本文主要是介绍大型文件数据读取并持久化到数据库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
产品经理今天给了一个上亿数据的文本文件给我,让我把导入到mysql数据库。
文本的内容很简单,只有一个字段,但有1亿行。
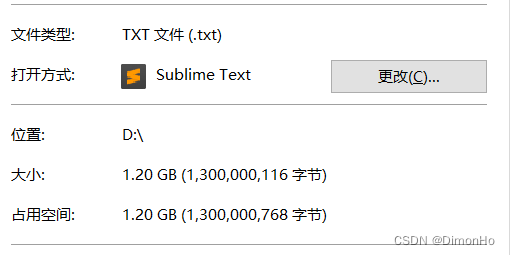
我拿到文件后最开始直接用navicat工具直接导入,但发现效率极慢,跑了一分多钟,才导进去10W+数据进去,算下来要跑完至少需要20多个小时,时间不允许。
看来只能自己写代码来提升效率了。
常规的做法肯定是把文件内容按行读取出来,然后每N条拆分一批,再插入到数据库中。但这个文件太大,一次性全部读取到内存中,对机器有点压力。所以只能按批来读取,一边读一边写,已经持久化的数据就及时释放掉,避免一直占用内存。哎!LinkedBlockingQueue 就很适合干这个事。
import cn.hutool.core.collection.CollUtil;
import cn.hutool.core.collection.LineIter;
import cn.hutool.core.io.FileUtil;
import com.yc.kfpt.oversea.dao.entity.SourceCode;
import com.yc.kfpt.oversea.dao.repository.SourceCodeRepository;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;import java.io.BufferedReader;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Executor;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;/*** @author 敖癸* @formatter:on* @since 2024/3/6*/
@Slf4j
@Service
@RequiredArgsConstructor
public class ImportDataService {private final SourceCodeRepository sourceCodeRepository;private final Executor asyncExecutor;@Asyncpublic void importData() {LinkedBlockingQueue<String> codeQueue = new LinkedBlockingQueue<>(500000);// 监听器线程queueListener(codeQueue).start();readFile("D:\\91-240305-j000.txt", codeQueue);}/*** 创建队列监听器** @param codeQueue* @return java.lang.Thread* @author 敖癸* @since 2024/3/6 - 16:41*/private Thread queueListener(LinkedBlockingQueue<String> codeQueue) {return new Thread(() -> {long index = 0;List<String> codes = new ArrayList<>();while (true) {try {String code = codeQueue.poll(5, TimeUnit.SECONDS);// 如果超过5秒从队列中还没获取到数据,就认为已经没有数据了if (code == null) {if (CollUtil.isNotEmpty(codes)) {log.info("入库处理: {}", index);List<SourceCode> entities = convertToEntity(codes);asyncExecutor.execute(() -> sourceCodeRepository.saveBatch("GENERAL", entities));codes.clear();}break;}index++;codes.add(code);// 5000一个批次if (codes.size() == 5000) {log.info("入库处理: {}", index);List<SourceCode> entities = convertToEntity(codes);// 持久化操作扔到线程池中异步去执行,可以多开点线程数量。asyncExecutor.execute(() -> sourceCodeRepository.saveBatch("GENERAL", entities));codes.clear();}} catch (InterruptedException e) {throw new RuntimeException(e);}}});}/*** 文件读取** @param codeQueue* @author 敖癸* @since 2024/3/6 - 16:41*/private static void readFile(String filePath, LinkedBlockingQueue<String> codeQueue) {BufferedReader reader = FileUtil.getReader(filePath, Charset.defaultCharset());int readCount = 0; // 读取行数计数try (LineIter lineIter = new LineIter(reader)) {while (lineIter.hasNext()) {readCount++;// 如果codeQueue中的元素个数已达上限,这里会阻塞codeQueue.put(lineIter.next());if (readCount % 50000 == 0) {log.info("已读取{}行", readCount);}}} catch (Exception e) {log.error("文件读取异常", e);}log.info("读取完成,供{}行", readCount);}/*** 将行数据转换成数据库对象** @param codes* @return java.util.List<com.yc.kfpt.oversea.dao.entity.SourceCode>* @author 敖癸* @since 2024/3/6 - 16:43*/private static List<SourceCode> convertToEntity(List<String> codes) {return codes.stream().map(SourceCode::new).collect(Collectors.toList());}
}
实测,1亿数据量,大概花了20分钟导入完成。
这里需要注意的知识点:
LinkedBlockingQueue 的 put 方法,如果队列已满,会阻塞等待,直到队列中腾出空位。
LinkedBlockingQueue 的 poll 方法,可以设置超时时间,在等待超时后如果在队列中还是没有拿到数据,就返回null。
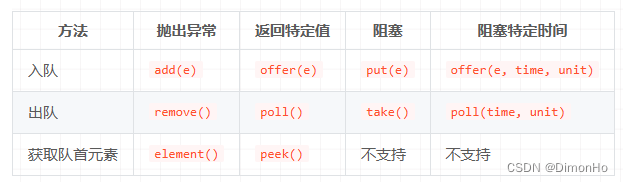
注意 take, add, offer, remove,poll,put的使用区别
关于 LinkedBlockingQueue 的详解,可以参考一下这位博主的文章
深入理解Java系列 | LinkedBlockingQueue用法详解
这篇关于大型文件数据读取并持久化到数据库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




