本文主要是介绍爬虫练习——爬取笔趣阁,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取笔趣阁
- 任务
- ip 代理的设置
- 完整代码
- 效果
- 总结
任务
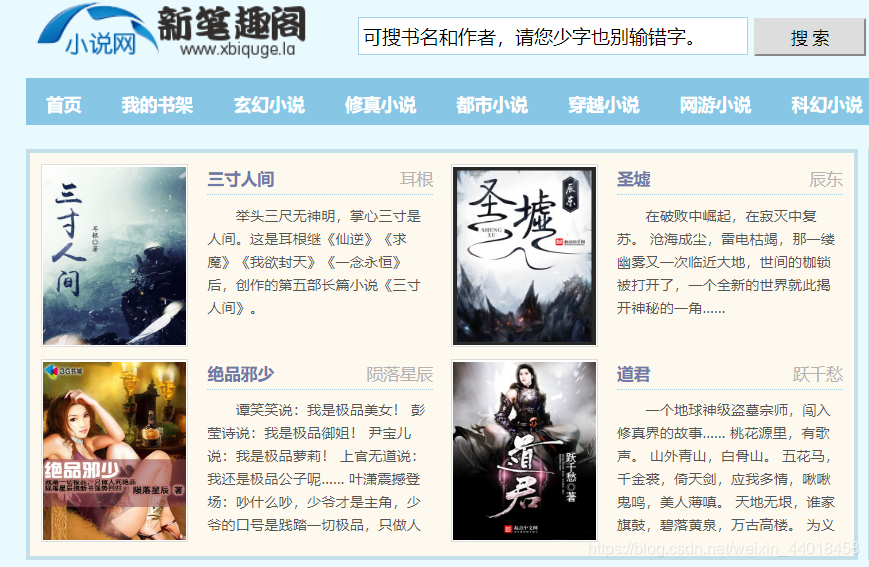
- 爬取上面这 4 本小说
- 使用 requests 库
- 不能漏掉 1 章
- 在有限的时间内爬完
- 以下面这个形式保存

ip 代理的设置
免费 ip 代理网站:
- https://seofangfa.com/proxy/
- http://www.data5u.com/
代理测试网站:
- http://httpbin.org/
测试代理是否可用
import requestsproxy = ['221.131.158.246:8888','183.245.8.185:80','218.7.171.91:3128','223.82.106.253:3128','58.250.21.56:3128','221.6.201.18:9999','27.220.51.34:9000','123.149.136.187:9999','125.108.127.160:9000','1.197.203.254:9999','42.7.30.35:9999','175.43.56.24:9999','125.123.154.223:3000','27.43.189.161:9999','123.169.121.100:9999']
for i in proxy:proxies = {'http':'http://'+i,'https':'https://'+i}print(proxies)try:response = requests.get("http://httpbin.org/",proxies=None)print(response.text)except requests.exceptions.ConnectionError as e:print('Error',e.args)
随机选取 1 个 ip
import requests
from random import choicedef get_proxy():proxy = ['221.131.158.246:8888','183.245.8.185:80','218.7.171.91:3128','223.82.106.253:3128','58.250.21.56:3128','221.6.201.18:9999','27.220.51.34:9000','123.149.136.187:9999','125.108.127.160:9000','1.197.203.254:9999','42.7.30.35:9999','175.43.56.24:9999','125.123.154.223:3000','27.43.189.161:9999','123.169.121.100:9999']return choice(proxy)proxy = get_proxy()proxies = {'http':'http://'+proxy,'https':'https://'+proxy}
print(proxies)
try:response = requests.get("http://httpbin.org/",proxies=None)print(response.text)
except requests.exceptions.ConnectionError as e:print('Error',e.args)
完整代码
import requests
import re
import os
import threading
from random import choicedef get_proxy():# 获得代理ipproxy = ['221.131.158.246:8888','218.7.171.91:3128','58.250.21.56:3128']return choice(proxy)def getHTMLText(url,timeout = 100):try:headers = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",}proxy = get_proxy()print(proxy)proxies = {'http':'http://'+proxy,'https':'https://'+proxy}r = requests.get(url,headers=headers,proxies=proxies)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return '错误'def write_file(file,content):# 小说标题和内容title_content = re.findall(r'<h1>(.*?)</h1>[\s\S]*?<div id="content">([\s\S]*?)<p>',content)for title,content in title_content:# 小说内容处理content = content.replace(' ',' ').replace('<br />','\n')#print(title,content)with open(file,'w',encoding='utf-8') as f:f.write('\t\t\t\t'+title+'\n\n\n\n')f.write(content)def download(book,title,href):'''book: 小说名称title: 章节标题href: 小说内容的url'''content = getHTMLText(href)write_file(book+"\\"+title+'.txt',content)def main():threads = []url = "http://www.xbiquge.la"html = getHTMLText(url)# 获取小说的名称和小说目录urlnovel_info = re.findall(r'<div class="item">[\s\S]*?<dt>.*?<a href="(.*?)">(.*?)</a>',html)for href,book in novel_info:print(href,book)# ---------------------------------------------------------- ## 创建文件夹 名字为书名if os.path.exists(book):pass else:os.mkdir(book) # ---------------------------------------------------------- #novel = getHTMLText(href)# 获取小说内容url和章节标题chapter_info = re.findall(r"<dd><a href='(.*?)' >(.*?)</a>",novel)# http://www.xbiquge.la/10/10489/4534454.htmlfor href,title in chapter_info:href = url + hrefprint(href,title)# ---------------------------------------------------------- ## 多线程爬取T = threading.Thread(target=download,args=(book,title,href))T.setDaemon(False) # 后台模式T.start()threads.append(T)# ---------------------------------------------------------- ##download(book,title,href) # 不使用多线程爬取for T in threads:T.join()if __name__ == "__main__":main()
效果
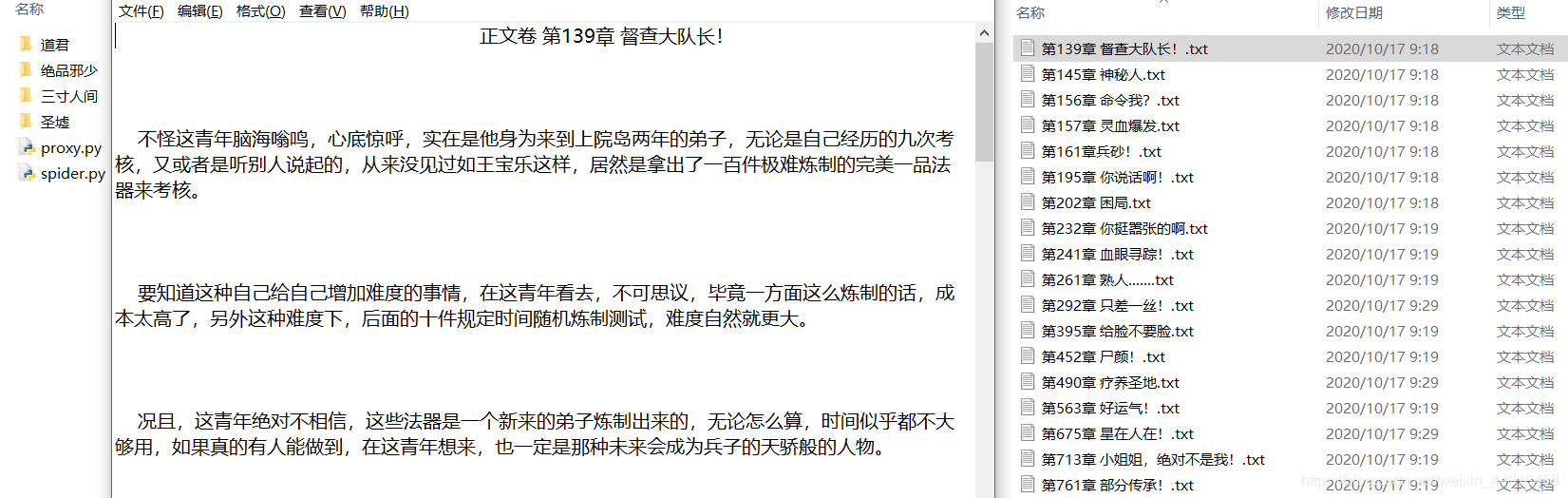
总结
- 免费 ip 代理不好用
- 该程序的鲁棒性较差
解决方法:
- 这次可不用 ip 代理,或用付费 ip 代理,构造自己的代理池
- 增加超时处理
这篇关于爬虫练习——爬取笔趣阁的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







