本文主要是介绍2022清华暑校笔记之L2_1神经网络的基本组成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2022清华大学大模型交叉研讨课
L2 Neural Network basics
1 神经网络的基本组成
1.1 神经元
- 单个的神经元:
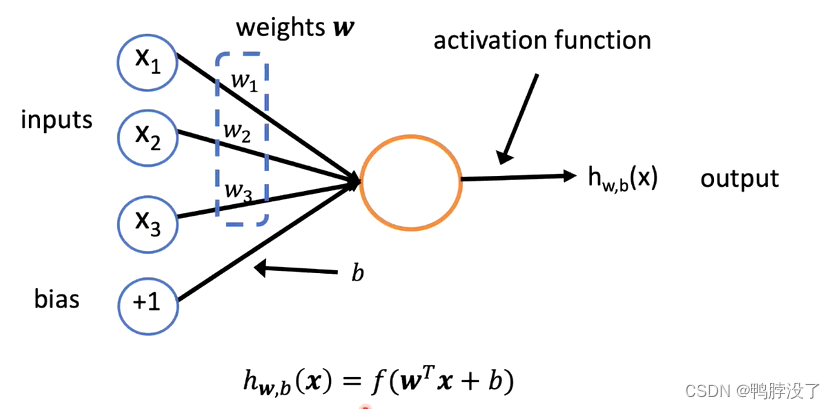
将权重向量(矩阵)和输入向量点乘,得到一个标量值,加上偏置b(标量)后送入非线性的激活函数f,得到输出。
1.2神经网络
- 多个神经元构成单层神经网络:
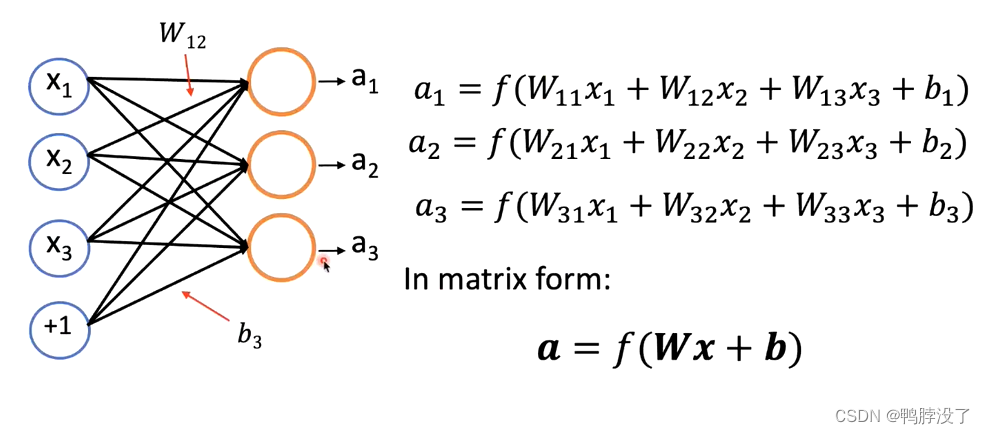
多个神经元时,权重由向量变成了矩阵(3*3),偏置b由标量变成了向量(b1,b2,b3)。 - 堆叠单层神经网络得到多层神经网络:
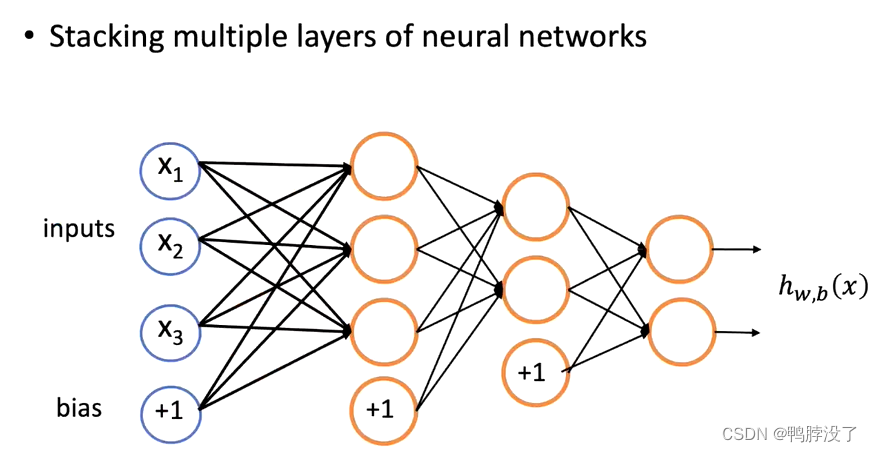
我们可以从输入开始一次计算每一层的结果,每一层的结果都是上一层的结果经过线性变化和激活函数得到的。
1.3 激活函数
- why use f?为什么要用非线性函数来激活?
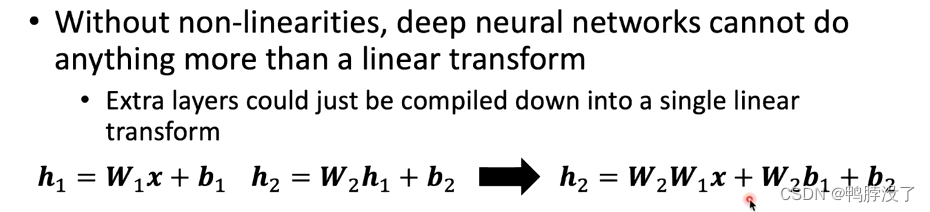
- 如图,假设我们的网络中只存在线性变换的话,两层网络之后,我们发现h2完全可以用初始的输入数据只经过一次变化后得到。
- 因此,单层的表达能力和多层的表达能力是一致的,为了防止网络的塌陷,增加网络的表达能力,来拟合更复杂的函数,我们引入非线性的网络结构。
- 常见的非线性激活函数
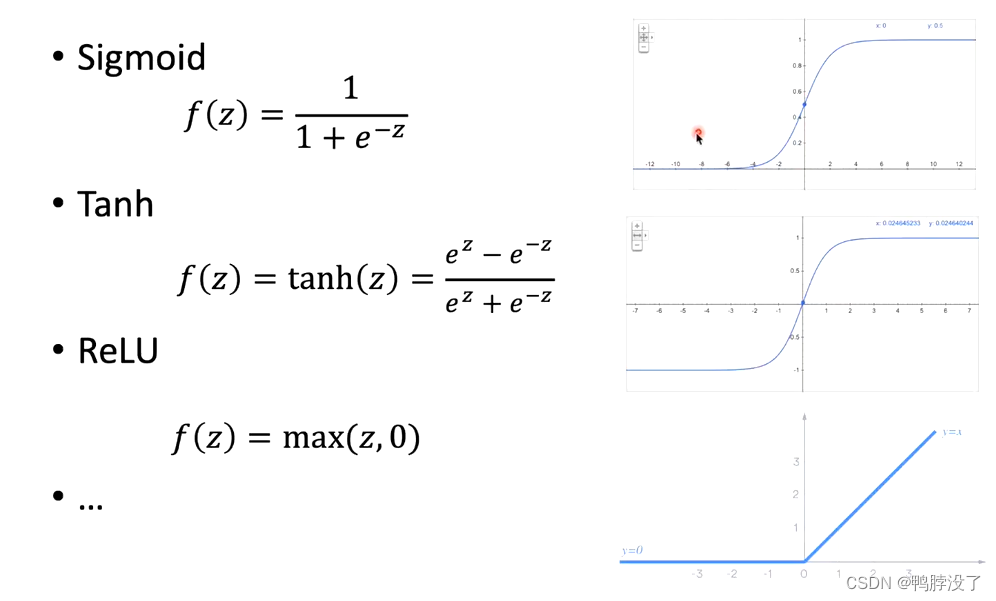
1.4 输出层
- 根据不同的输出形式确定输出层:
- linear output
- 在隐藏层后增加线性层直接输出。
- 适用于回归问题。
- Sigmoid
- 先用普通的线性层得到一个值,然后运用sigmoid激活函数,将输出压到0-1这个区间内。
- 适用于二值分类问题。
- Softmax
- 先用最后的隐层计算一个线性层,得到一个输出结果z,然后代入函数 y i = softmax ( z ) i = exp ( z i ) ∑ j exp ( z j ) y_{i}=\operatorname{softmax}(z)_{i}=\frac{\exp \left(z_{i}\right)}{\sum_{j} \exp \left(z_{j}\right)} yi=softmax(z)i=∑jexp(zj)exp(zi)。
- 目的:消除了z为负数时的影响;使得所有的输出类值和为1,得到了不同类别的概率分布。
- 常解决多分类的问题。
- linear output
2 训练
2.1 训练目标:
- 预测的目标:降低均方差(回归问题)
- 分类的目标:最小化交叉熵
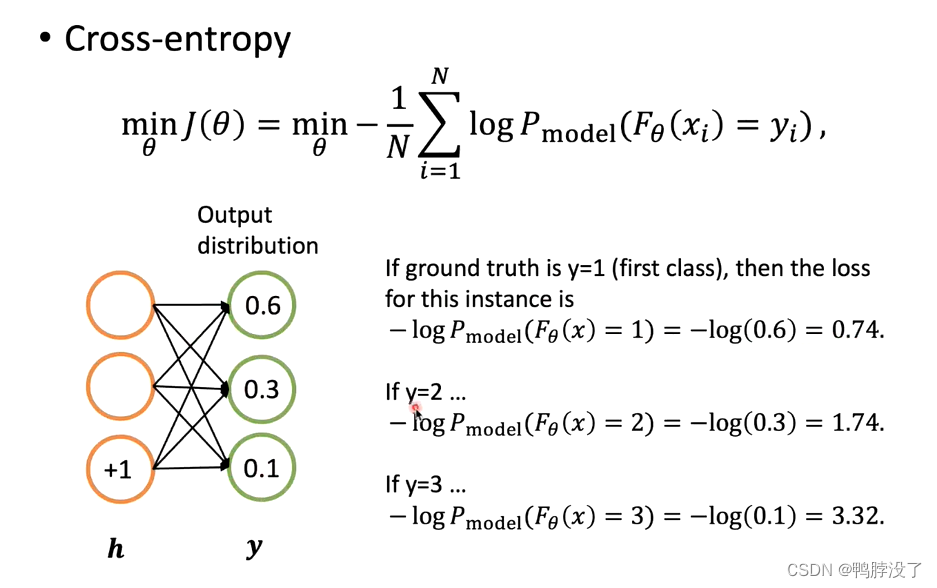
如果正确答案为第一个类别的话,我们可以计算出交叉熵为0.74;如果正确答案为第二个类别的话,可以计算出交叉熵为1.74;如果正确答案为第三个类别的话……
2.2 如何更新
- 梯度下降的概念:
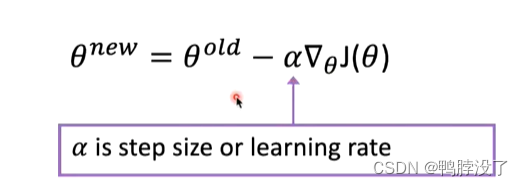
- 我们每一次缩小一点损失函数
- 每一次先计算损失函数对于参数的梯度,即得到了损失函数对于参数变化最快的地方。由于我们要取最小值,因此我们选择负方向且绝对值最大的方向。
- 梯度下降的做法:
- 对于单个输入(可以看作一维参数),求偏导
- 对于n个输入时,见下图,可以得到结果梯度矩阵。

- 梯度下降的窍门:
- 连续求导
- 反向传播算法
- 前向传播指的是按照边指向的顺序,其中有向边的作用为传递值。
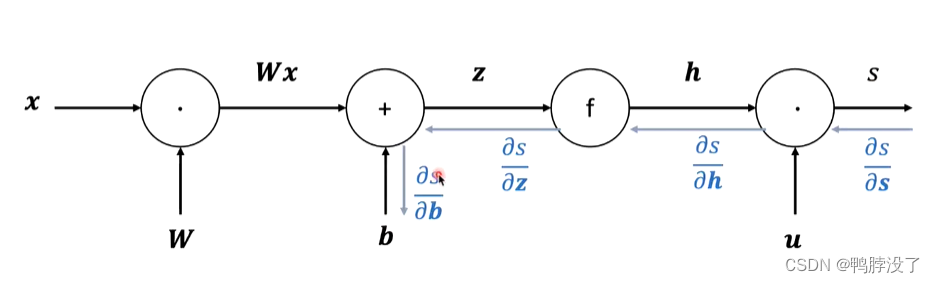
- 为了求得最后的输出对于某个输入值的梯度,我们使用和计算方向相反的方向。
- 以其中一段为例,介绍单个节点的计算方法:
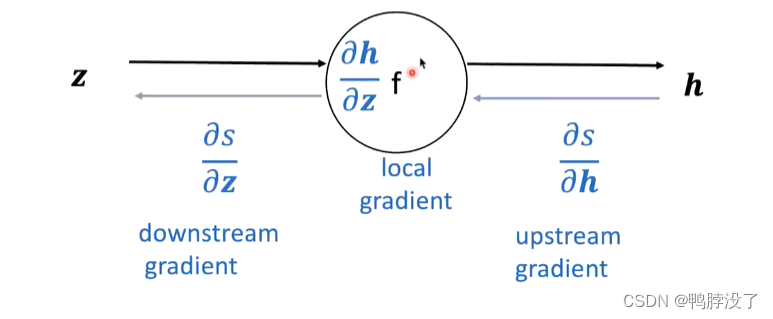
- 将上游的梯度和本地的梯度相乘,即可计算出下游的梯度,以此类推可以继续求得再下游的梯度。
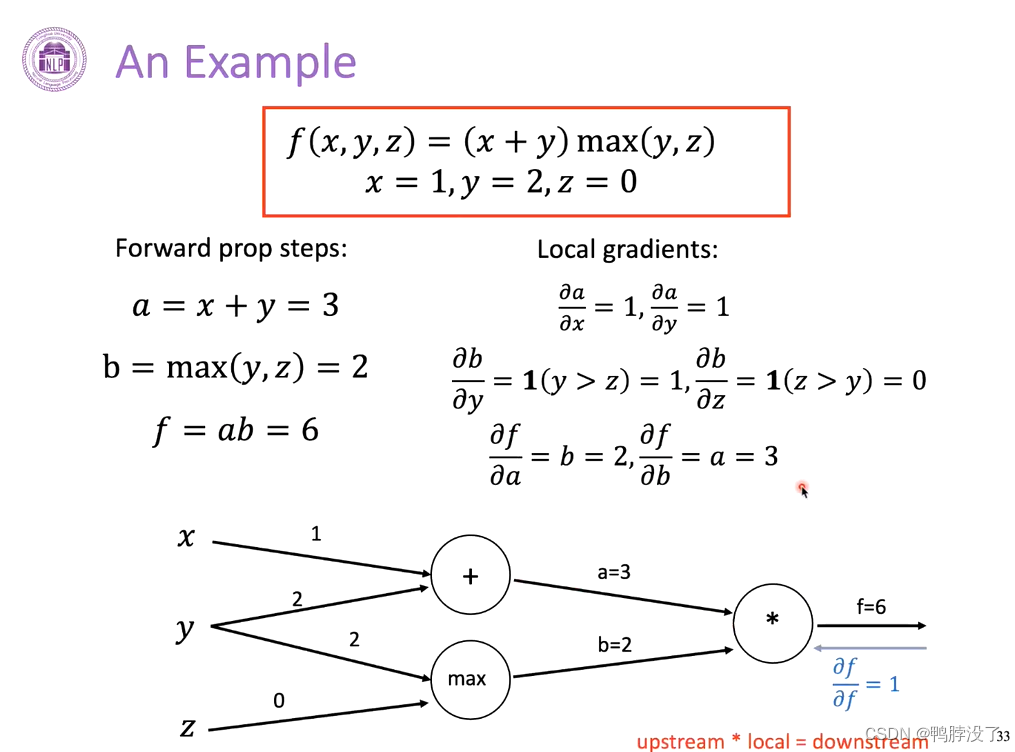
- 将上游的梯度和本地的梯度相乘,即可计算出下游的梯度,以此类推可以继续求得再下游的梯度。
- 前向传播指的是按照边指向的顺序,其中有向边的作用为传递值。
3 词项表示Word2Vec
3.1 Sliding Box:一个固定大小的滑动窗口
当窗口移动到句子的某一端时,只有target
3.2 CBOW:根据context,预测target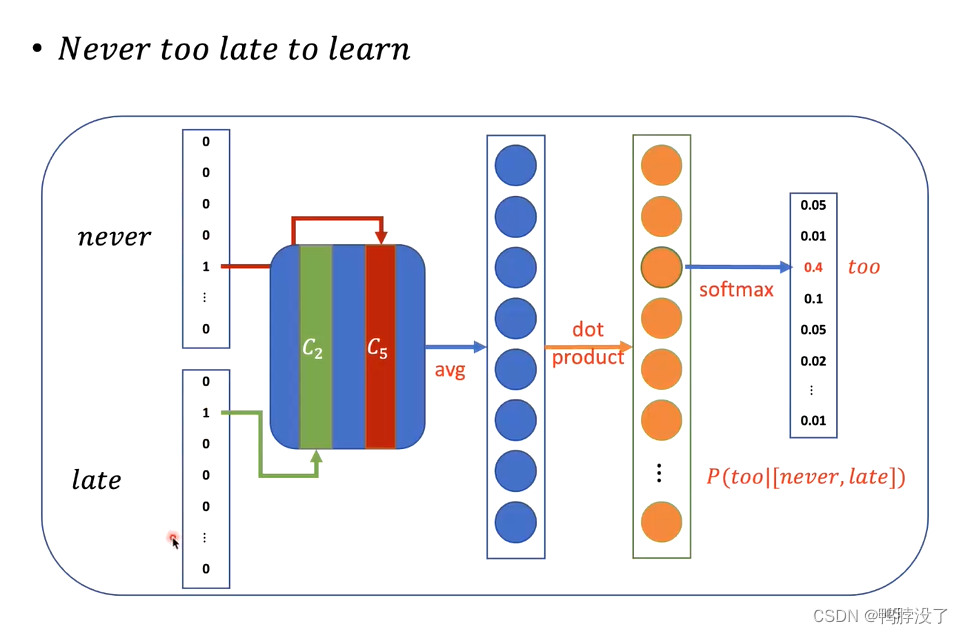
将never和late用one-hot向量表示,将这两个向量做一个平均,然后将词向量变成词表大小,最后通过softmax得到概率分布。
3.3 skip-gram:根据target,预测context
- 由于模型预测出多个结果的难度过大,因此我们将任务分解,一个一个来。
3.4 改进:
3.4.1 弊端: full softmax时,若遇到大的词表,再见过反向传播和梯度下降时,速度会比较慢。
3.4.2 两种提高计算效率的方法:
- 负采样
理解参考- 只采样一小部分,按照词的频率进行采样。
P ( w i ) = f ( w i ) 3 / 4 ∑ j = 1 V f ( w j ) 3 / 4 P\left(w_{i}\right)=\frac{f\left(w_{i}\right)^{3 / 4}}{\sum_{j=1}^{\mathbb{V}} f\left(w_{j}\right)^{3 / 4}} P(wi)=∑j=1Vf(wj)3/4f(wi)3/4 - 3/4为经验值,为了稍微提高低频词的采样频次。
- 只采样一小部分,按照词的频率进行采样。
- 分层softmax
3.4.3 Other tips:
- sub-sampling:平衡常见词和罕见词
- 常见词出现频率高,涵盖的语义不太丰富,罕见词则反之。
1 − t / f ( w ) 1-\sqrt{t / f(w)} 1−t/f(w) - 若一个词出现的频率越高,则他被去掉的可能性越大
- 常见词出现频率高,涵盖的语义不太丰富,罕见词则反之。
- soft sliding window
- 更远的词应该更少被考虑
这篇关于2022清华暑校笔记之L2_1神经网络的基本组成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






