本文主要是介绍KPN对任意形状文本检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、研究背景
- 二、方法流程
- 1. 特征提取
- 2. 核建议
- 3. 实例无关特征图
- 4. 轮廓生成
- 5. 其余部分内容
- 三、不足
一、研究背景


相比起基于 FCN 网络的文本边缘检测网络,KPN网络可以更好地处理文本之间的间隔。
二、方法流程

1. 特征提取
FCN 和 FPN
FCN(全卷积神经网络) 介绍
FPN(特征金字塔神经网络) 介绍
特征提取网络有两个输入:图片和位置信息
位置信息怎么来的?
对图片中每一个像素点进行处理,从而生成两个通道的特征图。
每个像素点具有关于 x 轴和 y 轴的位置信息,每个像素点的 x 轴生成一个通道,y轴生成一个通道。位置大小范围转换为 [ − 1 , 1 ] [-1,1] [−1,1], 即在坐标原点处的像素点关于 x 轴的值为 -1。
具体计算方法如下图所示。

其中 w , h w, h w,h 表示输出特征图的宽度和高度, i i i 表示第 i i i 个像素点。


2. 核建议
预测中心图获取文本的连通分量, 获取连通分量是因为对于一个文本实例存在冗余点
分量得分点最高的像素作为关键点???

关键点对应位置的特征图为预测核

3. 实例无关特征图
嵌入特征图与预测核进行卷积得到实例无关特征图

其中 O O O 表示输出的实例无关特征图,每个通道对应一个文本的预测( p i p_i pi)
K K K 表示得到的卷积核
E E E 表示预测中心图( F s F_s Fs) 和 嵌入特征图( F p F_p Fp) 的卷积结果


4. 轮廓生成
通过预先设定的阈值对预测出的实例无关特征图进行二值化处理,得到待检测文本的轮廓

5. 其余部分内容
对于在找到的每一个预测中心图中找到的点,实际上对应的是一个文本实例。所以由此得到的核建议之间应该尽量保持正交关系,这样就可以在一定程度上避免不同文本实例之间的干扰。
由此可以得到一个函数
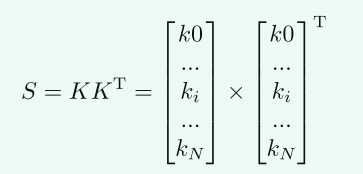
K K K 表示得到的卷积核, k i k_i ki 表示由预测中心图中的一个点得到的核建议。
对此提出了一个损失函数 L O L L L_{OLL} LOLL

其中 I I I 表示单位矩阵
L d i c e L_{dice} Ldice表示骰子损失
L B C E L_{BCE} LBCE表示二进制交叉熵损失。

三、不足
对场景文本复杂和小文本的环境下存在漏检的情况.
红色表示实际情况,绿色表示 KPN 检测结果


这篇关于KPN对任意形状文本检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







