SpringBoot的CNKI数据精炼与展示系统的系统分析,分别从功能需求和非功能需求进行分析,用例图展示了用例之间的关系可以更加直观的展示基于SpringBoot的CNKI数据精炼与展示系统的功能需求。本章可用于指导本系统后续系统设计、项目开发和项目测试阶段的工作[15]。
2.1 功能需求分析
经过对现有系统常规功能的分析,确定基于SpringBoot的CNKI数据精炼与展示系统包括:门户模块、搜索研究、需求研究、趋势研究、人群研究。
2.1.1 门户模块需求分析
基于SpringBoot的CNKI数据精炼与展示系统门户模块起着网站首页与内容汇总的重要作用,通过对关键字的搜索,可以进入系统内部。具体包含展示搜索关键词功能、展示系统目的及意义功能、输入关键词搜索等功能,如图2.1所示。
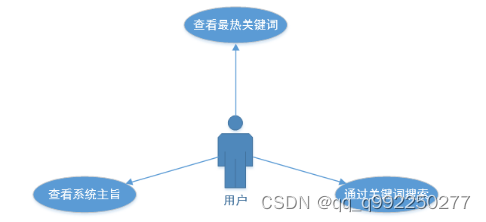
图2.1 门户模块用例图
展示最热搜索关键词。用户使用规定浏览器搜索链接,访问本系统时,浏览器会显示本系统的门户模块页面,页面右侧是展示搜索关键词功能,通过对所有用户近期的搜索、以及爬取到的文献关键词提取综合权值计算,展示出得分由高到低前三十的关键词,以2秒展示10个关键词的计划,对前三十的关键词进行循环展示。
查看系统主旨。用户使用规定浏览器搜索链接,访问本系统时,浏览器会显示本系统的门户模块页面,页面左下方是展示系统目的及意义区域,本系统试图通过分析数据展示出来的结果,可以为他人获得科研选题灵感,为科研课题提供研究思路等等。
键入关键词搜索功能。用户使用规定浏览器搜索链接,访问本系统时,浏览器会显示本系统的门户模块页面,页面左上方就是关键词搜索功能区域,用户输入自己期望搜索的关键词,进入系统内部,并且可以访问其他模块。
2.1.2 搜索研究模块需求分析
搜索研究模块主要功能是展示与搜索有关的的图表,包括所搜索关键词近七日搜索次数折线变化图、所有所关键词的搜索指数、搜索次数排行前十的关键词等功能,如图2.2所示。
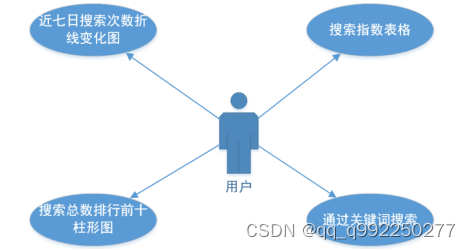
图2.2 搜索研究模块用例图
近七日搜索次数折线变化图展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入搜索研究模块页面,页面第一个图表就是近七日搜索次数折线变化图,用于展示所搜索关键词近七日的搜索次数变化情况和七日搜索次数平均值,还可以变为柱形图便于观察,并且可以将图表图片保存至本地。
搜索指数表格展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入搜索研究模块页面,页面第二个图表就是搜索指数表格区域,用于展示所搜索关键词搜索次数的周均值、月均值、周均同比、月均同比、总和。
搜索总数排行前十柱形图展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入搜索研究模块页面,页面第三个图表就是搜索总数排行前十柱形图区域,用于展示所有用户搜索总次数最多的前十个关键词。
2.1.3 人群研究模块需求分析
人群研究模块主要功能是展示搜索该关键词的人群信息图表,包括用户信息采集功能、用户地域分布地图功能、男女比例饼状图功能、年龄比例图表等功能,如图2.3所示。
图2.3 人群研究模块用例图
用户信息采集功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入人群研究模块页面,如未填写过年龄、性别信息,则会弹出该功能DIV,让用户填写信息,并将之前之后搜索的关键词填上对应的用户信息。
用户地域分布地图展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入人群研究模块页面,第一个图表就是用户地域分布地图区域,将所有搜索过该关键词的用户按照省份、直辖市划分,人数越多的省份颜色越深,并且可以人数多少筛选。
性别比例图展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入人群研究模块页面,第二个图表就是性别比例扇形图区域,用于显示所有搜索过该关键词的用户按照性别划分并显示,并且该图可与年龄比例图联动。
年龄比例图展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入人群研究模块页面,第三个图表就是年龄比例图区域,用于显示所有搜索过该关键词的用户按照年龄划分并显示,并且该图可与性别比例图联动。
2.1.4 需求研究模块需求分析
需求研究模块主要功能是展示所搜索关键词的需求信息图表,包括关键词相关字符云功能、关键词主题指数等功能,如图2.4所示。
图2.4 需求研究模块用例图
关键词相关字符云展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入需求研究模块页面,页面第一个图表就是关键词相关字符云区域,按照时间与相关性排序展示与关键词相关近期最热门的文献名称。
主题指数展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入需求研究模块页面,页面第一个图表就是关键词主题指数区域,展示主题占比(期刊)、主题占比(硕士)等。
2.1.5 趋势研究模块需求分析
趋势研究模块主要功能是展示整体文献信息的数据图表,包括展示整体数据功能、展示近20年文献发布数量功能、展示最热关键词文献数量统计(年)功能、展示近半年各类文献的发布量变化功能、展示文献发布量前十单位功能、每月文献发布量比例等功能,如图2.5所示。
图2.5 趋势研究模块用例图
整体数据展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入趋势研究模块页面,页面第一个图表就是整体数据展示区域,展示系统总文献数,展示用户搜索关键词总数,展示用户搜索总数。
近二十年文献发布量展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入趋势研究模块页面,页面第二个图表就是近二十年文献发布量展示区域,分为左边前十年半径图,数量越多半径越大,右边后十年面积图,数量越多面积越大。
最热关键词文献数量展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入趋势研究模块页面,页面第三个图表就是最热关键词文献数量统计面积图区域,根据最热门的前十个关键词统计相关文献,并用面积关系展示。
近半年各类文献的发布量变化展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入趋势研究模块页面,页面第四个图表就是近半年各类文献的发布量变化折线图区域,根据近半年每月各类文献发布量变化展示为期刊、博士、硕士论文堆积的折线变化图。
文献发布量前十单位展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入趋势研究模块页面,页面第四个图表就是文献发布量前十单位柱形图区域,根据所有文献发布单位发布的文献总数量排序,选出前十进行柱形图展示。
每月文献发布量比例展示功能。用户使用规定浏览器搜索链接,访问本系统,通过首页搜索关键词进入趋势研究模块页面,页面第四个图表就是每月文献发布量比例扇形图区域,根据所有文献的发布时间统计每月份发布的文献数量并使用扇形图展示。
2.2 非功能需求
非功能需求包括对服务器硬件和软件要求、客户端软件要求、访问容量以及响应时间。软件要求主要是指对相关操作系统、数据库服务器、Web服务器的要求。
非功能需求的满足程度,直接影响软件质量的满足程度[16]。基于SpringBoot的CNKI数据精炼与展示系统的非功能需求是包括对开发环境的硬件和软件要求、服务器的硬件和软件要求,访问容量以及响应时间等参数。软件要求主要是指对相关操作系统、数据库服务器、Web服务器的要求。如图2.6所示。
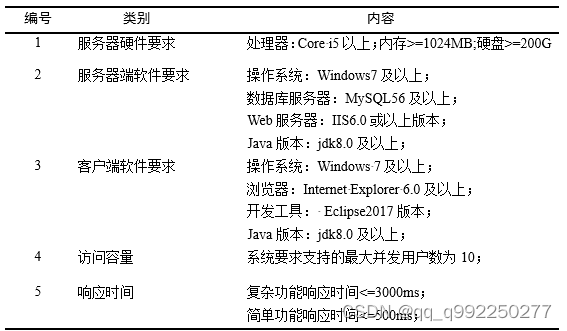
图2.6非功能需求清单
2.3 本章小结
本章主要介绍了基于SpringBoot的CNKI数据精炼与展示系统的需求分析,分别从功能需求和非功能需求进行分析[17],使用用例图展示了用例之间的关系及其功能,使用表格分别介绍了服务器硬件要求、服务器端软件要求、客户端软件要求等。
3 系统设计
本章以上一章所描述的需求分析为基础,对本系统做了系统设计[19]。设计了体系结构、层次结构、目录结构、功能结构,并设计了系统功能及数据库。为本项目系统的整个系统编写打好基础。
3.1 系统总体设计
本章是对基于SpringBoot的CNKI数据精炼与展示系统的总体设计、模块功能、数据表设计等进行了设计[18],使该系统更加符合用户的需求,同时为测试提供参考。
3.1.1 系统体系结构
本系统将采用B/S结构。程序员把业务逻辑的代码放在服务器端,很大程度上减轻了浏览器端的负担,用户在浏览器端只需要传输数据,数据传入到后端服务器后就会处理此功能的业务逻辑。B/S结构不仅仅保留了C/S结构优点,还使复杂的程序变得简单起来。
3.1.2 系统层次结构
entity层:又称为bean层,存放与数据表数据类型、名称相同的实体类。实体类对象与数据库中的数据表具有一一对应的映射关系,所有需要进行数据处理的字段都需要依赖对象模型,所以在开发项目时传入的参数和用到的方法都依赖于该层。
dao层:又称为mapper层,它的功能都是对数据库中各个表的进行执行SQL的操作。dao层的类仅仅为方法接口,具体的操作SQL在mapper.xml中定意。
service层:又称为业务层,存放系统功能的逻辑处理,不直接操作数据库,操作数据库依赖于dao层,为controller层提供方法,进行相应的业务处理。
controller层:又称为控制器层,接收view层传过来的AJAX请求并接收其参数,自动注入加载service层,在对数据简单处理后调用service层方法,再将service处理后的数据返回给view层。
View层:又称为UI、User Interface层,向用户展示经过基于SpringBoot的CNKI数据精炼与展示系统处理后的数据,即展示的需求功能、图表等。用户对界面做出相应的操作,通过AJAX将数据提交到后台controller层,做出相应操作。

图3.1 系统层次结构图
3.1.3 系统目录结构
静态文件(html、css、js、image)置于src/main/resources/static/;
动态页面(jsp、html、tpl)置于src/main/resources/templetes/;
配置文件(application.properties)置于src/main/resources/config/;
工程启动类(ApplicationServer.java)置于com.zeys;
实体类(Entity)置于com.zeys.entity;
数据访问层(Dao)置于com.zeys.dao;
数据服务层(Service)置于com,zeys.service;
前端控制器(Controller)置于com.zeys.controller;
工具类(Tool)置于com.zeys. tool;
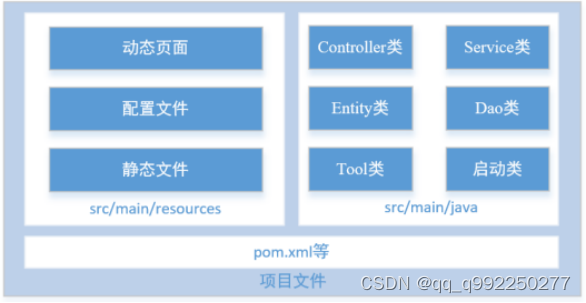
图3.2 系统目录结构
3.1.4 系统功能结构
本系统的功能分为五大模块:门户模块、搜索研究模块、需求研究模块、趋势研究模块、人群研究模块。系统提供功能如下:根据搜索内容显示该搜索内容近七日搜索次数折线变化以及搜索指数(包括但不限于周均值、月均值、周均同比、月均同比、总次数);显示搜索总数排行前十,页面所有图表均可以折线图或柱状图显示;显示该搜索内容关键词相关字符云以及主题指数(包括但不限于期刊、硕士、博士占比和主题增长率);显示文献总数、关键词总数、搜索总数、近20年文献发布数量(该饼状图点击相关扇形内容可隐藏显示该扇形内容)、以年为单位的最热关键词文献数量统计、近半年各类文献的发布量变化、文献发布量前十、每月文献发布量比例;显示该搜索内容相关搜索地域分布、相关搜索男女比例、相关搜索年龄比例,具体的功能结构图如图3.3所示。
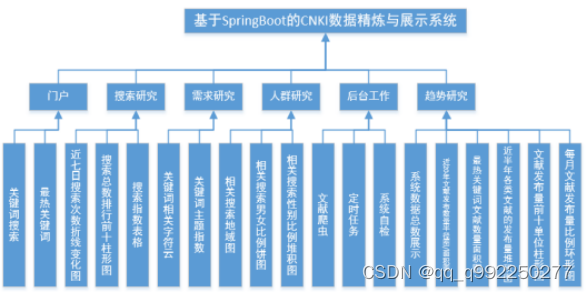
图3.3 系统功能结构图
3.2 系统详细设计
3.2.1 系统功能设计
这一部分主要描述的是该系统对两个核心功能的流程设计,以及举例各可视化图表的流程设计,并配以功能描述来对功能进行详细解释。以下完成了主要功能的系统设计。
文献信息爬取功能,使用了Selenium模拟真实用户操作实现爬虫[20],每次启动获取并使用上次停止爬取时的关键词与页码,启动爬虫,按照顺序爬取文献信息,验证数据库中是否存在该文献数据,判断是否将数据存入数据库,并爬取下一个数据,本页无数据后判断该关键词是否具有下一页文献信息,并执行相应方法,流程如图3.4所示。
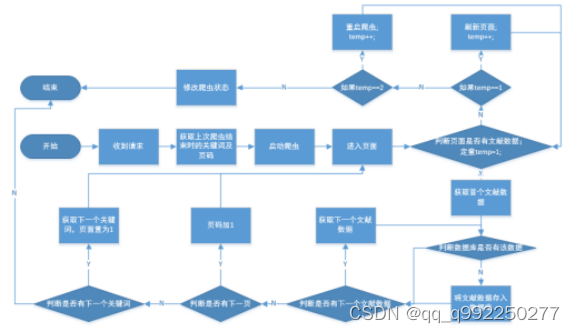
图3.4 文献信息爬取功能流程图
系统自检功能,为定时任务,每半小时执行一次,程序会先判断定时任务的执行时间,计算出相应的下次执行时间,放入线程中,到了时间就执行[21],启动时,首先检测数据可视化系统是否运行,如果未运行则通知系统管理人员,其次检测爬虫是否运行,如果未运行则发送请求启动爬虫,如果未启动成功则通知系统管理员,之后进入系统休眠,等待下一次执行,流程如图3.5所示。
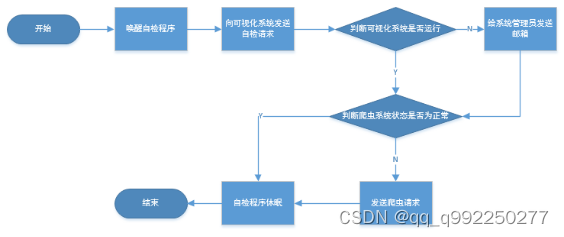
图3.5 系统自检功能流程图
大部分的可视化图表的流程为,用户打开某个页面,自动触发JS方法,发送Ajax请求,后台Controller接收到请求,先后调用Service方法与Mapping方法,从数据库中取出数据并进行处理,逐次向上返回数据,最终返回至页面,JS在触发生成可视化图表的方法,最终将可视化图表展示于用户眼前,详见图3.6所示。
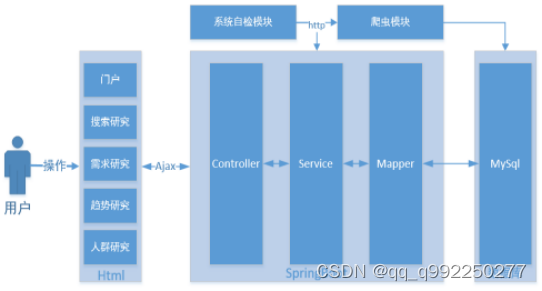
图3.6 数据可视化图表流程
3.2.2 数据库设计
根据上面描述的需求分析和系统设计,以及分析整个系统的业务流程[22],形成了可以分析基于SpringBoot的CNKI数据精炼与展示系统的信息需求的数据概念模型。本系统共7个实体,2个一对一关系,一个多对多关系,需要设计8个表,如表3.1所示。
表3.1 数据库表列表
编号 表名 说明
1 abnormals 异常表
2 journals 日志表
3 keywords 关键词表
4 literatures 文献表
5 records 字典表
6 regions 区域表
7 runnings 运行状态表
8 searchs 搜索记录表
异常表(abnormals)主要储存系统运行时发生的异常。例如异常信息、异常产生时间等,该表以自增长字段abnormalId作为主键,使每条记录具有唯一性。具体字段如表3.2所示。
表3.2 异常信息表
列名 数据类型(Datatype) 约束条件 其他说明
abnormalId int(11) KEY 异常编号
abnormal varchar(2000) NOT NULL 异常信息
addtime datetime NOT NULL 产生时间
日志表(journalss)主要储存系统运行时产生的日志。例如日志信息、日志等级、日志产生时间等,该表以自增长字段journalId作为主键,使每条记录具有唯一性。具体字段如表3.3所示。
表3.3 日志信息表
列名 数据类型(Datatype) 约束条件 其他说明
journalId int(11) KEY 日志编号
content varchar(300) NOT NULL 日志内容
grade int(11) NOT NULL 日志等级
addtime datetime NOT NULL 产生时间
关键词表(keywords)主要储存用户搜索产生的关键词。例如关键词、添加时间、搜索总数等。该表以自增长字段journalId作为主键,。具体字段如表3.4所示。
表3.4 关键词信息表
列名 数据类型(Datatype) 约束条件 其他说明
keywordId int(11) KEY 关键词编号
keyword varchar(45) DEFAULT NULL 关键词
addTime datetime DEFAULT NULL 添加时间
searchSum int(11) DEFAULT NULL 搜素总数
文献表(literatures)主要储存爬取到的文献数据。例如文献标题、文献作者、发布单位、论文种类等。该表以自增长字段literatureId作为主键,使每条记录具有唯一性。具体字段如表3.5所示。
表3.5 文献信息表
列名 数据类型(Datatype) 约束条件 其他说明
literatureId int(11) KEY 文献编号
literatureTitle varchar(200) DEFAULT NULL 文献标题
literatureAuthor varchar(200) DEFAULT NULL 文献作者
表3.5 文献信息表-续表
列名 数据类型(Datatype) 约束条件 其他说明
publicationUnit varchar(200) DEFAULT NULL 发布单位
publicationDate datetime DEFAULT NULL 发布时间
source varchar(45) DEFAULT NULL 来源
字典表(records)主要储存系统所需要的字典。例如文字典标题、字典内容、字典数据、添加时间等。该表以自增长字段recordId作为主键,使每条记录具有唯一性。具体字段如表3.6所示。
表3.6 字典信息表
列名 数据类型(Datatype) 约束条件 其他说明
recordId int(11) KEY 内容编号
recordName varchar(45) NOT NULL 字典标题
recordInt int(11) DEFAULT NULL 字典数据
recordString varchar(45) DEFAULT NULL 字典内容
区域表(regions)主要储存系统所需要的区域信息。例如区域名称、地域信息等。该表以自增长字段regionId作为主键,使每条记录具有唯一性。具体字段如表3.7所示。
表3.7 区域信息表
列名 数据类型(Datatype) 约束条件 其他说明
regions int(11) KEY 区域编号
regionName varchar(45) DEFAULT NULL 区域名称
addtime datetime DEFAULT NULL 添加时间
监控表(regions)主要储存系统运行时状态。例如进程名称、进程状态、更新时间等。该表以自增长字段regionId作为主键,使每条记录具有唯一性。具体字段如表3.8所示。
表3.8 监控信息表
列名 数据类型(Datatype) 约束条件 其他说明
runningid int(11) KEY 监控编号
name varchar(45) NOT NULL 进程名称
state int(11) NOT NULL 进程状态
addtime datetime NOT NULL 添加时间
搜索记录表(regions)主要储存用户的搜索记录。例如所搜索关键词、用户性别、用户年龄、添加时间等。该表以自增长字段searchId作为主键,使每条记录具有唯一性。具体字段如表3.9所示。
表3.9 搜索记录信息表
列名 数据类型(Datatype) 约束条件 其他说明
serchId int(11) KEY 记录编号
keyword varchar(45) DEFAULT NULL 关键词
gender varchar(45) DEFAULT NULL 用户性别
address varchar(45) DEFAULT NULL 用户地址
age int(11) DEFAULT NULL 用户年龄
serchTime datetime NOT NULL 搜索时间
3.3 本章小结
本章主要介绍了基于SpringBoot的医疗资源共享平台的系统设计,包括系统体系设计、系统层次设计、系统功能设计,以及系统功能设计和数据库设计,为系统接下来开发与实现打好基础。
4 系统实现
4.1 开发环境
本项目使用的操作系统为Windows10,。使用Eclipse2017作为开发工具,使用MySQL Workbench作为数据库管理软件操作数据库,处理器为Intel® i5处理器,足以满足开发需求。
4.2 开发规范
本系统完全按照Java的命名规范来进行命名,包括包名、类名、接口名、方法名等。其中包名全部由小写字母组成,并且见名知意,看见包名就知道里面是关于哪个方面的内容。在类或接口中的方法名一般小写字母开头,以驼峰命名法来进行命名。规范的命名和注释可以增加代码的可读性,方便开发人员找到对应的方法。
4.3 数据库实现
根据数据库的设计,以及各表之间的实体关系,设计出8张表,如图4.1所示。

图4.1 系统数据库界面
4.4 SpringBoot项目搭建
本系统使用Maven搭建SpringBoot项目工程[23],其中启动文件Application.java置于com.zeys包下,Controller、Dao、Service等各层Java类置于com.zrys.*下,静态文件置于resources/static文件夹下,页面文件置于resources/templates文件夹下,在application.properties中配置各类基本信息,如图4.2所示。
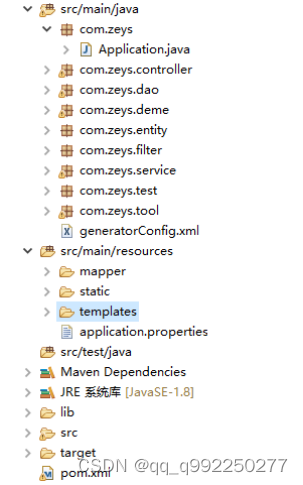
图4.2 项目工程图
4.5 功能实现
近七日搜索次数折线变化图,根据用户所搜索关键词,以7天为限,逐日对搜索记录表进行检索后,对日期信息及搜索记录次数信息返回,并展示出来,具体实现代码如下文所示,界面如图4.3所示。
public MappingJacksonValue addSousuo1(@RequestParam Map<String,String> map,HttpServletRequest request, String callback){
String content = map.get(“content”);
List searchSums = new ArrayList();
for(int i = 0;i>week;i–){
dates.add(DateTool.changeStringByMMdd(DateTool.addAndSubtractDaysByCalendar(date, week-i)));
searchSums.add(searchService.selectByKeywordAndMaxAndMin(content, )
}
MappingJacksonValue mappingJacksonValue = new MappingJacksonValue(Msg.success(“查询成功”).add(“searchSums”, searchSums).add(“dates”, dates).add(“title”, content));
mappingJacksonValue.setJsonpFunction(callback);
return mappingJacksonValue;
}
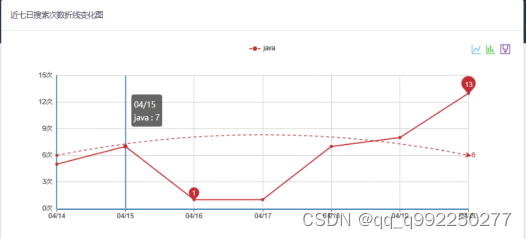
图4.3 近七日搜索次数折线变化图
搜索总数排行前十柱形图功能,打开搜索研究页面时自动触发,根据所有关键词的搜索总数,取其前十将关键词名称及搜索总数信息返回,并展示出来,具体实现代码如下文所示,界面如图4.4所示。
public MappingJacksonValue addSousuo2(@RequestParam Map<String,String> map, String callback){
List keywordBeans = keywordService.addSousuo2();
List keywords = keywordBeans.stream().map(KeywordBean::getKeyword).collect(Collectors.toList());
List searchsums = keywordBeans.stream().map(KeywordBean::getSearchsum).collect(Collectors.toList());
MappingJacksonValue mappingJacksonValue = new MappingJacksonValue(Msg.success(“查询成功”).add(“keywords”, keywords).add(“searchsums”, searchsums));
mappingJacksonValue.setJsonpFunction(callback);
return mappingJacksonValue;
}
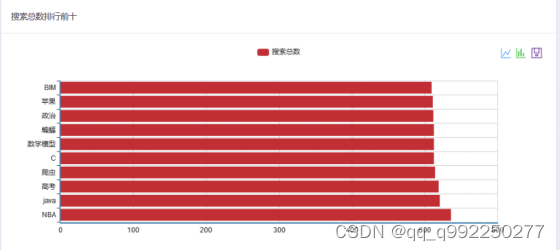
图4.4 搜索总数排行前十柱形图
近二十年文献发布量展示,打开趋势研究自动触发,根据文献发布时间,取近二十年的逐年文献发布量和年份返回,并在前段分为左边前十年半径图,数量越多半径越大,右边后十年面积图,数量越多面积越大,具体实现代码如下文所示,界面如图4.5所示。
public MappingJacksonValue addQvshi2(@RequestParam Map<String,String> map,String callback){
List names = new ArrayList();
for(int i = 0;i<10;i++){
String value = String.valueOf(literatureService.countMaxAndMin(
DateTool.addAndSubtractYearsByCalendar(date,-i-1),
DateTool.addAndSubtractYearsByCalendar(date,-i)));
mapContent.put(“value”, value);
String name = DateTool.changeStringBy4y(
DateTool.addAndSubtractYearsByCalendar(date,-i));
mapContent.put(“name”, name); addQvshi2s.add(mapContent);
names.add(name);
}
}
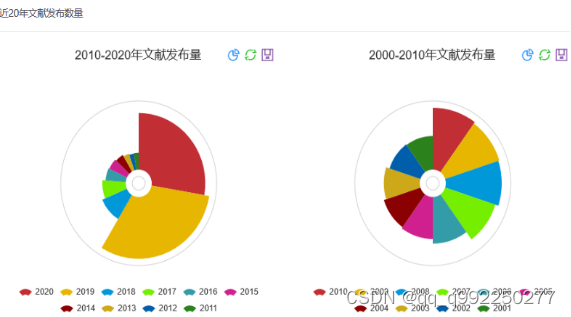
图4.5 近二十年文献发布量展示
最热关键词文献数量展示功能,打开趋势研究自动触发,根据最热门的前十个关键词,在文献表中检索与之相关的文献,返回关键词及文献数量,并用面积关系展示,具体实现代码如下文所示,界面如图4.6所示。
public MappingJacksonValue addQvshi4(String callback){
List keywordBeans = keywordService.addSousuo2();
Date minDate = DateTool.addAndSubtractYearsByCalendar(date, -1);
for(KeywordBean keywordBean:keywordBeans){
String name = keywordBean.getKeyword();
mapContent.put(“name”, name);
int value =literatureService.countTitleAndMaxAndMin(name, minDate, date);
mapContent.put(“value”, value); addQvshi4s.add(mapContent);
}
}
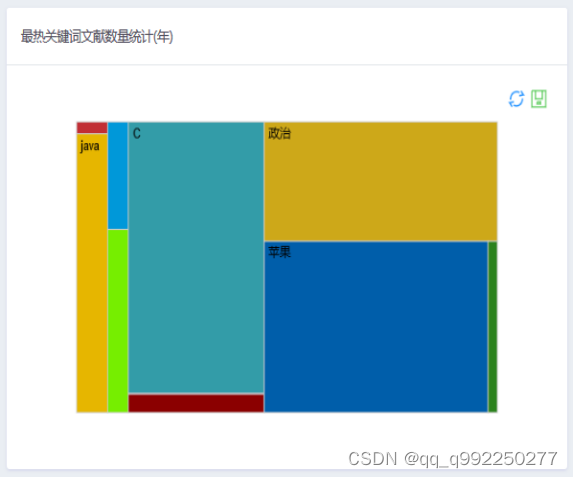
图4.6 最热关键词文献数量展示
每月文献发布量比例展示功能。打开趋势研究自动触发,根据所有文献信息的发布时间,按照其月份统计,返回每个月份发布的文献数量,并用环形图展示,具体实现代码如下文所示,界面如图4.7所示。
public MappingJacksonValue addQvshi7(String callback){
for(int i = 0;i<monthSum;i++){
int monthNum = i+1;
titles.add(monthNum+“月”);
HashMap<String,Object> contentMap = new HashMap<String,Object>();
contentMap.put(“name”, monthNum+“月”);
contentMap.put(“value”, recordService.selectByRecordName(monthNum+“月份文献总数”).getRecordint());
addQvshi7s.add(contentMap);
}
}
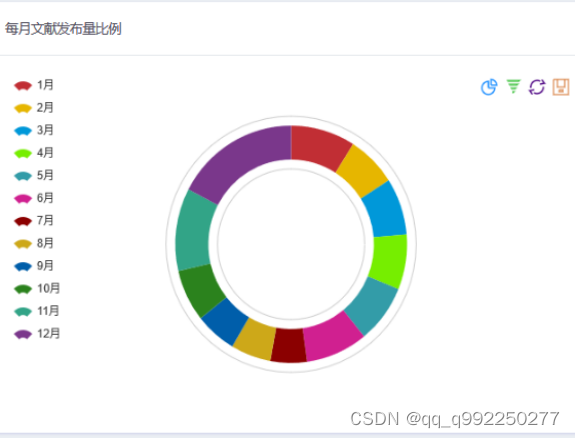
图4.7 每月文献发布量比例
相关搜索地域分布功能,打开人群研究自动触发,按照用户所搜索关键词,在搜索记录中检索,返回搜索记录的地域信息及数量,并用地图展示,具体实现代码如下文所示,界面如图4.8所示。
List regionBeans = regionService.select();
for(RegionBean regionBean:regionBeans){
String address = regionBean.getRegionname();
conMap.put(“name”, address);
conMap.put(“value”, searchService
.countByKeywordAndAddress(content,address));
addRenqun1s.add(conMap);
}
int max = (int)addRenqun1s.get(0).get(“value”);
titles.add(content);
MappingJacksonValue mappingJacksonValue =
new MappingJacksonValue(Msg.success(“查询成功”).
add(“keywords”, keywords).
add(“searchsums”, searchsums));
mappingJacksonValue.setJsonpFunction(callback);
return mappingJacksonValue;
}
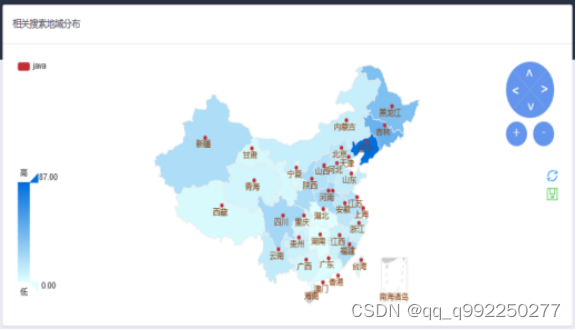
图4.8 相关搜索地域分布
最热关键词字符云,打开门户页面页面自动触发,会根据近期所有用户的搜索热度,及文献发布的热度综合计算,将排在前三十的文献关键词以字符云的形式显示出来,具体实现代码如下文所示,界面如图4.8所示。
public MappingJacksonValue indexChart(String callback){
int batch = Batch;
int pageDigit= PageDigit;
int pageSum = PageSum;
for(int i = 0; i< batch;i++){
indexChartBatch.put(“indexChartBatch”+i, keywordService.indexChart(pageDigit, pageSum));
pageDigit += pageSum;
} for(int j = 0; j< batch;j++){
indexChartBatch.put(“indexChartBatch”+j, keywordService.indexChart(pageDigit, pageSum));
pageDigit += pageSum;
}
MappingJacksonValue mappingJacksonValue = new MappingJacksonValue(Msg.success(“查询成功”).
add(“indexChartBatch”, indexChartBatch));
add(“keywords”, keywords).
add(“searchsums”, searchsums));
mappingJacksonValue.setJsonpFunction(callback);
return mappingJacksonValue;
}

图4.9 最热关键词字符云
4.6 本章小结
本章主要介绍了基于SpringBoot的CNKI数据精炼与展示系统的工作完成情况。在本章中规定了开发环境、开发规范,完成了数据库创作、完成了SpringBoot项目搭建,使前后端联调成功。
5 系统测试
系统测试是项目开发过程中一个重要的阶段。对软件进行实地化的场景化测试,目的是能够及时发现软件中的漏洞,使得系统更加完善。在整个基于SpringBoot的CNKI数据精炼与展示系统开发的过程中,会遇到各式各样的问题,而开发人员也不是精密的机器,不可避免的就会出现编码漏洞,有制度的测试可以规避以后错误的发生,为了减少错误的存在,优化系统功能,本章进行必要的测试。
5.1 测试计划
为了保证基于SpringBoot的CNKI数据精炼与展示系统的用户体验和使用质量,尽量找出该系统存在的错误并及时加以改正,确保用户能够更快更方便的使用该系统。在整个项目的实现过程中,将严格按照科学的软件测试方法,进行测试用例与压力测试,针对项目各个模块都进行测试。
5.2 用例测试
用例测试是将软件测试的行为活动做一个科学化组织归纳[24],本用例测试基于黑盒测试,着眼于程序外部结构,不考虑内部逻辑结构[25],主要针对软件界面和软件功能进行测试,本系统的主要模块分为:门户模块、搜索研究模块、需求研究模块、趋势研究模块、人群研究模块。本系统针对各模块功能中的主要操作进行了用例测试,测试其功能的按钮、显示、操作、自适应、响应事件等功能。首先测试门户模块,页面正确显示、关键词云展示正确、主旨展示正确、输入关键词正确,搜索功能可用。跳入搜索研究模块,页面显示正确、搜索次数折线变化图展示及功能正确、搜索指数表展示及功能正确、搜索总数排行展示及功能正确、搜索功能可用。打开需求研究模块,关键词相关字符云展示及功能正确、搜索功能可用。跳入趋势研究模块,相关指数展示正确、逐年文献发布量展示及功能正确、面积图展示及功能正确、文献发布量展示及功能正确、每月文献发布量展示及功能正确、搜索功能可用。打开人群研究、相关搜索地域图展示及功能正确、性别比例展示及功能正确、年龄比例展示及功能正确、搜索功能可用。全部用例测试结果如图表5.1所示。
表5.1 用例测试结果1
用例编号 用例分类 用例目的 预期结果 测试结果
Case1 门户模块 关键词搜索 跳转页面 结果相同
Case2 门户模块 关键词云展示 正确显示 结果相同
Case3 门户模块 主旨展示 正确显示 结果相同
Case4 搜索研究模块 关键词搜索 刷新页面 结果相同
Case5 搜索研究模块 搜索次数折线变化图 正确显示 结果相同
Case6 搜索研究模块 搜索指数 正确显示 结果相同
Case7 搜索研究模块 搜索总数排行前十 正确显示 结果相同
Case8 需求研究模块 关键词搜索 跳转页面 结果相同
Case9 需求研究模块 关键词相关字符云 正确显示 结果相同
Case10 需求研究模块 主题指数 正确显示 结果相同
Case11 趋势研究模块 关键词搜索 跳转页面 结果相同
Case12 趋势研究模块 文献总数 正确显示 结果相同
Case13 趋势研究模块 关键词总数 正确显示 结果相同
Case14 趋势研究模块 搜索总数 正确显示 结果相同
Case15 趋势研究模块 近20年文献发布数量 正确显示 结果相同
Case16 趋势研究模块 最热关键词文献数量 正确显示 结果相同
Case17 趋势研究模块 各类文献发布量变化 正确显示 结果相同
Case18 趋势研究模块 文献发布量前十单位 正确显示 结果相同
Case19 趋势研究模块 每月文献发布量比例 正确显示 结果相同
Case20 人群研究模块 关键词搜索 跳转页面 结果相同
Case21 人群研究模块 相关搜索地域分布 正确显示 结果相同
Case22 人群研究模块 相关搜索年龄比例 正确显示 结果相同
Case23 人群研究模块 相关搜索性别比例 正确显示 结果相同
5.3 压力测试
打开Jmeter软件,添加线程组,并配置其参数,添加HTTP请求,并配置HTTP请求路径、内容编码,添加添加结果数、聚合报告、响应时间图、汇总图,在所有接口中随机选择15个接口进行测试,每个接口线程数设置为100,启动测试,结果如图5.1所示。
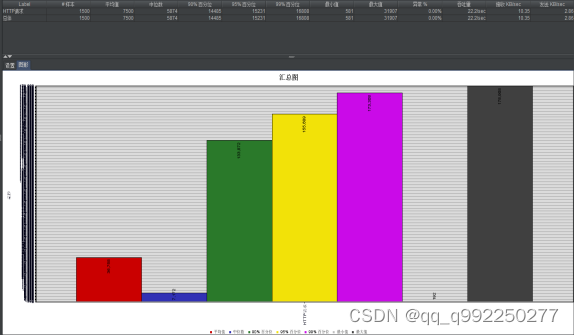
图5.1 测试信息汇总图1
对15个接口测试100次,测试完成后,打开测试结果,可以看到共发送1500次HTTP请求,平均响应时间7500ms,最快响应速度581ms,最慢反应速度31907ms,异常发生率0%,数据吞吐量22.2sec。
再次对这15个接口进行测试,将线程数调整为200。启动测试,测试结果如图5.2所示。
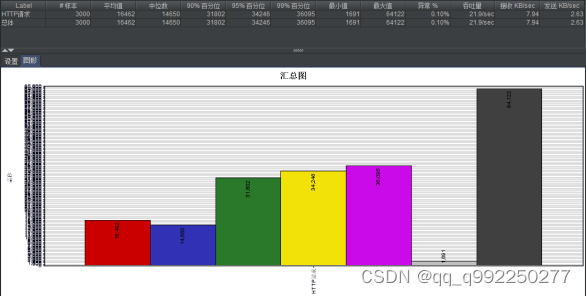
图5.2 测试信息汇总表2
对15个接口测试20次,可以看到平均响应时间为16462ms,最快响应速度1691ms,最慢响应速度64122ms,异常发生率0.10%,数据吞吐量21.9sec。明显可以看到,访问数量增多后,平均反应速度、最慢反应速度时间翻倍,虽有0.10%的几率发生异常,但这些数据足以说明系统的健壮性。
5.4 本章小结
本章主要叙述了测试的相关功能,使用了JMeter等测试工具来高效完成测试工作。软件工程的总目标高效率、高质量地完成软件开发项目。不足的测试势必使软件存在隐患[26],这样可能就会导致系统在运行中出现问题,破坏系统的口碑,甚至造成更大的损失。故此软件测试十分有必要。
结 论
每个人一生中都处于不断学习的状态,无论是刻意的学习还是被动的吸收,都是广义上的学习。而学习最重要的就是懂得借鉴,学会如何利用参考文献从别人的经验中转化为自己的知识,但参考文献又是多知为杂,如何从浩如烟海的参考文献中快速获取所需要的知识引起了众人的思考,由此产生了本项目的设计,知网包含庞大的文献信息,通过对这些数据的计算,进行数据计量分析,探索这些论文间各种数据之间的关系,总结文献数据的内在规律,帮助用户进行判断和决策,以便采取适当策略与行动,以期为用户获得科研选题灵感,为科研课题提供研究思路。
本文的系统在设计与实现的过程中充分考虑了系统二次开发的可能,以及随时可变的需求等要求,所采用的SpringBoot技术保证了系统具有效率高、耦合性低的特点。项目还存在爬取数据不稳定、计算数据时间较长、文献关键词较少等问题,下一阶段还需要针对这几个问题作出修改。
本系统利用爬虫技术爬取CNKI网站的文献数据信息,利用Java语言进行数据的综合分析,ECharts数据可视化技术动态交互式显示分析结果,服务器采用阿里云平台部署,项目的开发成本仅为阿里云服务器的购买,项目主旨在于为需要查询文献的人提供相关参考,不考虑收益问题,并且本项目开发人员基数小,人力费用小,因此项目非常有意义和可行性。
致 谢
经过四个月左右的时间,基于SpringBoot的CNKI数据精炼与展示系统得以实现,独立完成一个这样的系统遇到了许多困难,大部分问题是由于基础信息没有掌握,这让我意识到了掌握基础知识的重要性,以及需要将学到的知识应用好的重要性。
这四年的大学生活即将结束,我马上将要开始人生的另一个征程。在完成这次毕业设计的过程中,首先感谢我的指导老师高丽老师、聂菲老师对我的耐心教导,通过老师的指导,我论文的总体结构、功能结构和系统设计以及数据库设计都得到了完善的修改。感谢董超老师在实习期间传授我很多新的知识和经验。四年时间里,我跟老师学会的不仅仅限于课堂上的知识,更多的是教会我如何为人,还有一些实用的职场技能,让我在求职的道路上少走了不少弯路。最后还要感谢其他在这四年里教授过我知识的所有老师,感谢您们可以让我的学识更加渊博,同时也感谢在这四年里帮助过我的同学们,还要感谢我的企业内的指导教师,可以包容和纠正我的各种小错误,让我成为更好的自己。
参考文献
[1]Saket Bahador,Endert Alex,Rhyne Theresa-Marie. Demonstrational Interaction for Data Visualization.[J]. Pubmed, 2019, 39(3).
[2]胡艳.数据可视化在新闻报道中的应用前景探析[J]. 西南民族大学学报(自然科学版), 2014, 40(05):745-749.
[3]李舒颖. 移动应用缺陷报告的文本聚类技术研究[D]. 南京大学,2017.
[4]高亚山.基于Web的大数据可视化系统[J]. 信息与电脑(理论版), 2019(15):149-150.
[5]Hatma Suryotrisongko;Dedy Puji Jayanto;Aris Tjahyanto. Design and Development of Backend Application for Public Complaint Systems Using Microservice Spring Boot[D]. Procedia Computer Science, 2016.
[6]焦鹏珲. 基于SpringBoot和Vue框架的电子招投标系统的设计与实现[D]. 南京大学, 2018.
[7]江接宝,余卫红.基于开源的数据汇聚与可视化技术研究[J]. 电脑知识与技术,2019,15(10):235-236.
[8]闫昶. 基于协同过滤的景点推荐WebGIS平台设计与实现[D]. 西安科技大学, 2017.
[9]杨娇,陈强,王加宾,梁鉴如,周玲.基于Echarts的地铁屏蔽门数据监控系统的实现[J].智能计算机与应用,2018,8(04):144-148.
[10]王梧权. 具有风格特征的信息可视化设计和算法[D]. 天津大学, 2017.
[11]郑雪. 基于HDFS的大数据快速可视化系统的设计与实现[D]. 哈尔滨工业大学, 2018.
[12]张立. 内蒙古气象局综合信息系统的设计与实现[D]. 内蒙古大学, 2015.
[13]高佳忆,魏乃晓,徐文辉,贾燕.基于Web前端开发的公司网站设计研究[J]. 无线互联科技,2018,15(11):65-67.
[14]孙仕云.WEB系统前端开发技术分析[J]. 通讯世界, 2017(12):267-268.
[15]石贵民. 基于Visio的站内搜索系统的UML建模过程[J]. 信息技术, 2007(01):106-108+111.
[16]张璇,王旭,李彤,白川,康燕妮. 软件非功能需求权衡代价[J]. 软件学报, 2017, 28(05):1247-1270.
[17]Sirisha Adamala,N.S. Raghuwanshi,Ashok Mishra. Development of Surface Irrigation Systems Design and Evaluation Software (SIDES)[J]. Computers and Electronics in Agriculture,2014,100.
[18]Zakaria Maamar,Wathiq Mansoor. Design and Development of a Software Agent-Based and Mobile Service-Oriented Environment[J]. E-Service,2003,2(3).
[19]张良. 电网公司基建管理系统设计与实现[D]. 电子科技大学, 2014.
[20]吴毅良,罗序良,陆庭辉,郭凤婵.基于Java和Selenium的自动化操作工具的设计与实现[J]. 机电信息, 2019(06):56-57.
[21]许丽光,翁花群,曾福山. 基于Delphi的定时重启特定服务的程序设计与实现[J]. 电脑知识与技术, 2019, 15(12):284-286.
[22]王莹钰. 无线射频识别技术在高职院校图书管理系统应用浅析[J]. 科技风, 2018(10):5.
[23]刘敏. 基于SpringBoot框架社交网络平台的设计与实现[D]. 湖南大学,2018.
[24]陈少龙. 面向视障学生的无障碍教学互动APP设计与开发[D]. 华中师范大学, 2018.
[25]李香菊,孙丽,谢修娟,操凤萍,朱林. 软件工程课程设计教程[M]. 北京:北京邮电大学出版社,2016.01.
[26]孙辉. 针对某软件的系统测试的设计与实施[D]. 北京邮电大学,2015.
附录:源程序清单
@RestController
public class PaChongController {
@Autowired
LiteratureService literatureService;
@Autowired
RecordService recordService;
@Autowired
KeywordService keywordService;
@Autowired
JournalService journalService;
@Autowired
AbnormallService abnormallService;
@Autowired
RunningService runningService;
@RequestMapping(“/pachong”)
public void pachong() throws Exception {
RecordBean pageBean = recordService.selectByRecordName(“页面索引数”);
RecordBean literBean = recordService.selectByRecordName(“文献总数”);
RecordBean keywordBean = recordService.selectByRecordName(“关键词序号”);
List keywordBeans = keywordService.select();
//关键词总数
int keywordNum = keywordBeans.size();
//页面索引数
int pageDigit = pageBean.getRecordint();
//文献总数
int literNum = literBean.getRecordint();
//关键词序号
int keywordDigit = keywordBean.getRecordint();
// 调整高度
Thread.sleep(1000);
journalService.insert(“本次启动爬虫的关键词总数:”+keywordNum+“,文献总数:”
+literNum+“,关键词序号:”+keywordDigit+“,页面索引数:”+pageDigit+“。”,3);
//第一层循环是关键词循环,对每个关键词进行爬取工作
try{
for(int i = keywordDigit-1;i<keywordNum;i++){
String keyword = keywordBeans.get(i).getKeyword();
String url = “https://search.cn-ki.net/search?keyword=”+keyword+“&db=CFLS&p=” + pageDigit + “”;
journalService.insert(“当前循环爬虫的关键词:”+keyword+“,页面索引:”+pageDigit+“,即爬虫链接:”+url+“。”,4);
((ChromeDriver) driver).get(url);
Thread.sleep(1000);
//第二层循环是页面循环
while(true){
journalService.insert(“正在进行页面循环,当前关键词为:”+keyword+“,页面索引为”+pageDigit+“。”,2);
//首现判断该页面是否有效,以找到第一个文献标题为准
int temp = 1;
if(pageDigit>300){
WebElement nextBtn = ((ChromeDriver) driver).findElementByXPath(“/html/body/div[2]/div[25]/div/a[last()]”);
if(!nextBtn.getText().equals(“下一页”)){
journalService.insert(“该关键词无下一页,下一页的内容为:”+nextBtn.getText()+“。”,2);
keywordDigit++;
keywordBean.setRecordint(keywordDigit);
recordService.updata(keywordBean);
pageDigit = 1;
pageBean.setRecordint(pageDigit);
recordService.updata(pageBean);
journalService.insert(“完成关键词”+keyword+“的爬取工作,该关键词以无下一页,将关键词序号修改为:”+
keywordDigit+“,页面索引重置为:”+pageDigit+“。”,3);
}
}
while(!doesWebElementExist(driver, By.xpath(“/html/body/div[2]/div[3]/div/h3/a”))){
//先刷新页面试一试if(temp==1){Thread.sleep(5000);driver.navigate().refresh();journalService.insert("页面出现问题,正在进行页面刷新工作,当前关键词为:"+keyword+",页面索引为"+pageDigit+"。",3);Thread.sleep(5000);temp++;}if(temp==2){WebElement nextBtn = ((ChromeDriver) driver).findElementByXPath("/html/body/div[2]/div[25]/div/a[last()]");if(!nextBtn.getText().equals("下一页")){journalService.insert("该关键词无下一页,下一页的内容为:"+nextBtn.getText()+"。",2);keywordDigit++;keywordBean.setRecordint(keywordDigit);recordService.updata(keywordBean);pageDigit = 1;pageBean.setRecordint(pageDigit);recordService.updata(pageBean);journalService.insert("完成关键词"+keyword+"的爬取工作,该关键词以无下一页,将关键词序号修改为:"+keywordDigit+",页面索引重置为:"+pageDigit+"。",3);}else journalService.insert("爬虫出现问题,请尽快处理。",4);break;}}//第三层循环对每页的每个文献信息进行爬取for (int j = 3; j < 23; j++) {//判断是否有这个文献资料if(!doesWebElementExist(driver, By.xpath("/html/body/div[2]/div[" + j + "]/div/h3/a")))break;LiteratureBean literatureBean = new LiteratureBean();literatureBean.setLiteraturetitle(driver.findElement(By.xpath("/html/body/div[2]/div[" + j + "]/div/h3/a")).getText());String author = driver.findElement(By.xpath("/html/body/div[2]/div[" + j + "]/div/div[1]/span[1]")).getText();if(author.length()>100){author = author.substring(0, 98);journalService.insert("作者长度较长,进行裁剪,裁剪后的内容为:"+author+",标题为"+literatureBean.getLiteraturetitle()+"。",1);}literatureBean.setLiteratureauthor(author);literatureBean.setPublicationunit(driver.findElement(By.xpath("/html/body/div[2]/div[" + j + "]/div/div[1]/span[3]")).getText());try {date = simpleDateFormat.parse(publicationdate.substring(5));} catch (Exception e) {journalService.insert("时间格式有问题,选择默认时间:"+date+",标题为"+literatureBean.getLiteraturetitle()+"。",1);}literatureBean.setPublicationdate(date);literatureBean.setSource(driver.findElement(By.xpath("/html/body/div[2]/div[" + j + "]/div/div[1]/span[5]")).getText());if(literatureService.selectIsTitleAndAythor(literatureBean.getLiteraturetitle(),literatureBean.getLiteratureauthor())){literatureBean.setQuotenum(1);literatureService.insert(literatureBean);literNum++;}else{System.out.println("此数据已存在数据库");}}//第三层循环对每页的每个文献信息进行爬取工作结束literBean.setRecordint(literNum);recordService.updata(literBean);pageDigit++;pageBean.setRecordint(pageDigit);recordService.updata(pageBean);journalService.insert("完成进行页面循环,当前关键词为:"+keyword+",页面索引已修改:"+pageDigit+",文献总数已修改:"+literNum+"。",2);RunningBean runningBean = runningService.selectByNname("爬虫运行状态");runningBean.setState(1);runningService.updata(runningBean);try {WebElement nextBtn = ((ChromeDriver) driver).findElementByXPath("/html/body/div[2]/div[25]/div/a[last()]");Thread.sleep(5000);System.out.println(nextBtn.getText());if(nextBtn.getText().equals("下一页")){nextBtn.click();}else{journalService.insert("该关键词无下一页,下一页的内容为:"+nextBtn.getText()+"。",2);keywordDigit++;keywordBean.setRecordint(keywordDigit);recordService.updata(keywordBean);pageDigit = 1;pageBean.setRecordint(pageDigit);recordService.updata(pageBean);journalService.insert("完成关键词"+keyword+"的爬取工作,该关键词以无下一页,将关键词序号修改为:"+keywordDigit+",页面索引重置为:"+pageDigit+"。",3);break;}} catch (Exception e) {// TODO: handle exceptionpageDigit = 1;pageBean.setRecordint(pageDigit);recordService.updata(pageBean);journalService.insert("找不到页码导航栏的最后一个元素?。",4);break;}}}Thread.sleep(5000);driver.close();}catch(Exception e){abnormallService.insert(e.toString());driver.close();}
}
}
这篇关于基于SpringBoot的CNKI数据精炼与展示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







