本文主要是介绍有关于CSDN页面爬取破解的两个爬虫(编写时间20200104),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于课程设计需要编写了一系列爬虫,期中包括:
- 博客园页面+博客园搜索
- 百度搜索+百度文库
- 简书搜索+简书页面
- 爱学术搜索
具体目的就详细说明,反正就搜集一下资料和URL
下为CSDN的两个爬虫(编写时间20200104)
事先声明:CSDN页面爬虫并未完全破解,所以需要隔一段时间取一下cookie(根据其生存周期?)
-
首先是CSDN页面爬虫
-
使用前需要获取cookie中的acw_sc__v2加密码(暂时没破解,因为溯源会进入debug黑洞,比较麻烦,待完善)
-
获取方式如下:
-
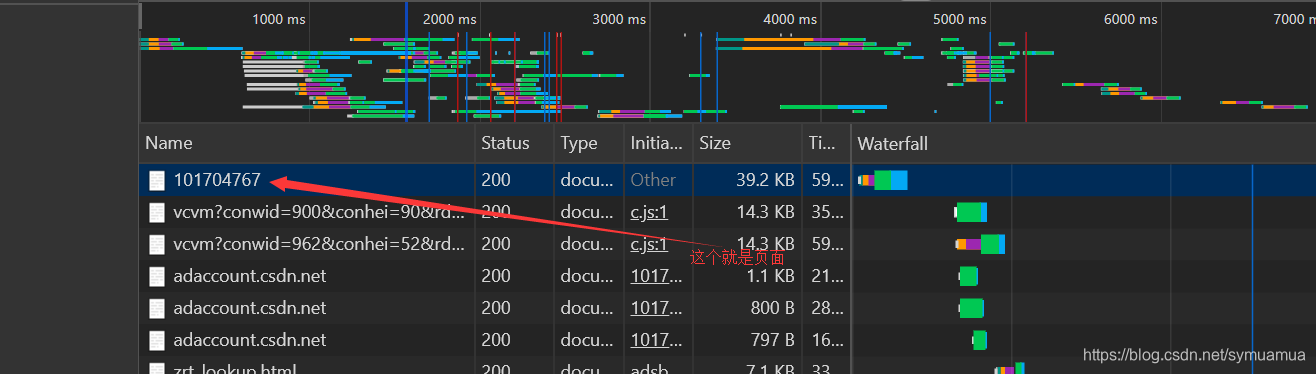
打开CSDN博文,Network模式下DOC,先Clear再刷新页面
-
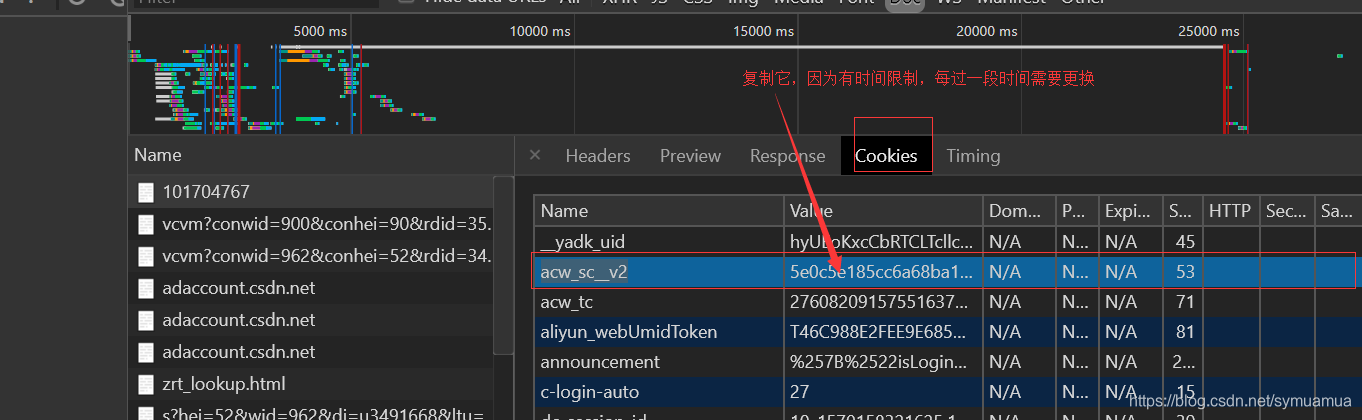
找到第一个纯数字的那个doc,点开,cookie下找到
-
找到acw_sc__v2的value,加到header中的cookie中去,即可用爬虫得到真实页面
-
下面是代码
import requests
import time
from lxml import etree
import random
import os
import jsonheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36","accept-language":"zh-CN,zh;q=0.9,en;q=0.8",# "cookie":"acw_sc__v2=5e0c4608eda0369b627288eebf26ea9b0d11bcbb""cookie": "acw_sc__v2=5e0c90c2e2e885ed5748dbfaf6b26a12f0aad2e0"}def getContent(url):try:req = requests.get(url,headers = headers)req.encoding = req.apparent_encoding# print(req.text)html = etree.HTML(req.text)title = html.xpath("//*[@id='mainBox']/main/div[1]/div/div/div[1]/h1/text()")content = []for each in html.xpath("//*[@id='content_views']/*"):con_temp = each.xpath("string(.)")if con_temp:content.append(str(con_temp))con_temp = each.xpath("img/@src")if con_temp:for eImg in con_temp:content.append("".format(eImg))return title,contentexcept:return "",""def save(title,content,name):with open("{}.md".format(name),'w',encoding='utf-8') as f:f.write(str(title[0])+'\n\n')for each in content:f.write(each+'\n')if __name__ == '__main__':url = "https://blog.csdn.net/w746805370/article/details/51312248"# 3SAT规约到独立集url = "https://blog.csdn.net/xiazdong/article/details/8258092"# 【NPC】3、3SAT规约到顶点覆盖url = "https://blog.csdn.net/xiazdong/article/details/8258086"# 证明题NP难问题:3SAT-------》独立集name = "3SAT-独立集"url = "https://blog.csdn.net/u010499172/article/details/73920646"# 几个NP-完全问题的证明name = "几个NP-完全问题的证明"url = "https://blog.csdn.net/kufaaa/article/details/54630460"title,content = getContent(url)if title is not "":save(title,content,name)else:print("访问出错,请更换acw码或者确认url试试")# 使用说明:由于CSDN中的加密机制,因此就算是静态页面,没有acw加密的码也拿不到真实数据# 故此使用时需预先获取acw_sc__v2码,它存在一定的时效性,具体获取方法见README- 接下来是中规中矩的CSDN搜索爬虫

- 这个就比较简单,没什么特别的反爬措施,直接上就完事了
import requests
import time
from lxml import etree
import random
import os
import json
import utils.Utils as sqheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}proxy_list = ['117.90.131.247:8118','171.11.32.77:9999','223.199.31.112:9999','27.191.234.69:9999','223.199.31.5:9999','60.167.135.179:9999'
]def getContent(word, proxy, page, content):print("当前第{}页".format(page))try:url = "https://so.csdn.net/so/search/s.do?p={}&q={}&t=blog&viparticle=&domain=&o=&s=&u=&l=&f=&rbg=0".format(page,word)re = requests.get(url=url, headers=headers, proxies=proxy)html = etree.HTML(re.text)tit_list = html.xpath("//dl[@class='search-list J_search']")# print(len(tit_list))for each in tit_list:temp_url = each.xpath(".//div[@class='limit_width']/a[1]/@href")[0]temp_title = each.xpath(".//div[@class='limit_width']/a[1]")[0].xpath("string(.)").replace("\"","").replace("\n","").replace(")"," ").replace("("," ").replace("\\","")temp_content = each.xpath(".//dd[@class='search-detail']")[0].xpath("string(.)").replace("\"","").replace("\n","").replace(")"," ").replace("("," ").replace("\\","")# print("temp_url={}\ntitle={}\ncontent={}\n\n".format(temp_url, temp_title,temp_content))content.append([temp_url,temp_title, temp_content])if int(html.xpath("//span[@class='page-nav']/a/@page_num")[-1]) > page:time.sleep(random.uniform(0, 2))return getContent(word=word, proxy=proxy, page=page+1, content=content)except:print("访问出错")return contentdef do(word):proxy = {"http": random.choice(proxy_list)}content = getContent(word=word, proxy=proxy, page=1, content=[])# for each in content:# print("url={}\ntitle={}\ncontent={}\n\n".format(# each[0], each[1], each[2]))print(len(content))sq.insert_into_inital_data(content, "CSDN")
if __name__ == '__main__':word = "3sat"do(word)
总结
- CSDN这个吧,感觉是有点难度,不过花点时间应该不是问题,那个cookie给我的感觉就像之前写过的简书一样,需要先访问一次获取,只是我在这样操作的时候陷入debug黑洞,后来,后来就偷了个懒。
这篇关于有关于CSDN页面爬取破解的两个爬虫(编写时间20200104)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





