本文主要是介绍PaddleOCR CPU 文本文字识别 docker部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
需求:
需要把所有滑块图片的数据文字提取出来

启动服务
mkdir paddle
cd paddle
docker run -itd --name ppocr -v $PWD:/paddle --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda10.2-cudnn7 /bin/bash
docker exec -it ppocr bash
#cpu
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install "paddleocr>=2.0.1" -i https://mirror.baidu.com/pypi/simple # 推荐使用2.0.1+版本
文字提取
paddleocr --image_dir ./imgs_words/ch/word_1.jpg --det false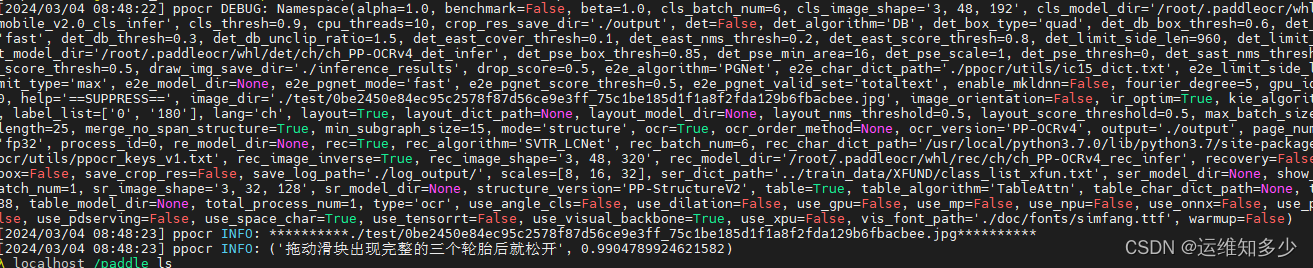
from paddleocr import PaddleOCR, draw_ocrimport os# 指定目录路径
directory = './test/'ocr = PaddleOCR(det=False) # need to run only once to download and load model into memory
# 遍历目录下所有文件
for filename in os.listdir(directory):# 检查文件是否以 .jpg 结尾if filename.endswith('.jpg'):# 获取完整的文件路径img_path = os.path.join(directory, filename)# 在此处添加处理图片的代码print(img_path)#img_path = f'{img_path}'result = ocr.ocr(img_path, det=False)for idx in range(len(result)):res = result[idx]print(res[0][0])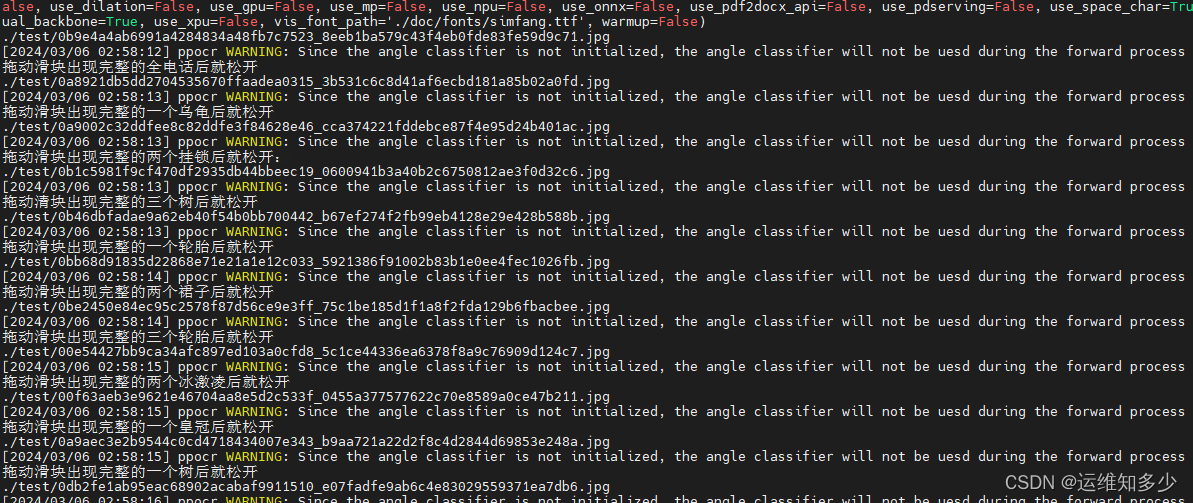
更多模型方式请查看官网
官网
这篇关于PaddleOCR CPU 文本文字识别 docker部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!