本文主要是介绍2022清华暑校笔记之L2_2 CNN和RNN基础介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2022清华大学大模型交叉研讨课
L2 Neural Network basics
1 Recurrent Neural Networks
循环神经网络RNNs
1.1 RNN基础
序列数据 顺序记忆(大脑更易识别)
输入通常是不定长的数据,h为不同时间步的变量,y为输出
RNN结构单元
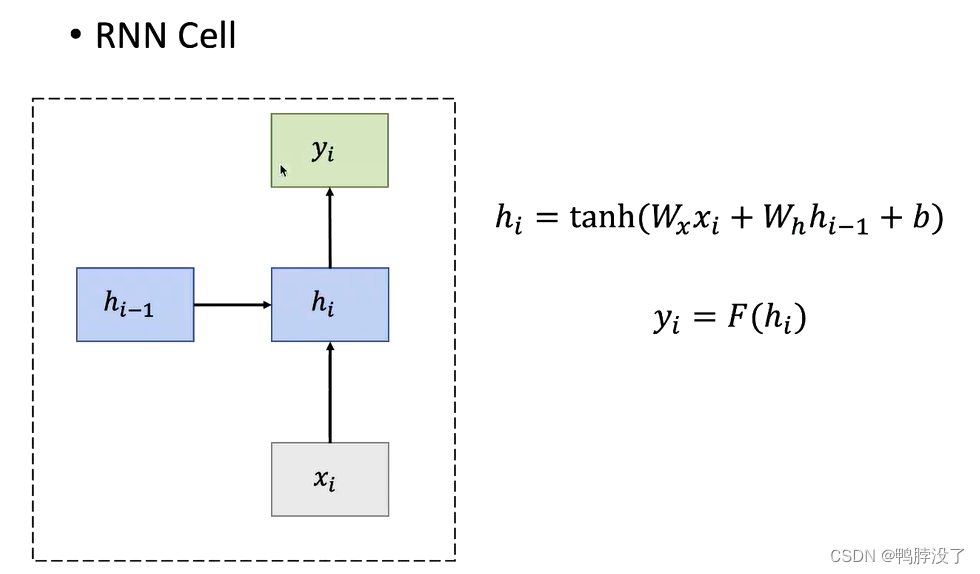
顺序记忆:每一个时间步的hi都是由上一个隐藏状态的内容,h0需要自己初始化的。
- 应用:
- 序列标签(标注属性)
- 序列预测(预测天气)
- 图像描述(给定图片生成句子)
- 文本分类(区分情感)
- 优点
- 可以处理任意长度的输入
- 模型的大小不会因为输入的长短而改变
- 参数共享
- 后面的计算会使用之前步骤的信息
- 缺点
- 时间较慢
- 实际上后面的计算很难再用到之前的数据
- 梯度消失(常出现)或梯度爆炸
1.2 RNN变体
思路:优化单元,将隐藏层变复杂
1.2.1 GRU(Gated Recurrent Unit)
将门控机制引入RNN,权衡过去的信息和当前输入信息的权重。观察式子我们发现,此处的W均为专属的权重
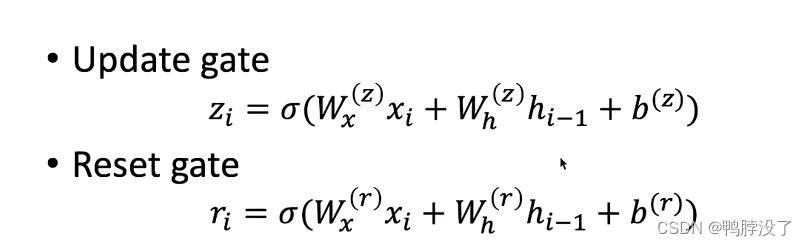
- 重置门
h ~ i = tanh ( W x x i + r i ∗ W h h i − 1 + b ) \tilde{h}_{i}=\tanh \left(W_{x} x_{i}+r_{i} * W_{h} h_{i-1}+b\right) h~i=tanh(Wxxi+ri∗Whhi−1+b)
考虑到上一层的状态对当前的激活,我们可以得到一个临时的hi.
如果我们的ri接近于0的话,我们会发现hi和上一个hi的关系很弱。 - 更新门
h i = z i ∗ h i − 1 + ( 1 − z i ) ∗ h ~ i h_{i}=z_{i} * h_{i-1}+\left(1-z_{i}\right) * \tilde{h}_{i} hi=zi∗hi−1+(1−zi)∗h~i
权衡新得到的hi和hi-1之间的影响,从而得到传输到下一层的hi。
当zi接近于1的时候,hi和hi-1完全相等;当zi接近于0的时候,我们可以直接采用激活后的新hi。 - 演示
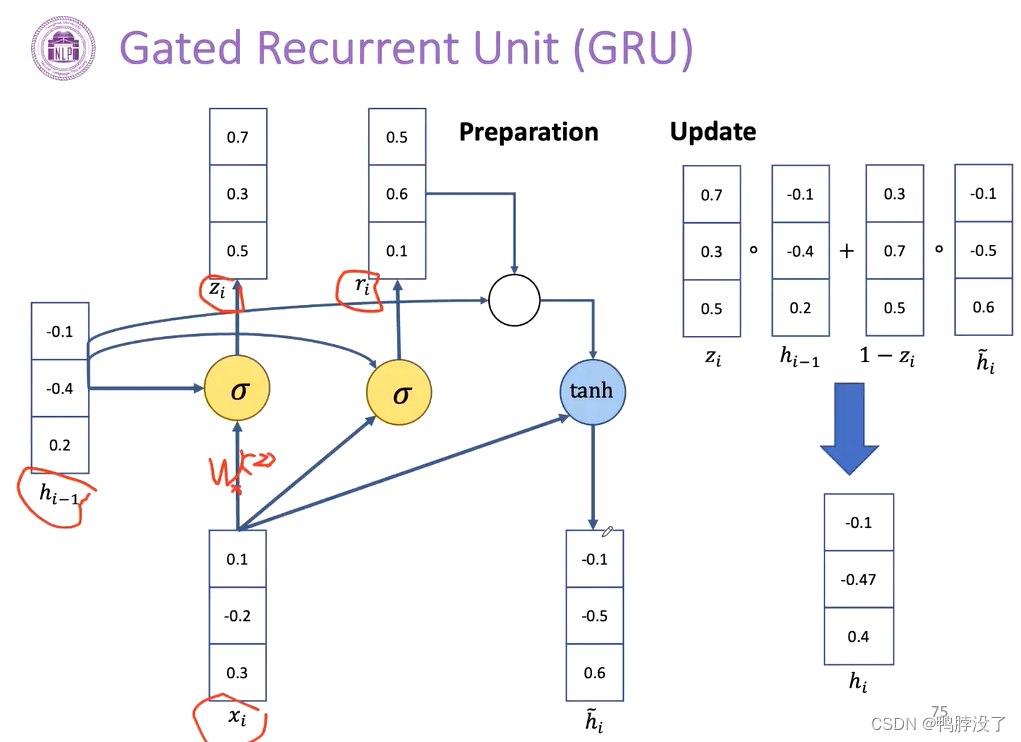
门控机制的好处:可以控制不同地方的关联性(快捷地建立较远的关系);减少数量
1.2.2 LSTM(Long Short-Term Memory)
- Ct
- 新增了一个Ct表示cell的状态,用来学习长期的依赖关系。
- Forget gate ft 遗忘门
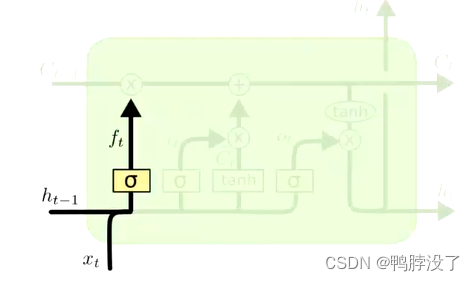
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right) ft=σ(Wf⋅[ht−1,xt]+bf)
决定上一个状态中的哪些信息可以从cell中移除。计算方式: 当前的状态和上一层隐藏层状态。最后得到的ft为0-1区间内。如果为0,表示过去的信息直接丢弃。 - 输入门
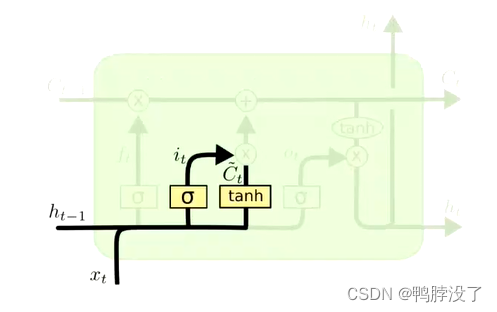
决定哪些信息可以存入cell状态中- it:输入门参数
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_{t}=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right) it=σ(Wi⋅[ht−1,xt]+bi) - C ~ t \tilde{C}_{t} C~t为待选的ct变量
C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_{t}=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right) C~t=tanh(WC⋅[ht−1,xt]+bC)
- it:输入门参数
- 更新cell state
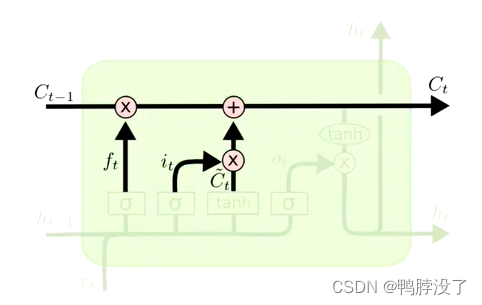
- C t = f t ∗ C t − 1 + i t ∗ C ~ t C_{t}=f_{t} * C_{t-1}+i_{t} * \tilde{C}_{t} Ct=ft∗Ct−1+it∗C~t
- 首先更新旧的cell state:将遗忘门乘上一层cell state,来决定哪些信息需要摒弃
- 将输入门和待选的新向量相乘,来决定当前哪些信息需要加入下一层的信息cell state。
- 输出门
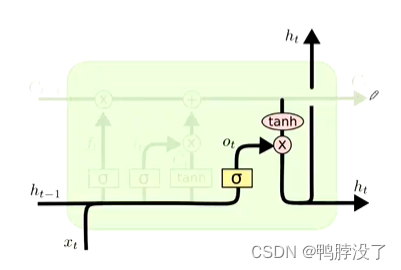
输出门决定哪些信息可以输出
o t = σ ( W o [ h t − 1 , x t ] + b o ) o_{t}=\sigma\left(W_{o}\left[h_{t-1}, x_{t}\right]+b_{o}\right) ot=σ(Wo[ht−1,xt]+bo)
h t = o t ∗ tanh ( C t ) h_{t}=o_{t} * \tanh \left(C_{t}\right) ht=ot∗tanh(Ct)
(可以理解成调整一些信息来适应单词的表述)
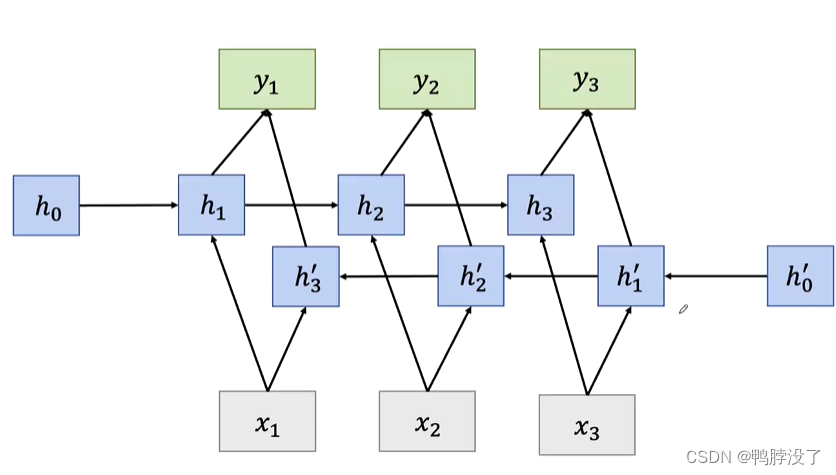
1.2.3 Bidirectional RNNs(双向RNN)
- 前言
- 在传统RNN任务中,每一个隐藏状态变量都是从之前时间中的状态变量和当前的输入决定的
- 但是很多应用中我们会依赖于整个输入序列
- 例子:手写/语音识别
- 示例图
2 Convolutional Neural Networks
卷积神经网络CNNs
2.1 前言
- 应用:
- CV任务
- NLP任务:情感分类、关系分类
- 善于提取局部和位置不变的模式
- CV:颜色、边角、纹理等
- NLP:短语和语法结构等
- 提取模式的步骤:
- 计算一个句子中所有可能的n-gram的表示
- 不依赖外部的语言学工具(如依赖解析等)
2.2 CNN结构示例
- 结构:输入层、卷积层(filter)、最大池化层(提取特征)、非线性层
2.2.1输入层
将词通过word embedding转化成向量表示。
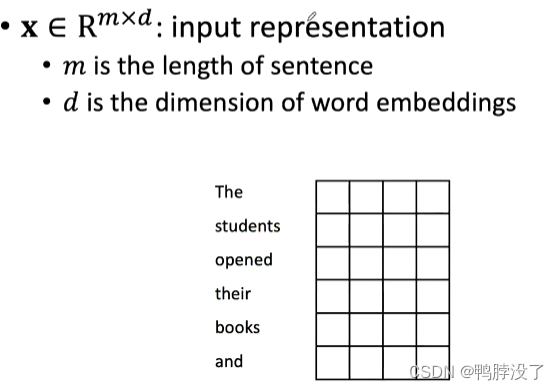
X为词向量表示矩阵,m此处为6,d为我们继续词向量表示时选取的维度。
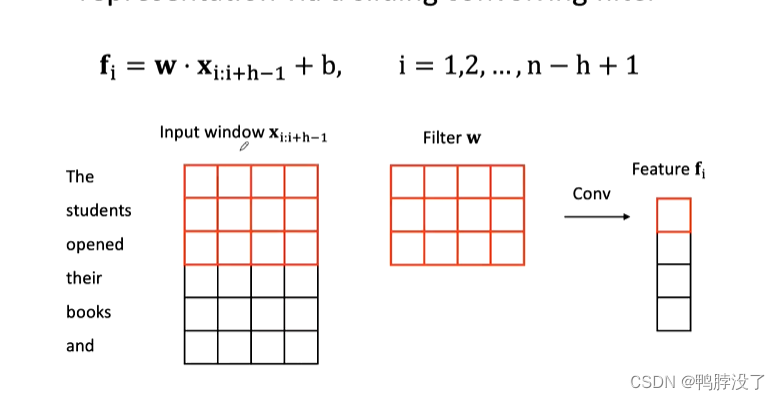
2.2.2卷积层
第二行,表示选取的N元组
W滑动的卷积核
f卷积之后的特征表示
卷积核的大小是全局参数共享的
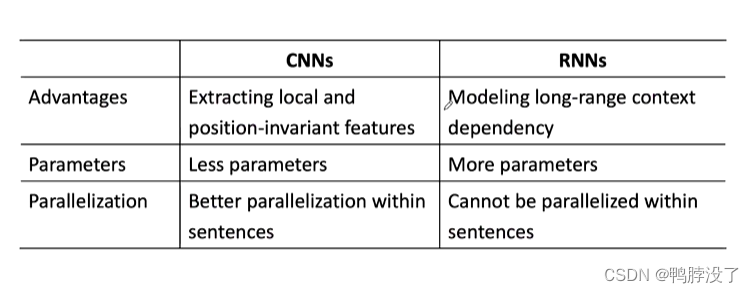
2.2.3 CNN和RNN的比较
这篇关于2022清华暑校笔记之L2_2 CNN和RNN基础介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






