本文主要是介绍Deep Learning for Classification of Hyperspectral Data: A Comparative Review,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Deep Learning for Classification of Hyperspectral Data: A Comparative Review
原文内容较丰富,仅摘取部分用于个人学习
INTRODUCTION
由于大多数高光谱传感器的空间分辨率较低,因此为计算机视觉而设计的深度学习技术不容易转移到高光谱数据中,因为在大多数情况下,光谱维度胜过空间信息。与光学图像相比,数据的volume相似,而结构完全不同。此外,低空间分辨率实际上限制了可用于训练统计模型的样本数量。
这也增加了监督学习中所需的注释过程的难度,因为混合像元的存在。为了将深度学习用于高光谱图像处理,这两点是需要解决的主要挑战。
HYPERSPECTRAL IMAGING: PRINCIPLES AND RESOURCES
A. Hyperspectral imaging principles in a nutshell

B. Reference datasets
- Pavia : It is divided in two parts: Pavia University (103 bands, 610 × 340px) and Pavia Center (102 bands, 1096 × 715px). 9 classes of interest are annotated covering 50% of the whole surface. 常用数据集
- Data Fusion Contest 2018 (DFC2018):It covers a [380–1,050] nm spectral range over 48 contiguous bands at 1 m GSD. 20 classes of interest are defined.
- Indian Pines:a 145 × 145px image with 224 spectral bands. 16 classes. Water absorption bands (104→108, 150→163 and 220) are usually removed before processing.

- Dataset summary:就标准光学影像而言,现有的数据集很小。 而且,由于传感器的多样性和后处理方法,不可能同时在不同的数据集上训练算法。
III. HYPERSPECTRAL IMAGE ANALYSIS ISSUES AND STANDARD APPROACHES
A. Pre-processing and normalization
处理高光谱图像往往需要对数据进行预处理,除了大气校正和几何校正之外,还需要通道选择和标准化
- band selection: 根据传感器的不同,某些光谱带可能难以处理,或者包含会改变光谱形态的异常值。 例如,我们经常删除与吸水率有关的谱带,低信噪比和饱和值的谱带。 这不仅通过减轻数据中存在的噪声来提高分类器的鲁棒性,而且还有助于减轻维数灾难。 还可以通过删除无用的频段来进行频段选择。 使用主成分分析(PCA)[14]或mutual informatio[15]。 但是,频带选择应谨慎进行。无监督降维有时会导致性能比使用原始数据差,因为它可能会删除对压缩无用但对分类有区别的信息。
- Statistical normalization
我们用Xi表示单个光谱,而用I表示整个图像。 这些策略是:
(1)Spectral Angle Mapper (SAM)
(2)Normalizing first and second-order moments. 可以对每个通道独立地做,但是会导致 squashes the dynamics in the spectral dimension (减弱通道间的相对变化).也可以对整体做:
I = I − m I σ I . I = \frac{I-m_I}{\sqrt{\sigma_I}}. I=σII−mI.
(3) I = I − m i n ( I ) m a x ( I ) − m i n ( I ) . I = \frac{I-min(I)}{max(I)-min(I)}. I=max(I)−min(I)I−min(I).
最后,为了最大程度地减少离群值的影响并获得平衡的图像动态,在给定阈值上裁剪图像值也很普遍: m I ± 2 × σ I m_I\pm2\times\sqrt{\sigma_I} mI±2×σI
B. Spectral classification
分类高光谱数据的最直接方法是将其视为一组一维光谱向量。因为高光谱图像精细的光谱分辨率和低的空间分辨率,所以这是有意义的。每个像素对应一个光谱特征,即一个可以拟合统计模型的离散信号。
1)unmixing:高光谱图像的低共空间分辨率往往会导致混合像元的情况。假设 S 1 , . . . , S n S_1,...,S_n S1,...,Sn为端元 (end members),则有:
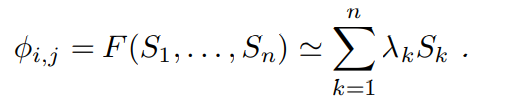
我们可以假设F是线性组合,其中权重系数 λ k λ_k λk对应于所观察区域中材料k的比例。
高光谱数据分类的一种方法就是解混[18],即通过计算其丰度图在观察区域中查找单个物质。丰度图对应于端元对每个像素的比例贡献,即混合像元的分解系数。
2) Dimensionality reduction:
在给定空间分辨率的情况下,邻域强度高度相关,因此频谱特征包含大量冗余信息
降维的目标是解决维度灾难,并简化表示空间,以简化学习阶段。
C. Spatial-spectral classification
…
IV. DEEP LEARNING FOR HYPERSPECTRAL DATA
A. Pre-processing and normalization
用于深度学习的预处理和规范化过程与用于标准机器学习的过程相似。 但是,值得注意的是,大多数工作并不使用频带选择或饱和频谱去除,而是相反地依赖于神经网络的鲁棒性。
对于解混,现在一种标准的,无监督的方法[38],[39]包含一个具有两个堆叠式auto-encoder:第一个用于降噪,第二个通过执行稀疏性约束进行实际的解混。
B. Spectral classification
- Supervised learning: 1-D CNN, RNN
- Unsupervised learning:auto-encoders
C. Spatial-spectral approaches
-
1D or 2D Convolutional Neural Networks:
将深卷积网络用在高光谱图像的一种流行方法是减小光谱维度,以缩小高光谱和RGB图像之间的gap。
a) Supervised learning:因此,一些方法是先用PCA降维,再输入到2D CNN里面。这些方法的缺点之一是它们试图使高光谱图像相似于RGB图像,即,迫使高光谱数据进入常规的计算机视觉框架。 但是,这样做可能会浪费高光谱成像的特定属性,尤其是在使用无监督且不受控制的尺寸缩小时。
为了解决这个问题,[51],[52]提出了另一种方法。 他们没有处理整个超立方体,而是引入了两个CNN:一个1D CNN,它沿辐射方向提取光谱特征,以及一个2D CNN,它学习了空间特征。 然后将来自两个模型的特征进行合并,并馈入分类器。
b) Unsupervised learning
…
总的来说,spatial-spectral classification 包括两个部分,即:
(1) 根据辐射光谱得到光谱特征
(2) 根据空间邻域得到空间特征 -
2D+1D CNN:
a) Supervised learning: 为了解决降维问题,一些研究尝试设计交互的空间和光谱的卷积来 reduce the size of the feature maps.
b) Unsupervised learning: …
最后,作者突出了一下文献[49]“Going Deeper with Contextual CNN for
Hyperspectral Image Classification”的工作 -
3D CNN: 比起2D CNN,3D CNN看起来更适合处理高光谱数据。此外,对于1D或2D+1D CNN, 3D CNN将这两种模式识别策略结合成一个滤波器,所需的参数和层数更少。They can learn to recognize more complex 3D patterns of reflectances: co-located spectral signatures, various differences of absorption between bands, etc.
D. Comparative Study of Deep Learning Architectures for
Hyperspectral Data
- Deep Learning for Hyperspectral Toolbox: 开源了一个用于高光谱分类的工具箱 DeepHyperX
- Best practices:根据数据集和应用程序,可以按照以下准则选择模型:
•如果数据集是呈现空间相关性的图像,则在大多数情况下,二维方法优于逐像素分类器。对于高光谱图像,3D CNN将能够利用数据所有三个维度的相关性
•更大的模型意味着需要更多的参数来优化,进而需要更多的训练样本。
•大卷积核往往较慢,尤其是在3D中。 大多数实现针对小型2D内核进行了优化。
•全卷积网络效率更高,因为它们可以一次预测几个像素。 而且,由于没有全连接层,这意味着它们的参数要少得多,因此更容易训练。
•非饱和激活功能(例如ReLU)可减轻消失的梯度,并帮助构建更深的网络,同时比sigmoid或tanh替代方案更快地进行计算。
在具体的实施中,作者讲的很详细:从学习率调整策略;CNN的初始化;数据增强(翻转);样本不均衡;交叉验证等方面都进行了阐述。 - Experiments:
作者首先对前人的实验设置进行了总结:
• Most papers divide the datasets in a train and test splits by
randomly sampling over the whole image. A few papers
(e.g. [43], [77]) use the standard train/test split from the
IEEE GRSS DASE initiative.
• Some authors consider only a subset of the classes.
This is especially prominent for Indian Pines, where the
classes with less than 100 samples are often excluded,
e.g. in [42], [49].
• Even when the train/test splits are done the same way,
the number of samples in the train set might vary. Some
authors use 20% of all the training set, while others use
a fixed amount of samples for each (e.g. 200 samples for
each class).
• Some authors further divide the training set into a proper
training set and a validation set for hyper-parameters
tuning, while others perform the tuning directly on the
test set.
作者认为在整个图像上随机采样训练样本不适于解决现实问题。 此外,这不能说明模型的泛化能力。 实际上,相邻像素将高度相关,这意味着测试集将非常接近训练集。(确实,这是很多高光谱分类文章中的一个共有的槽点)
作者复现了一些代表性文章,对实验结果的分析很有意思。
E. Perspectives
…
这篇关于Deep Learning for Classification of Hyperspectral Data: A Comparative Review的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








