本文主要是介绍基于Django的携程网Top热门景点数据可视化分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
今天给大家分享一个基于Django的携程网Top热门景点数据可视化分析项目,以下是该项目大大概内容
项目名称:基于Python(django)的携程Top热门景点数据可视化分析
涉及技术:Python,Django,Mysql,Web前端~
项目实现功能:用户登录注册,个人信息编辑,数据总览以及收藏,对爬取的数据进行可视化图标的展示等~
现在简单来分析一下这个小项目吧:
项目分析以及展示:
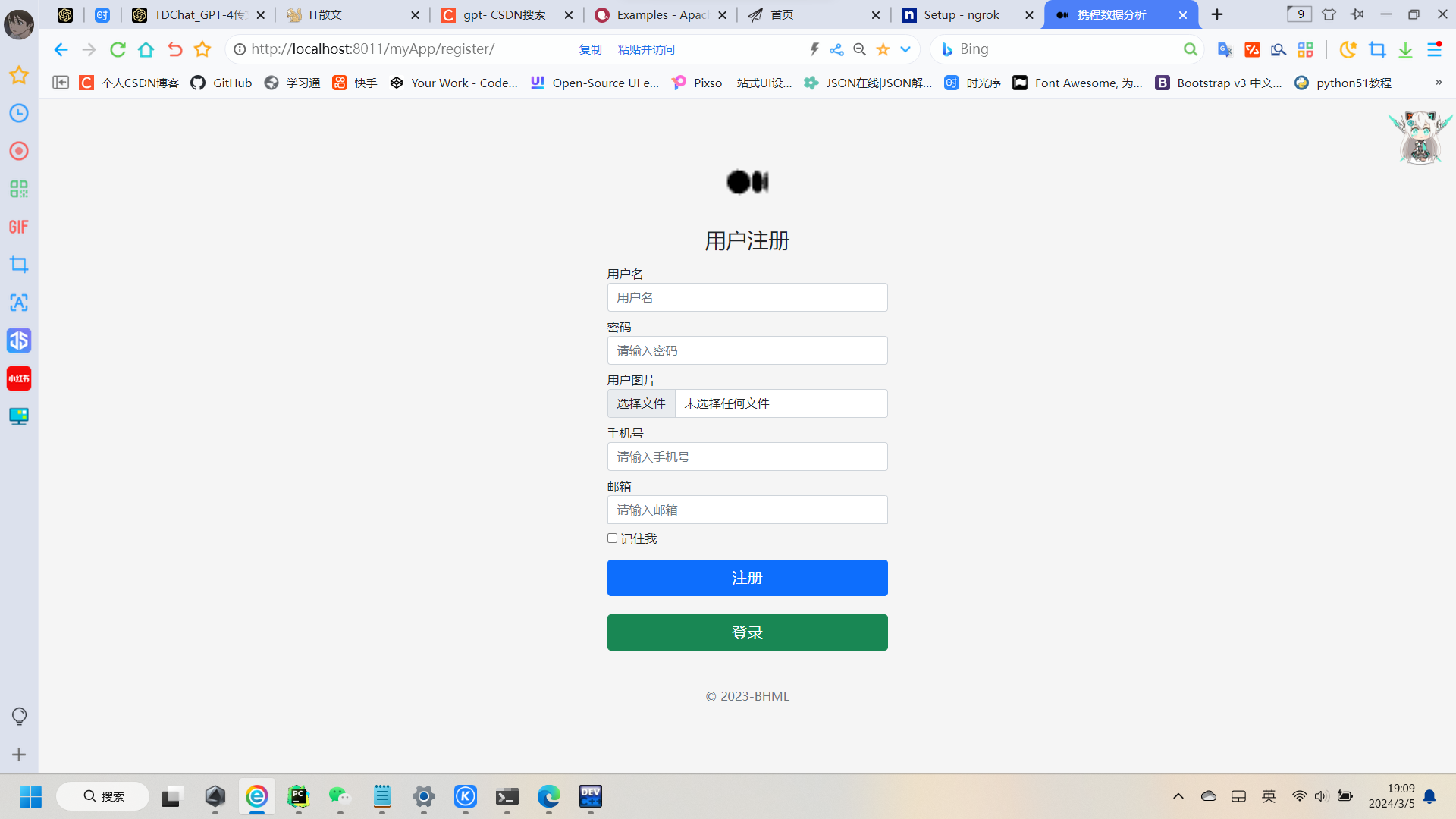
1:登录注册
这个功能基本上是每一个同学做设计网站的过程中必不可少的步骤啦,其实这个就是一个Form表单的Post提交验证,注册时获取输入框上的文本后,然后 models.objects.create(字段1=值1,字段2-值2......)就可以啦,登陆时只需获取输入框的内容验证其账号和密码是否存在于Mysql数据库即可,有的话则正常进入首页(下一页),没有的话课适当弹出提示信息
代码:
def login(request):if request.method == 'GET':return render(request, 'login.html')if request.method == 'POST':name = request.POST.get('name')password = request.POST.get('password')if User.objects.filter(username=name, password=password):user=User.objects.get(username=name, password=password)username=request.session['username'] = {'username':user.username,'avatar':str(user.avatar)}return redirect('index')else:msg = '信息错误!'return render(request, 'login.html', {"msg": msg})# 02用户注册
def register(request):if request.method == 'POST':name = request.POST.get('name')password = request.POST.get('password')phone = request.POST.get('phone')email = request.POST.get('email')avatar = request.FILES.get('avatar')stu = User.objects.filter(username=name)if stu:msg = '用户已存在!'return render(request, 'register.html', {"msg": msg})else:User.objects.create(username=name,password=password,phone=phone,email=email,avatar=avatar)msg = "注册成功!"return render(request, 'login.html', {"msg": msg})if request.method == 'GET':return render(request,'register.html')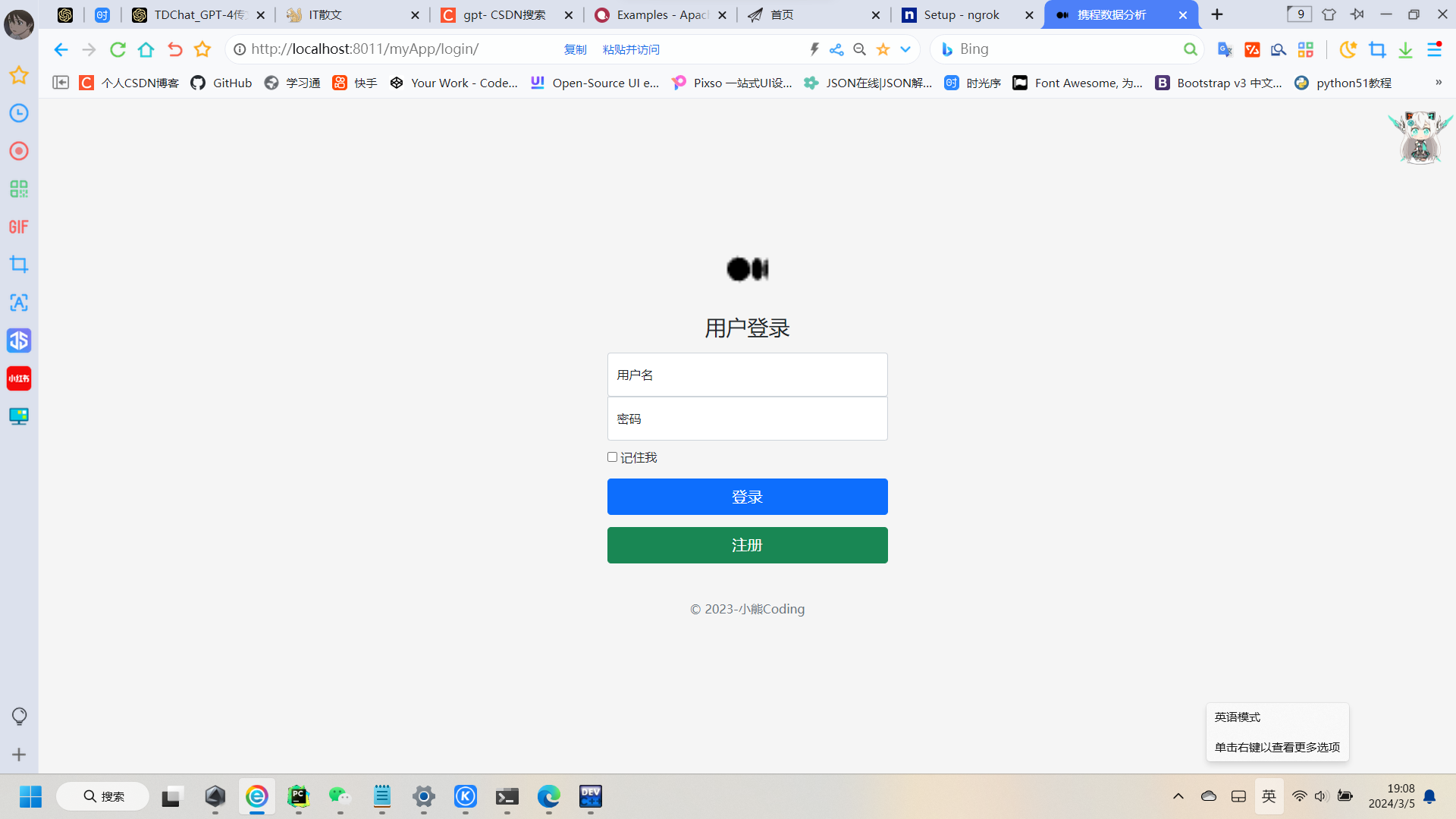
2:个人信息编辑
只需使用数据库ORM的filter()字段为用户名等于我们登录时的名称即可,这里咱们知道获取我们登陆时的所昵称或者别的信息的,这里可以使用Session缓存 的方法来获取,具体怎么操作,我的上一篇博客已经介绍过啦,然后我们就顺利拿到我们用户的对象啦,然后正常映射到前端即可啦,修改个人信息也是Post方法,然后获取新的输入内容后,只需yourmodel.字段=获取的新数据 即可实现数据库原本内容的覆盖修改:
代码:
def selfInfo(request):username = request.session.get("username").get('username')useravatar = request.session.get("username").get('avatar')userInfo=User.objects.get(username=username)context={'username':username,'useravatar':useravatar,'userInfo':userInfo}return render(request,'selfInfo.html',context)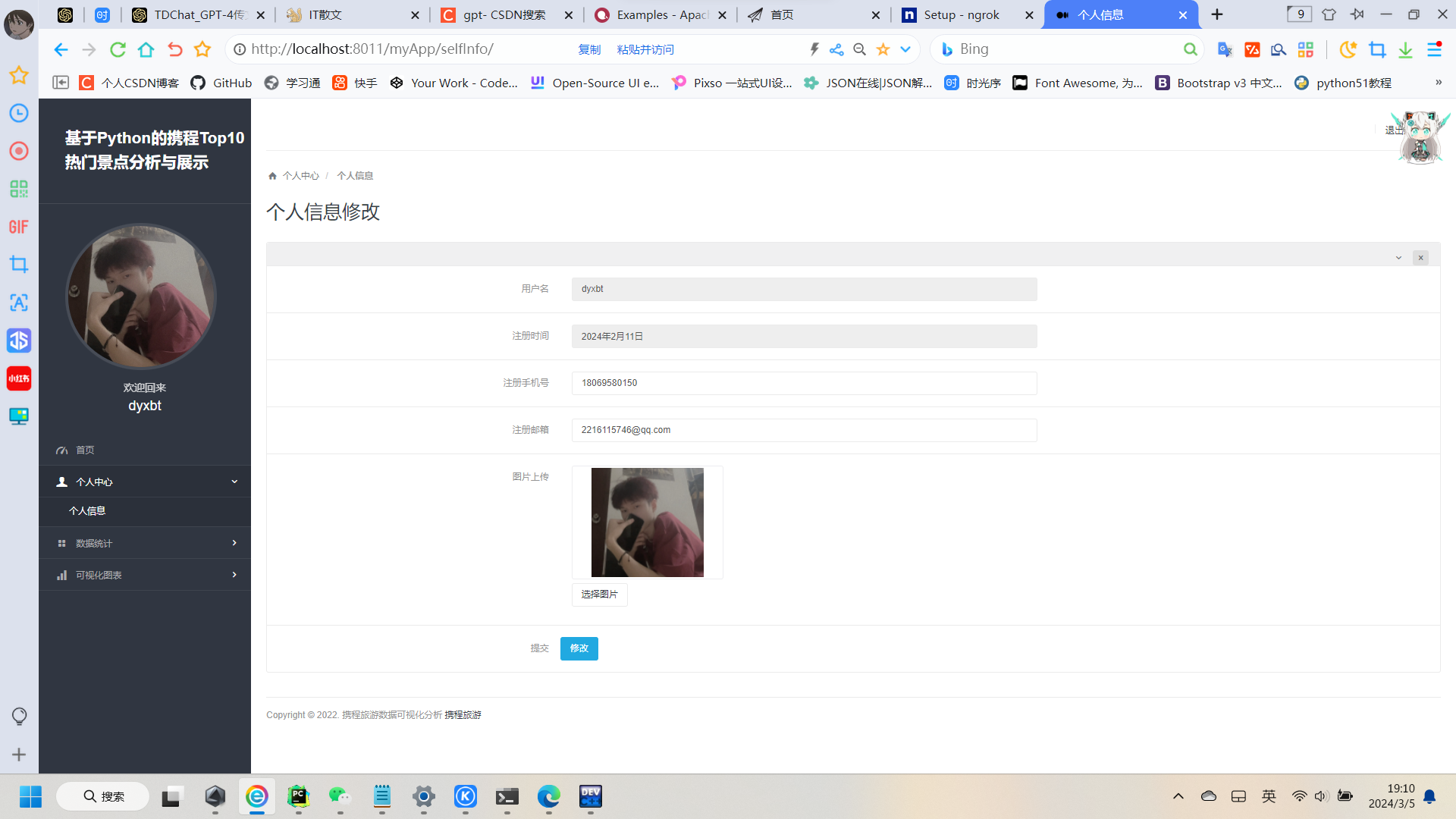
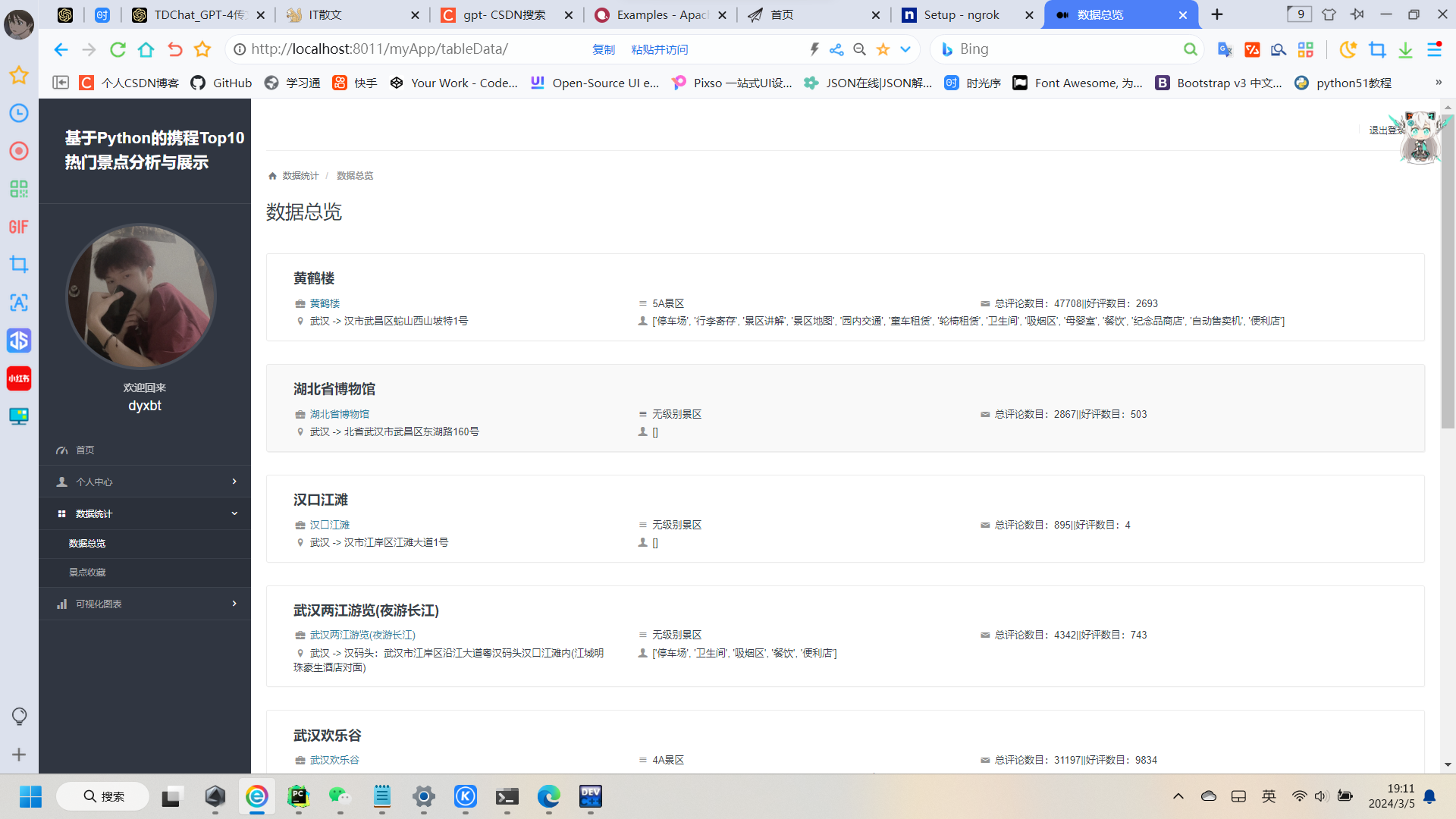
3:数据总览
这个内容就纯粹获取全部数据遍历展示啦:
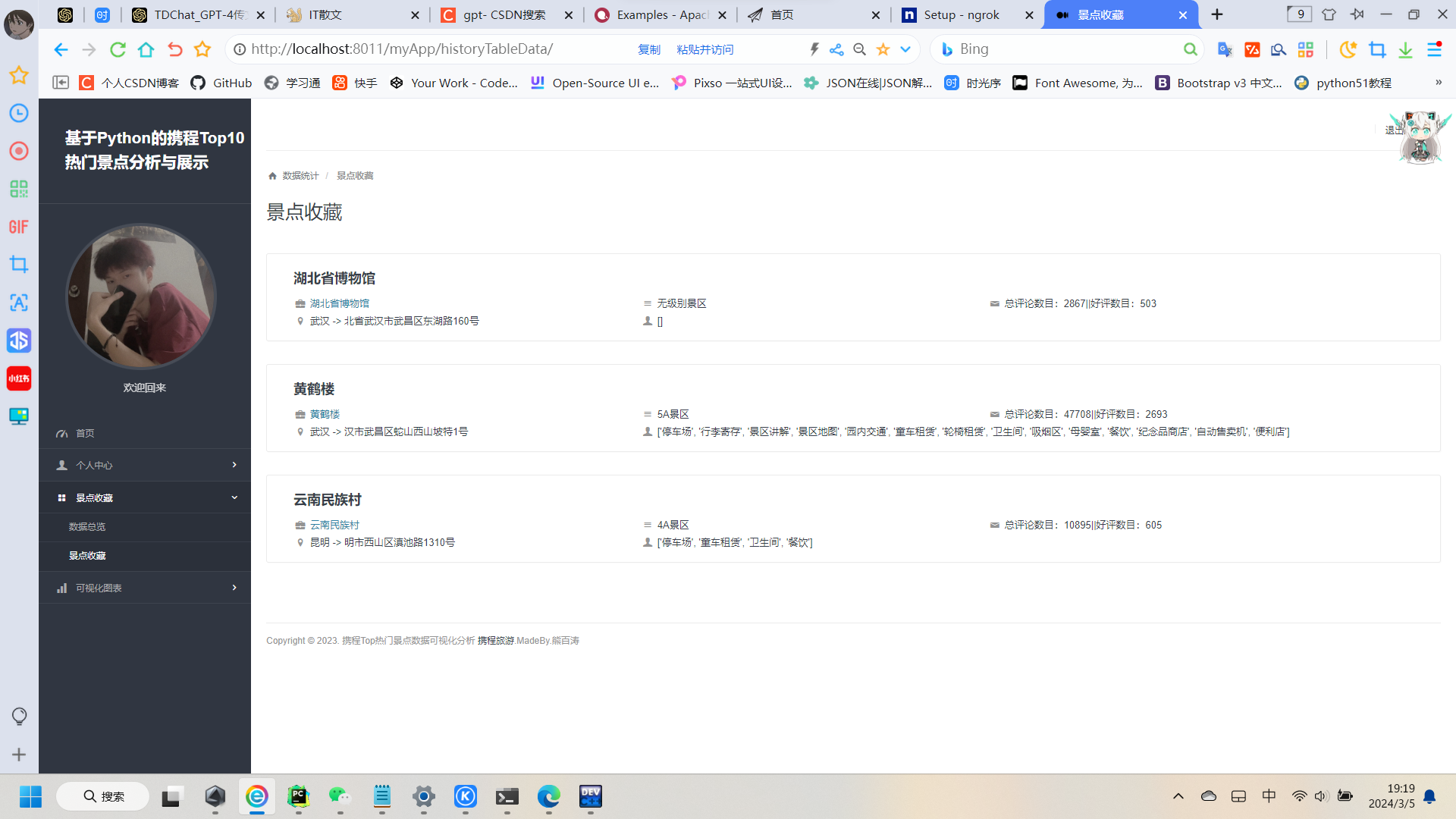
4:数据收藏
这个是有一点难度的,实现点击收藏景点就可以把数据库传递显示在收藏页面(技术本质时,点击收藏按钮将该数据保存存储一个新的数据库里),我们根据ID来获取当前点击的对象,然后创建新的数据库,这里的数据库表的建立就会显得尤其重要啦,这里需要用到ForeignKey外键关联的细节啦,
这里比如我们收藏的数据存在数据库History里,然后该项目另外还有两个数据库(景点Places,用户User),我们看一下代码就知道啦:代码:
class History(models.Model):id = models.AutoField('id',primary_key=True)place = models.ForeignKey(Places,on_delete=models.CASCADE)user = models.ForeignKey(User,on_delete=models.CASCADE)count = models.IntegerField("点击次数",default=1)class Meta:db_table = "history"class Meta:db_table = 'History'verbose_name_plural = '收藏管理'关联景点表使用户我们展示景点表中的每一个字段的具体信息,关联用户是因为我们使用缓存在辨别每一位不同的用户他们收藏的数据肯定也不一样,另外我们按照一个景点点击的次数多少来从在前端页面上到下排列。
5:可视化图表
可视化图表我是使用Echarts来呈现的,当然这个可视化展示的工具有很多大家可以自己决定使用哪一款(pyecharts,matplotlib,mapbr...),做过可视化的同学都知道,echarts他的可视化的数据信息有多种数据结构的比如单列表,列表里面嵌套字典,字典里面嵌套字典等,所以我们只需要将数据库里的数据拿出来处理成我们需要的样子即可啦,由于我这这个项目里的数据图表也不算少,所以我就只拿有两个图表来讲解举例:
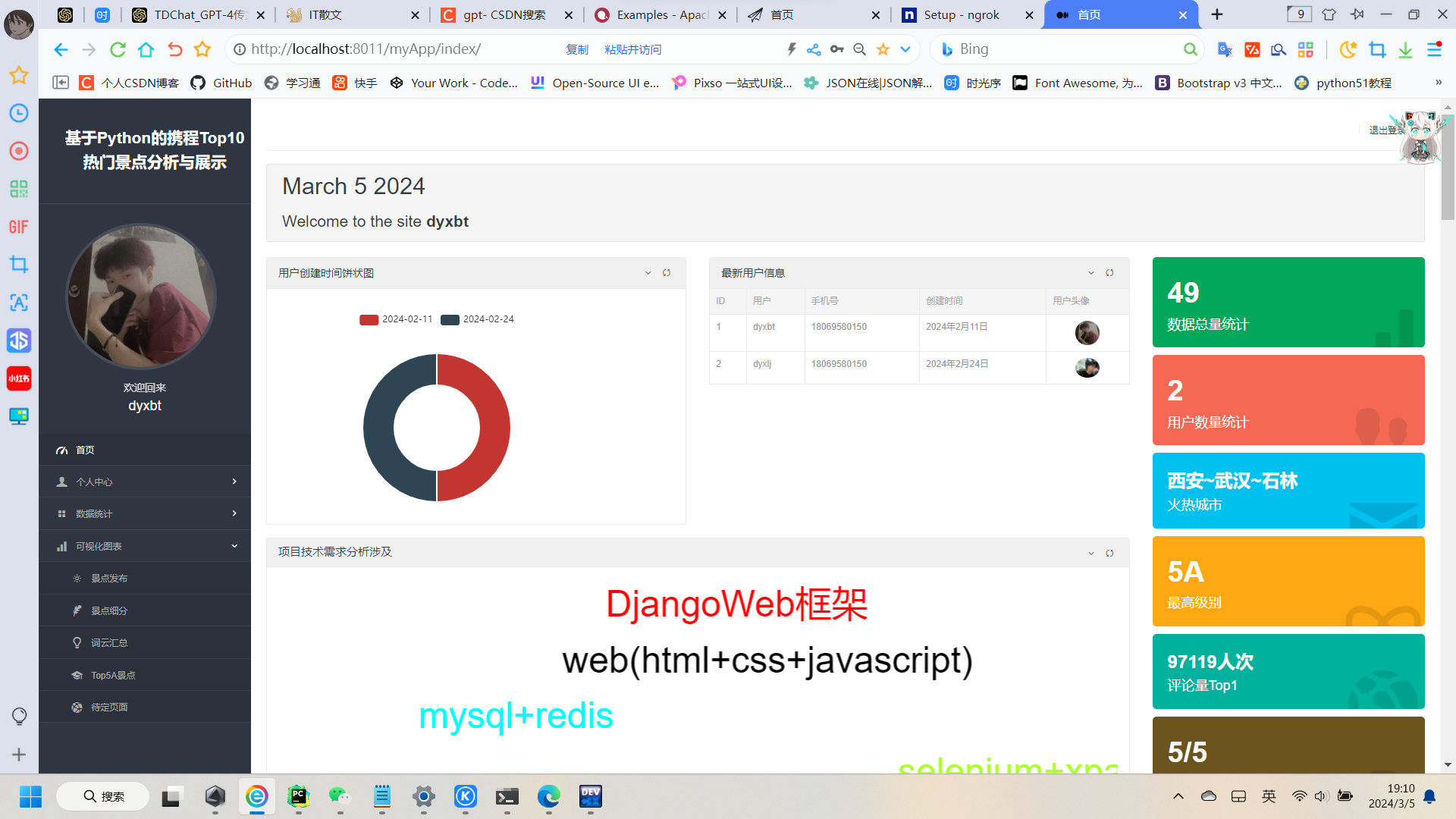
比如下面的这种可视化的图,这个没有怎么设计到图表的内容:
效果图如下:
代码:
def index(request):users = User.objects.all()data = {}for u in users:if data.get(str(u.time),-1) == -1:data[str(u.time)] = 1else:data[str(u.time)] += 1result = []for k,v in data.items():result.append({'name':k,'value':v})timeFormat = time.localtime()year = timeFormat.tm_yearmonth = timeFormat.tm_monday = timeFormat.tm_mdaymonthList = ["January","February","March","April","May","June","July","August","September","October","November","December"]username = request.session.get("username").get('username')useravatar = request.session.get("username").get('avatar')newuserlist = User.objects.all()places=Places.objects.all()# 数据总量placeslength=len(places)# 用户总量userlength=len(User.objects.all())# 火热城市 h(例:)为北京,上海,深圳hotcitylist=[]hotcity=places.order_by('-hot')[0:3]for h in hotcity:hotcitylist.append(h.city)strres=''for h in hotcitylist:strres= strres+h+"~"hotcitylist=strres[:-1]# 最高级别"""levellist=[]for p in places:levellist.append(p.level[0])levellist=levellist.sort(reverse=True)levellistres=levellist[0] # 为最高等级5A"""levellistres='5A'# 评论量最高totalaccountres=places.order_by('-totalaccount')[0]totalaccountlistres=totalaccountres.totalaccount# 评分最高scoreres=places.order_by('-score')[0]scorelistres=scoreres.scoregoodaccountrate=places.order_by('-goodaccountrate')[0]goodaccountrate=goodaccountrate.goodaccountratecontext={'userTime':result,'year':year,'month':monthList[month-1],'day':day,'useravatar':useravatar,'username':username,'newuserlist':newuserlist,'placeslength':placeslength,'userlength':userlength,'hotcitylist':hotcitylist,'levellistres':levellistres,'totalaccountlistres':totalaccountlistres,'scorelistres':scorelistres,'places':places,'goodaccountrate':goodaccountrate}return render(request,'index.html',context)
获取数量:
# 数据总量 placeslength=len(places) # 用户总量 userlength=len(User.objects.all())
Top最高的数据可以直接orderby(-字段)[0]即可,获取该字段的最高的一条数据然后获取该数据的该字段值,火热城市同理,按照hot热度排列取前3个对象数据,然后取出该3条数据的该字段值,然后可以利用字符串拼接的方法做城市之间的~连接展示。
接下来看这个图片:
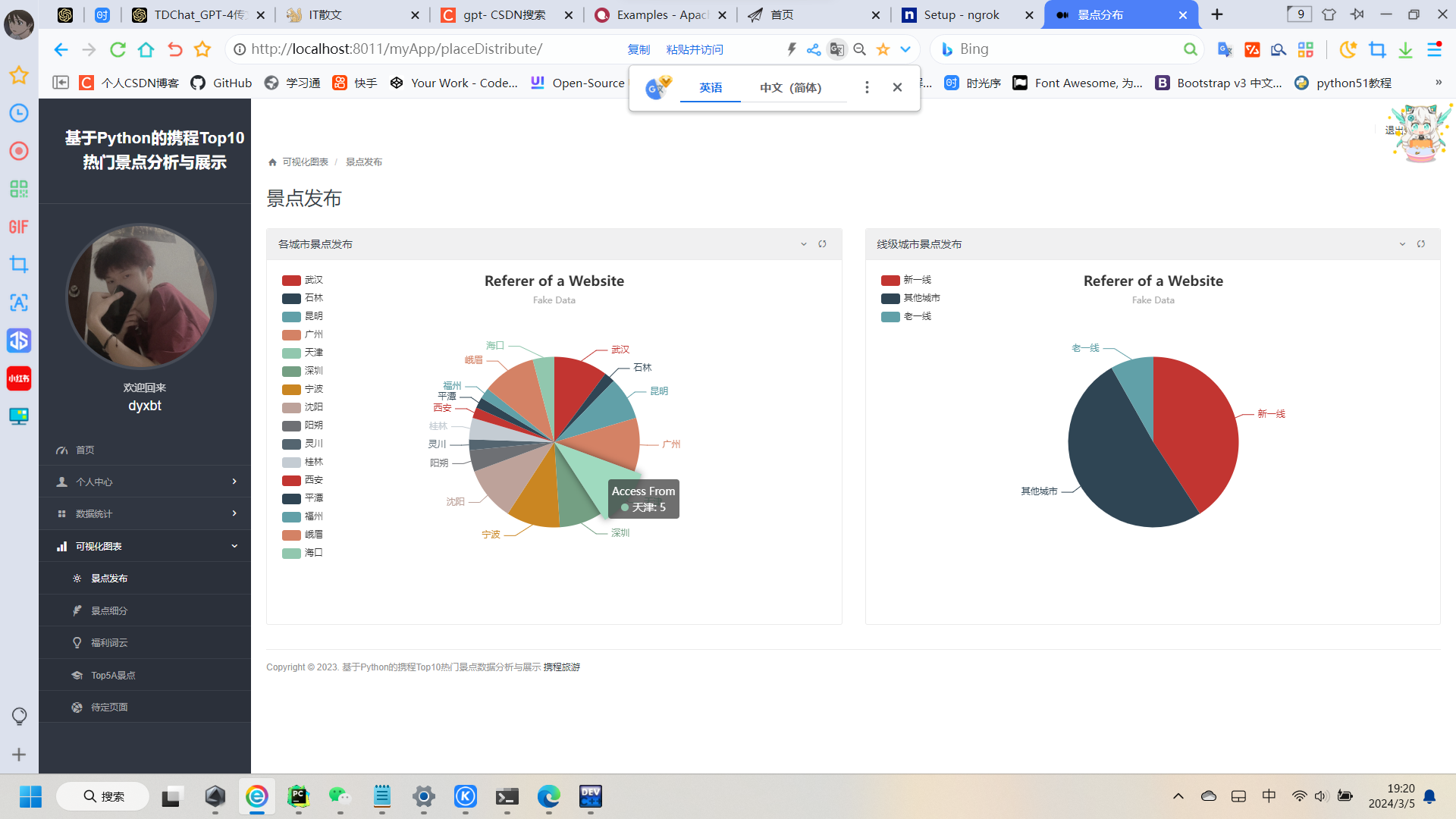 这个图片是Echarts可视化工具的常见的饼图:他Echarts源数据是这样的(如下图:)
这个图片是Echarts可视化工具的常见的饼图:他Echarts源数据是这样的(如下图:)
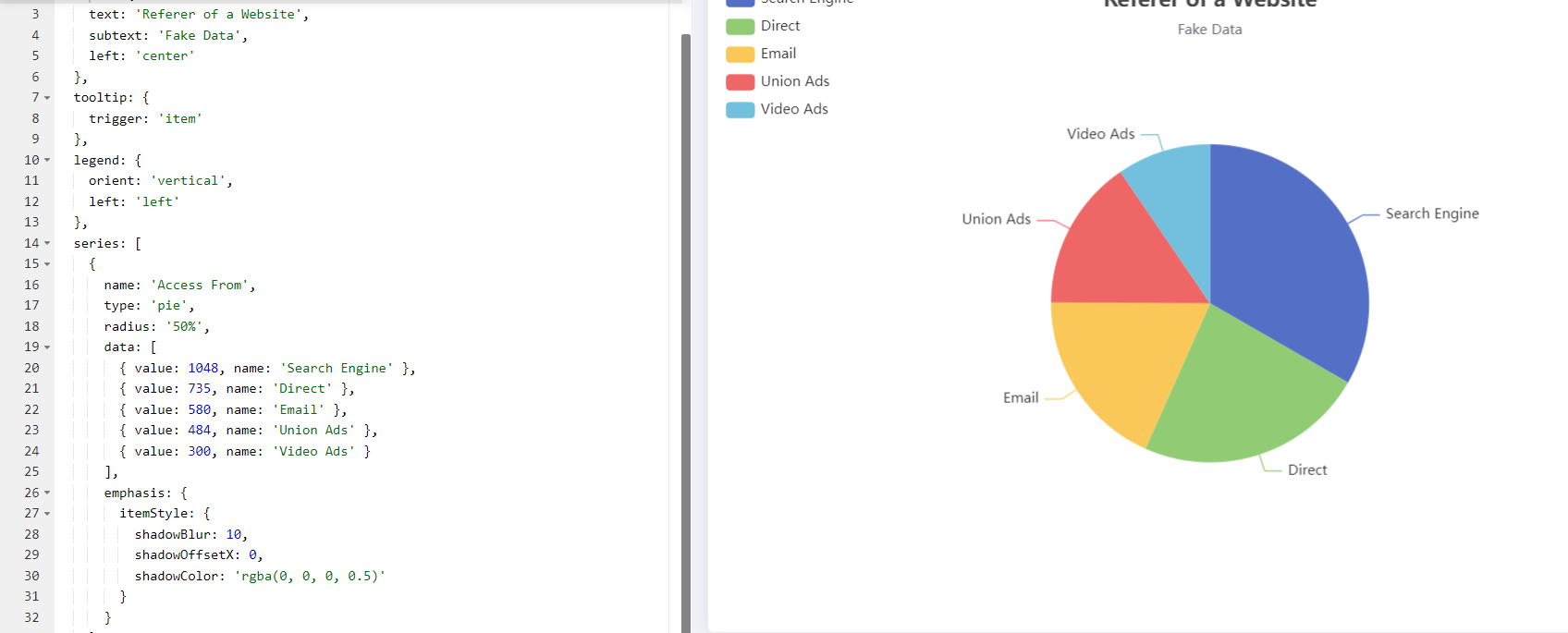
在data里面,是一个列表里面嵌套字典的形式,所以我们针对我们这个项目需要处理处理成[{北京:2},{上海:3},{杭州:5}......]既表达每个城市有多少景点,所有我们使用如下代码:
places = Places.objects.all();dict1={};result1=[];dict2={};result2=[];
for i in places:if dict1.get(i.city,-1)==-1:dict1[i.city]=1else:dict1[i.city]+=1
for k,v in dict1.items():result1.append({'value': v,"name":k})
这段代码首先从数据库中获取所有的 Places 对象,然后使用两个字典 dict1 和 dict2 和两个列表 result1 和 result2 进行处理。
-
places = Places.objects.all();:通过Places.objects.all()获取数据库中所有的Places对象,并将其存储在places变量中。 -
dict1 = {}; result1 = []; dict2 = {}; result2 = [];:初始化了两个空字典dict1和dict2,以及两个空列表result1和result2。 -
for i in places::遍历places中的每个Places对象。 -
if dict1.get(i.city, -1) == -1::检查dict1中是否存在键为i.city的条目,如果不存在,返回-1;存在则返回对应的值。-
如果返回值为
-1,说明dict1中没有i.city这个键,这时将i.city作为键,初始化其值为1。 -
如果返回值不为
-1,说明dict1中已经存在i.city这个键,这时将对应的值加1。
-
-
for k, v in dict1.items()::遍历dict1中的每一对键值对。 -
result1.append({'value': v, "name": k}):将每个城市的数量v和城市名称k作为键值对添加到result1列表中,形成字典的列表结构。
综上所述,该代码的功能是统计数据库中每个城市出现的次数,并将结果以字典列表的形式存储在 result1 中。
其他类推(直接上效果图):

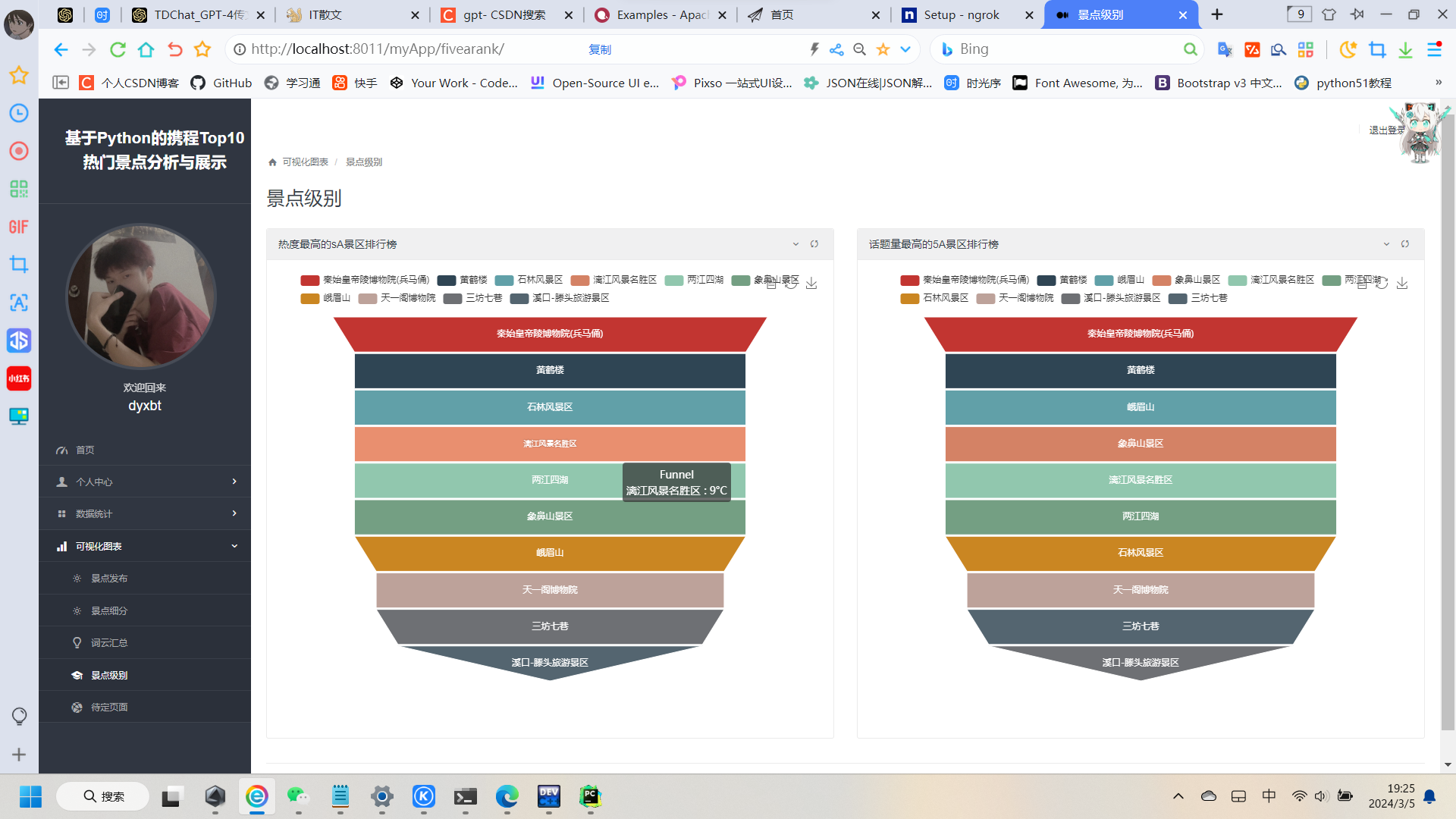
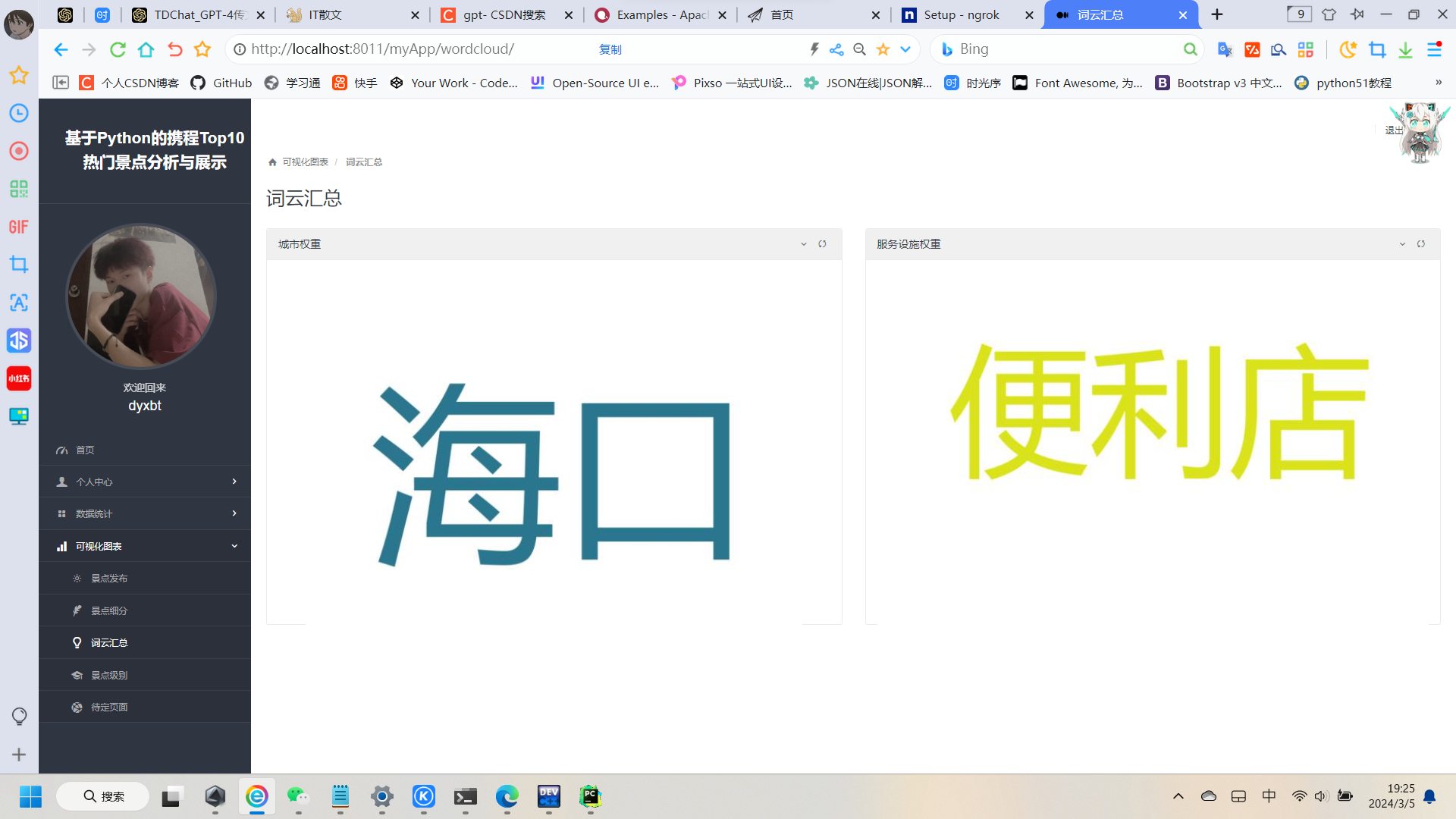
最后需要本项目的同学可以私信我或者下面加我微信~
这篇关于基于Django的携程网Top热门景点数据可视化分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





