本文主要是介绍java数据结构与算法刷题-----LeetCode337. 打家劫舍 III,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 |
|---|
文章目录
- 1. 动态规划+深度优先
- 1.1 解题思路和细节
- 2.2 代码实现
很多人觉得动态规划很难,但它就是固定套路而已。其实动态规划只不过是将多余的步骤,提前放到dp数组中(就是一个数组,只不过大家都叫它dp),达到空间换时间的效果。它仅仅只是一种优化思路,因此它目前的境地和线性代数一样----虚假的难。
- 想想线性代数,在国外留学的学生大多数不觉得线性代数难理解。但是中国的学生学习线性代数时,完全摸不着头脑,一上来就是行列式和矩阵,根本不知道这玩意是干嘛的。
- 线性代数从根本上是在空间上研究向量,抽象上研究线性关系的学科。人家国外的教科书都是第一讲就帮助大家理解研究向量和线性关系。
- 反观国内的教材,直接把行列式搞到第一章。搞的国内的学生在学习线性代数的时候,只会觉得一知半解,觉得麻烦,完全不知道这玩意学来干什么。当苦尽甘来终于理解线性代数时干什么的时候,发现人家国外的教材第一节就把这玩意讲清楚了。你只会大骂我们国内这些教材,什么狗东西(以上是自己学完线性代数后的吐槽,我们同学无一例外都这么觉得)。
而我想告诉你,动态规划和线性代数一样,我学完了才知道,它不过就是研究空间换时间,提前将固定的重复操作规划到dp数组中,而不用暴力求解,从而让效率极大提升。
- 但是网上教动态规划的兄弟们,你直接给一个动态方程是怎么回事?和线性代数,一上来就教行列式和矩阵一样,纯属恶心人。我差不多做了30多道动态规划题目,才理解,动态方程只是一个步骤而已,而这已经浪费我很长时间了,我每道题都一知半解不理解,过程及其痛苦。最后只能重新做。
- 动态规划,一定是优先考虑重复操作与dp数组之间的关系,搞清楚后,再提出动态方程。而你们前面步骤省略了不讲,一上来给个方程,不是纯属扯淡吗?
- 我推荐研究动态规划题目,按5个步骤,从上到下依次来分析
- DP数组及下标含义
- 递推公式
- dp数组初始化
- 数组遍历顺序(双重循环及以上时,才考虑)
- dp数组打印,分析思路是否正确(相当于做完题,检查一下)
1. 动态规划+深度优先
1.1 解题思路和细节
| 题目细节 |
|---|
- 想要偷到最多的钱,一定要遵循,适当取舍
- 比如上一个结点没偷,那么这个结点也不一定非要偷,因为你这个不偷,下一个就可以偷。
- 所以使用深度优先遍历,对于每个结点,都有两个选择,偷与不偷,而相邻的多个结点直接,不用非得隔一个偷一个,而是选择最大的方案。
比如100,1,2,3,4,100. 如果隔一个偷一个的话为
100,1,2,3,4= 106,100或100,1,2,3,4,100= 104,但是如果是100,1,2,3,4,100= 203明显是最大的方案.
特别注意:无论选择偷与不偷,都需要将左右子结点相加,因为只是相邻的结点不能偷,而不是整个子树都不能偷
| 图解 |
|---|
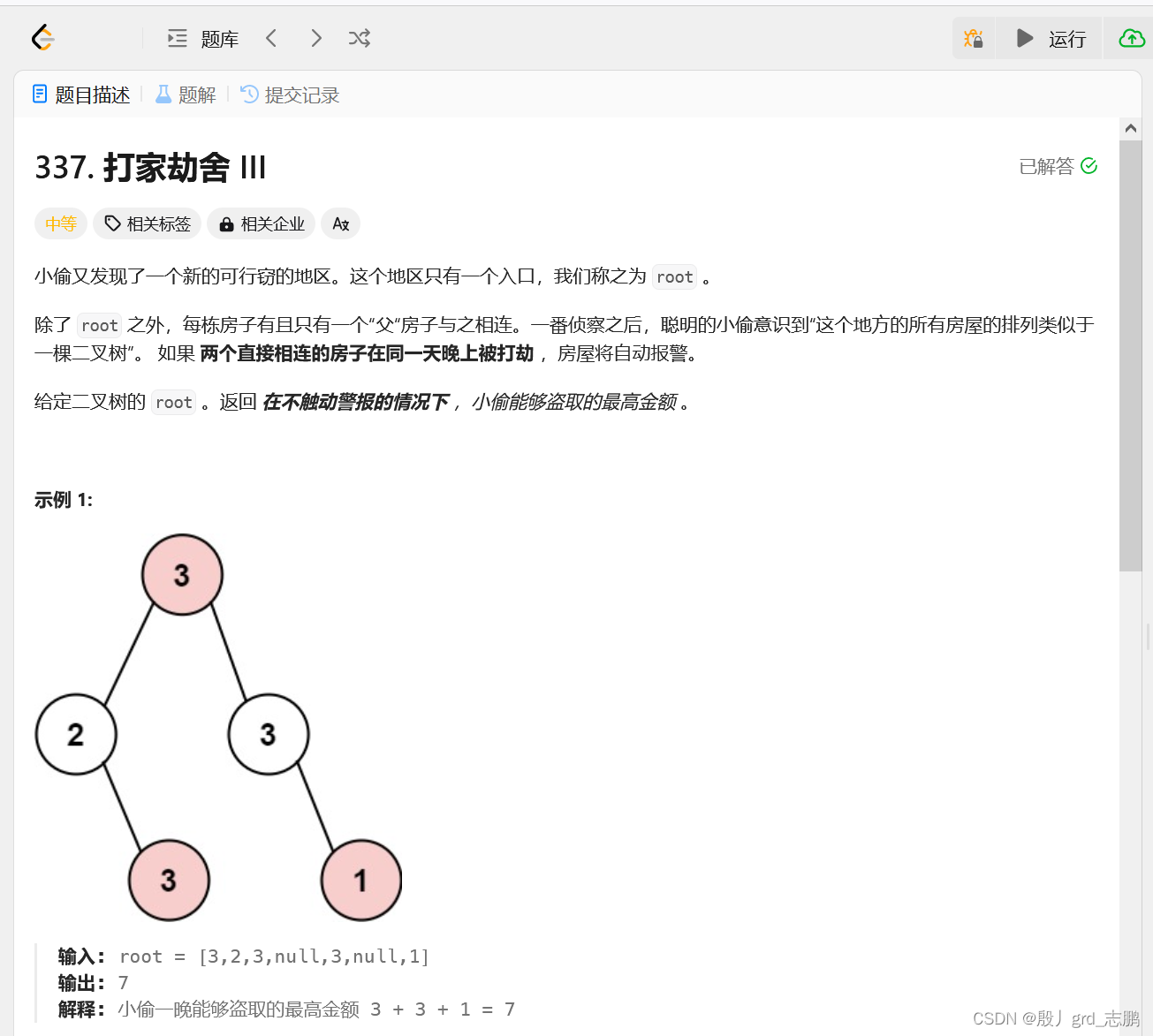
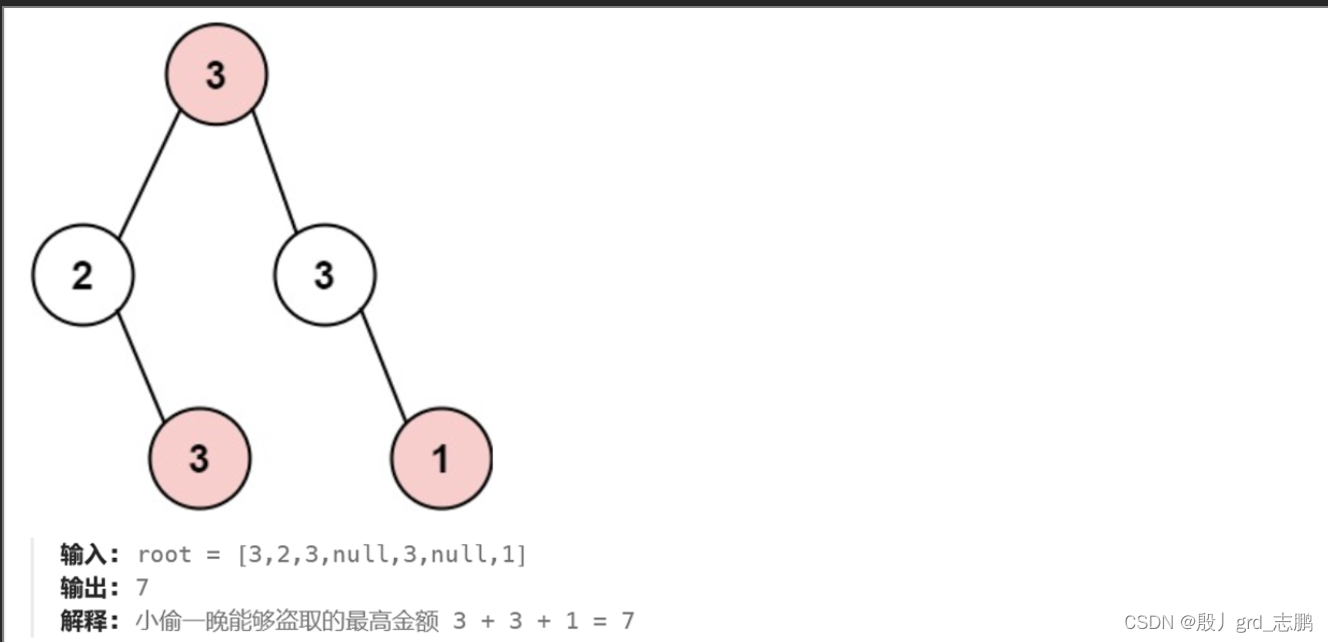
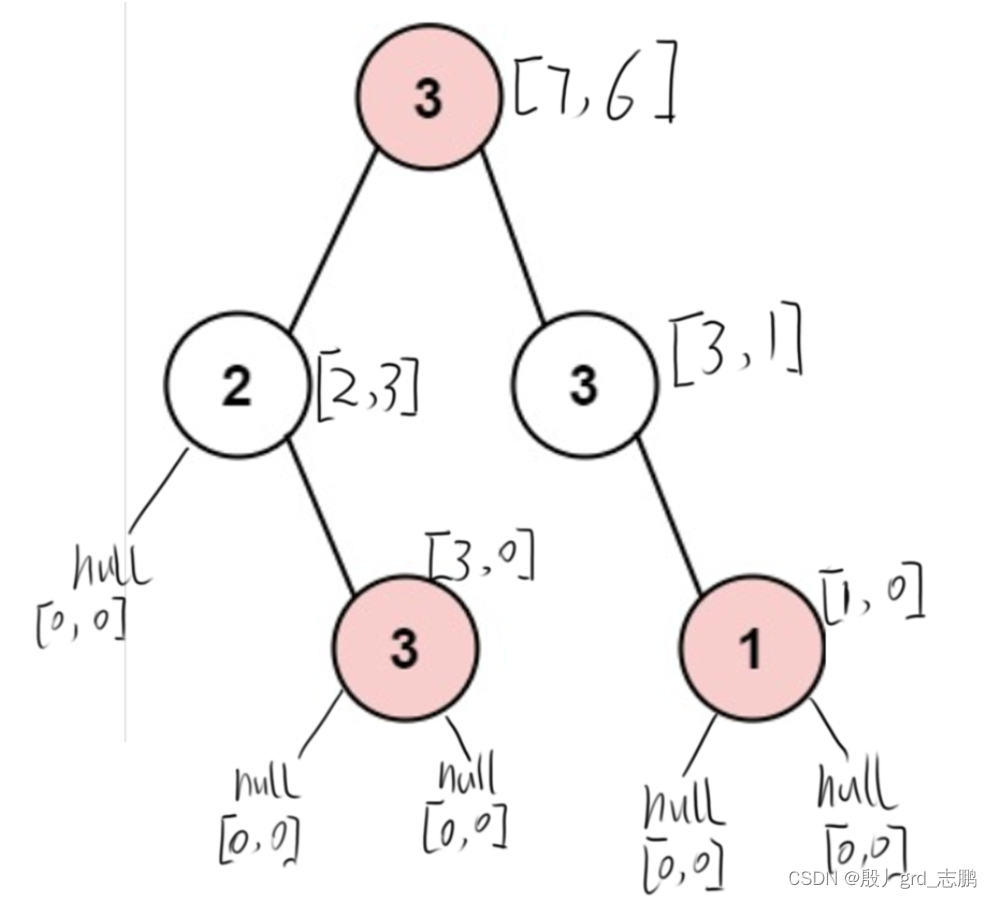
- 以此为例:其中dp数组含义是dp[当前结点偷的话当前共偷多少,不偷共偷多少]
- 对于深度优先遍历的第一个结点为,左下角的3
- 它的左子树是null,所以左子树偷与不偷都是0元,故其左子树的dp数组为dp[0,0],表示左子树偷的话共偷0元,不偷的话共偷0元
- 它的右子树是null,一样偷不偷都是0,故其右子树dp为dp[0,0]
- 它本身是3,所以偷的话就是+3.不偷的话就不加3
- 偷当前结点,那么左子树和右子树都不能偷,左子树不偷的话是0,右子树不偷也是0,合起来为0+0=0,因为都是0,所以就拿到0.加上当前结点3 共偷3元
- 不偷当前结点,那么左子树和右子树可以偷,左子树偷根结点和不偷都有0,右子树偷也是0,两棵子树都选最大的,合起来为0+0=0,当前结点也不偷,共偷0元
- 最终得到当前结点dp数组为dp[3,0],表示偷当前结点,不能偷两个直接儿子共获取3元,不偷当前结点偷左右儿子结点可偷0元
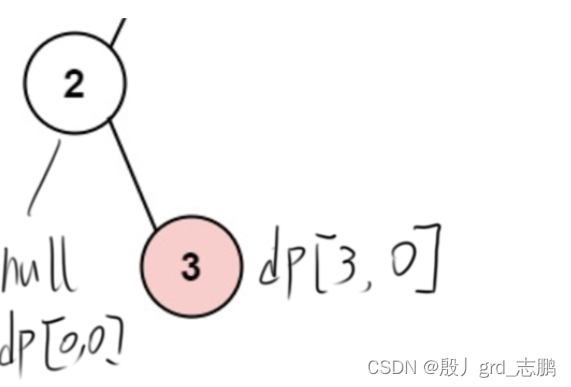
- 第二个遍历结点为它上面的2
- 左子树为null,偷和不偷可获利[0,0]
- 右子树为3,偷和不偷分别获利[3,0]
- 当前结点如果偷,则+2,不偷则不加
- 偷当前结点,则左子树和右子树不能偷,左子树不偷为0,右子树不偷为0,合起来为0,则偷当前结点+2,获利2元
- 不偷当前结点,则左子树和右子树可以偷,左子树偷和不偷都为0,右子树偷为3,不偷为0,左右子树都选大的方案合为0+3 = 3,则不偷当前结点,获利3
- 因此当前结点dp为dp[2,3],表示偷当前结点的话,一共获利2元,不偷当前节点,共获利3元
- 第3个遍历的结点是右下角的1,同理,左右子树都为null,则偷当前结点为1,不偷为0,故dp[1,0]
- 第4个遍历的是右下角1的父结点3,同理,左子树为null,右子树为1,dp[1,0],故当前结点dp[3,1].表示偷当前结点,下面1不偷,为3.不偷当前结点,偷下面那个1为1
- 最后是根结点3
- 如果偷当前结点
- 则左子结点不能偷,左子结点dp为[2,3],也就是不偷它,共有为3
- 右子结点也不能偷,为1
- 则,偷当前结点的3,加上左子结点不偷共有3,右子结点不偷共有1,加起来为7.
- 不偷当前结点
- 左子结点可以偷也可以不偷,偷有2,不偷为3,选大的3
- 右子结点,偷有3,不偷为1,选大的共有3
- 不偷当前结点为0,加上左子结点不偷,共有3,右子结点偷,共有3。加起来为6
- 故,根节点dp为dp[7,6]
- 最终,因为我们要偷最多的钱,所以选择dp[7,6]中大的那个,为7
| 动态规划5步曲 |
|---|
- DP数组及下标含义
- 我们
要求出的是二叉树相邻结点不能都偷的情况下,最多偷多少钱。显然dp数组中存储的是相邻结点如果偷,能偷多少钱,不偷相邻的,而偷当前结点能有多少钱。要求出谁的?显然是求出,以当前结点来看,前面一个结点偷还是不偷。那么下标就是代表前一个结点偷还是不偷,很显然,只需要一个下标,也就是一维数组。而且这个一维数组只有两个元素,代表偷和不偷
- 递推公式
- 假设left[a,b]表示左子树中偷了左儿子,共有left[a]元,不偷左儿子,共有left[b]元,同理right[a,b]为右子树
- 当前结点偷的话,左右儿子不能偷,不偷左儿子为left[b],不偷右儿子为right[b]。
- 当前结点不偷,左右儿子可以偷也可以不偷,偷左儿子为left[a],不偷为left[b],偷右儿子为right[a],不偷为right[b]
- 故dp[n] = [本身 + left[b] + right[b] ,max{ left[a] , left[b] } + max{ right[a] , right[b] }.也就是当前结点,偷的话,就是本身+左子树不偷左儿子+右子树不偷右儿子。不偷当前结点,就是左子树偷左儿子或不偷左儿子选大的+右子树偷或不偷右儿子选大的
- dp数组初始化
- 数组遍历顺序(单重循环,无需考虑遍历顺序,一共就一维,哪里来的谁先谁后)
- 打印dp数组(自己生成dp数组后,将dp数组输出看看,是否和自己预想的一样。)
2.2 代码实现
| 代码 |
|---|
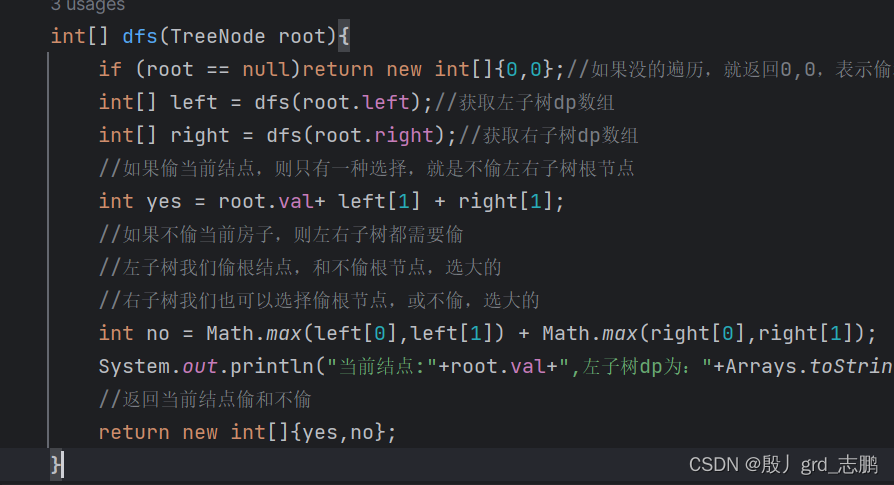
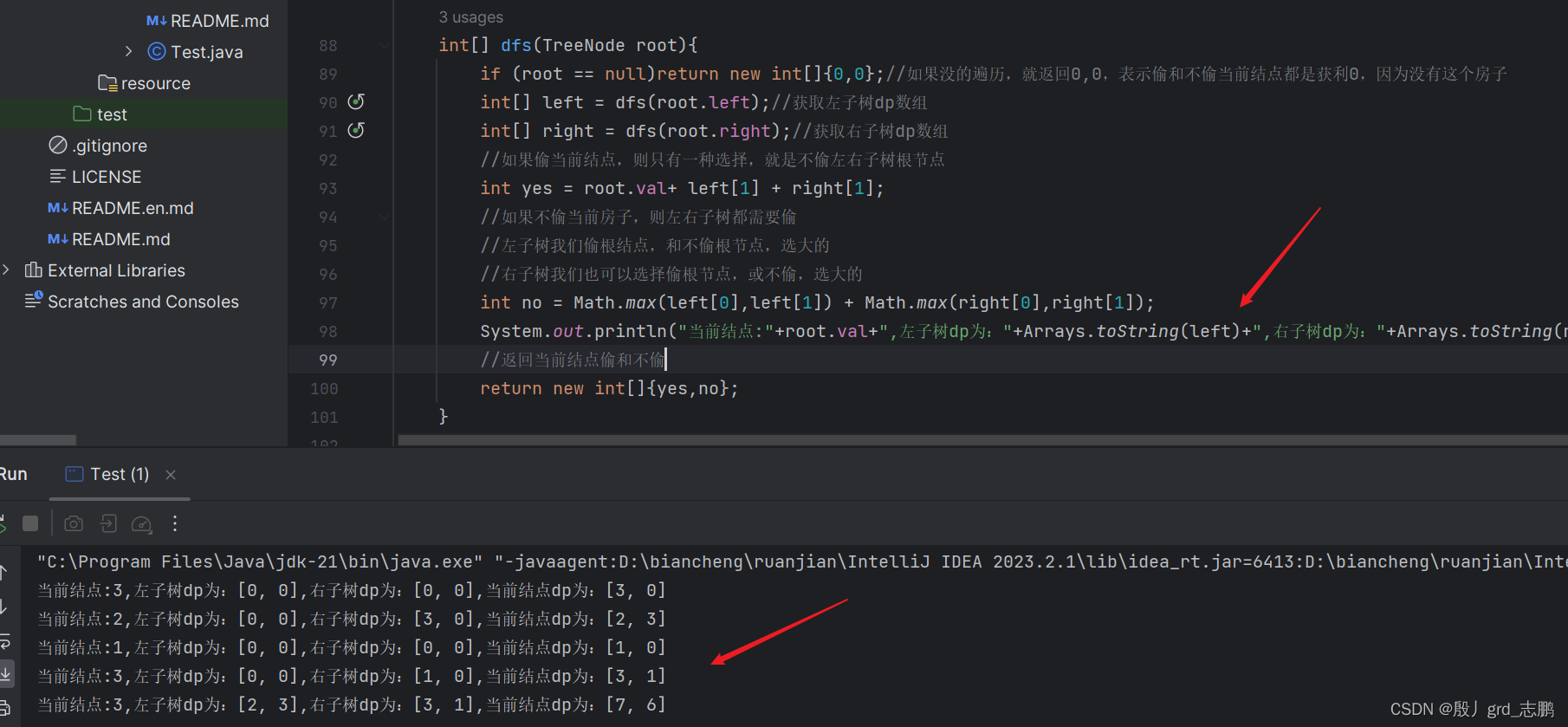
class Solution {public int rob(TreeNode root) {int[] dp = dfs(root);//获取dp数组return Math.max(dp[0],dp[1]);//返回最后一个房子偷与不偷,最大的结果}//int[]{偷当前结点最大获利,不偷当前结点最大获利}int[] dfs(TreeNode root){if (root == null)return new int[]{0,0};//如果没的遍历,就返回0,0,表示偷和不偷当前结点都是获利0,因为没有这个房子int[] left = dfs(root.left);//获取左子树dp数组int[] right = dfs(root.right);//获取右子树dp数组//如果偷当前结点,则只有一种选择,就是不偷左右子树根节点int yes = root.val+ left[1] + right[1];//如果不偷当前房子,则左右子树都需要偷//左子树我们偷根结点,和不偷根节点,选大的//右子树我们也可以选择偷根节点,或不偷,选大的int no = Math.max(left[0],left[1]) + Math.max(right[0],right[1]);//返回当前结点偷和不偷return new int[]{yes,no};}
}
这篇关于java数据结构与算法刷题-----LeetCode337. 打家劫舍 III的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







