本文主要是介绍CLIP 改进工作串讲(下)【论文精读·42】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 图形学CLIPasso: Semantically-Aware Object Sketching
1.1 目的:minimum representation
1.2 相关工作:抽象程度固定、形式风格受限
1.3 如何摆脱对有监督训练数据集的依赖,去哪儿找能把一个图像的语义信息抽取得特别好的模型?CLIP
1.4 本文改进
1.5 主体方法:计算机图形学的文章是怎么用CLIP 模型的
1.5.1 问题定义
1.5.2 两个目标函数
1.6 初始化方法
1.7 后处理
1.8 展示结果:超越基础类、任意程度抽象、
1.9 局限性
总结
2.视频CLIP4Clip: An Empirical Study of CLIP for End to End yideo Clip Retrieval
实验结果
结论
insights
3.动作识别Actionclip
3.1 研究动机
3.2 改进
3.3 主体方法部分
3.3.1 文本 prompt
3.3.2 视觉 prompt
3.4 实验
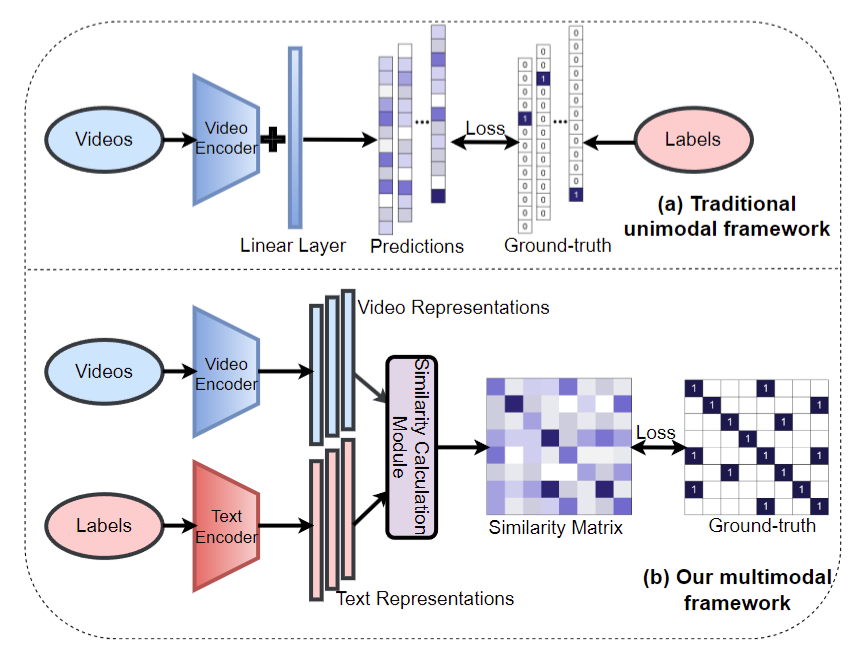
1、Multi model framework 到底有没有用
2、Pre train 的阶段到底重不重要?
3、提出的这个 prompt 有没有用?
4、Zero shot 和 few shot 的能力
总结
4. 其他领域的应用
初始化视觉编码器:How much can clip benefit vision-and-language tasks?
语音:Audioclip: Extending clip to image, text and audio
3D:Pointclip: Point cloud understanding by clip
理解深度信息:Can language understand depth?
总结
1. 图形学CLIPasso: Semantically-Aware Object Sketching
今天我们就接着上次没有讲完的这个 CLIP 的一些后续延展工作,接着来看一下 CLIP 还能用在别的什么领域。虽然上次我就提到了 CLIP puzzle 这篇论文,说他获得了 CGRAPH 的最佳论文奖,但因为时间原因,上次只说了 CLIP 在这个分割和检测里的应用。那今天我们就先来看一下。CLIP puzzle。
1.1 目的:minimum representation
那打开论文,其实第一眼就看到这个图一了。不用看论文,我们也大概知道这篇工作可能就是想把一个这个真实的图片,然后一步一步变成后面这种简笔画的形式。然后我们又看到了毕加索画的这幅画,所以其实立马就意识到这个 CLIP puzzle 就是 clip 和这个毕加索的这个合体。

那题目接起来说, semantically aware object sketching。就是保持语义信息的这种物体的素描。那为什么加上这个semantically aware?是因为作者觉得这种简笔画这种素描其实是非常难的,尤其是对于计算机来说,因为它不光要把这个真实的物体变成一个非常简单的这么一个形象。而且还要确保这个观众能看出来这个简笔画到底描述的是什么物体,它有没有抓住原来这个物体的一些最关键的那些特征。作者这里说他们想达到的目的。就是使用这种 minimum representation,就是最简单最简单的形式,可能就是画几条线,甚至只有一条线。它就能把这个物体表示出来。但是别人一定能够认出来这个物体,就是同时语义上和这个结构上都能识别出来这个物体才行。
那接下来作者为了更加形象的让大家明白他到底在做是一个什么问题,而且这个问题的难点到底在哪?所以他又用毕加索的这幅画做了一个阐述,这幅画的名字其实就是叫。一头公牛。 
这是一个系列了,就是从最开始的第一张图,然后一点,然后一直画到最后一张图,中间的过程可能有快一年。这个一头公牛的这个画作系列其实。非常著名。我在网上查了一下,上次 2015 年最高的这个拍卖价格已经到了 2 亿美金了。所以现在搞研究也真是很卷,不光想法要好,论文写得要好,你这还得懂艺术。
作者这里想展示给大家的其实就是说这个抽象是非常难以做到的,从最开始的这张画细节非常丰富,你如何能够一步一步把那些不必要的元素从这幅画里移掉,到最后的这种极简的形式,但是你还能识别出来它是一头公牛。这个就是这篇论文想做的事儿,他想给一个机器,只要提供了一张真实的这个照片,这个机器就能还给他一张最简形式的这个简笔画。
1.2 相关工作:抽象程度固定、形式风格受限
那这个任务既然这么困难,之前有没有工作去研究过这个方向?基本上任何一个你能想到的研究方向之前,多多少少都是会有一些相关工作的,那在这里也不例外。比如作者这里说的这几个方法就是文献3 25 30,但是作者说这几个方法都是怎么做的?他们其实都是去收集了一些数据集,比如这种 Sketch data set,就这种素描数据集,而且这个抽象程度也都是固定好的,比如说笔画很多不那么抽象,或者说笔画很少特别抽象,这些都是数据集里提前定义好的。有什么数据,那这种 data driven 的方式就会学到什么样的模型,这样最后生成的这种素描画,它的这种形式和这种风格就会非常的受限,这就违背了这个图像生成的初衷了。而且除了这个生成数据的这个风格问题之外,这种用固定的数据集还有一个劣势就是它的种类不能做到很丰富。尤其是已有的那些素描数据集,它的种类非常的有限。
作者这里也带图 4 做了一下简单的总结,在这个领域大概就有这么几个数据集,从一开始这种更偏重于几何的数据集,一直发展到最近的更偏重语义的数据集。
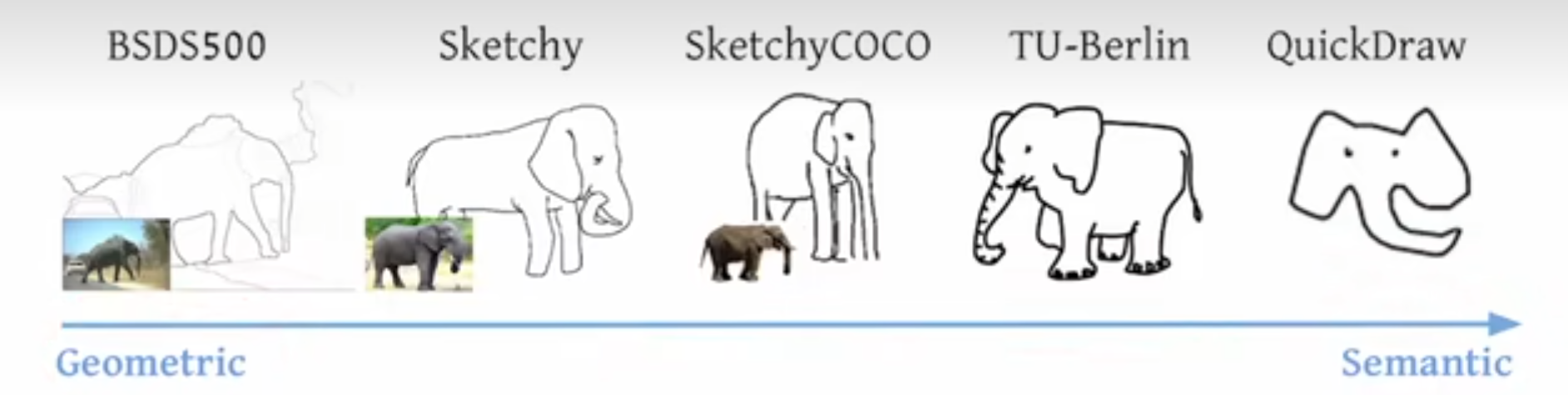
那举几个例子来说,比如最开始的这个 BSD 500 数据集,它其实就是一个分割的数据集,当然了它也不算是语义分割,它更多的是介于一种在这个边缘检测和语义分割中间的一个过程,就是有点像细粒度的这种分割。就像这里画的一样,它虽然把大象好像标记成整个一个物体了。但是旁边的这个树不光是一个物体,它中间还有很多这种树叶。树枝的这种纹理看起来仿佛像做了一个 edge detector,但是又是一个比较具备语义信息的 Ash Detector,属于最原始的分割了,当然这个数据集也是十几年前的数据集了
然后再往后发展就有了 Sketchy 数据集,然后基于这个 Sketchy 数据集又发展出了 Sketchy Coco数据集。但其实这个 Sketchy Coco 数据集里面只有9类,就是一些常见的动物,什么大象,然后还有一些汽车什么这种类别,非常的有限。
然后再往后发展到最新的这个 quick draw 数据集,这个其实是谷歌之前做的一个应用,就是你在它的网站上可以随意的去涂鸦,很短的时间内你画一个物体出来,然后他就把这些数据全都收集起来,做成了一个数据集。然后这整个数据集里有 5000 万个图像,但即使这么大的数据集其实也就 300 多类,所以它的类别数依旧是很受限制的。如果你在它上面训练了一个从真实图像到这种素描的模型,那它也就只能对这几个物体类别起作用,那其他的物体类别可能就还需要收集新的数据,然后再去做 fine tuning。
1.3 如何摆脱对有监督训练数据集的依赖,去哪儿找能把一个图像的语义信息抽取得特别好的模型?CLIP
那如何能够摆脱对这种有监督训练数据集的依赖,然后又去哪儿找能把一个图像的语义信息抽取得特别好的模型?那这两个问题一问出来,那其实对应的答案就只有一个,或者说最直接的答案就是 clip 模型。因为这种文本和语言配对的学习方式,所以它对物体特别的敏感,它对这种物体对语义信息抓取得非常好,而且它又有出色的这种 Zero shot 的能力,它完全不需要在下游的数据集上去做任何的微调,拿过来就能直接用。上一期我们已经在风格和检测里全都见识过了,都工作得非常好,所以在这里也不例外。作者直接就把CLIP运过来。于是就有了CLIP puzzle了。
能把 CLIP 用在这种场景下,让它能work,而且觉得这是一个可做的方向。其实并不像我刚才说的那样,直接问一个问题,你就有一个答案,你就知道 CLIP 就是最后的解决方案,这里面也需要前人的一些 insight 和积累,还有自己的一些改动。
那说到前人的积累,其实作者这里也说了,之所以使用clip,之所以clip,能够不管这个图像的风格,始终都能把这个物体的视觉特征都编码得非常好,也就是说它非常的稳健,它不会受这种图像分割的影响。也就是这篇文献 14 的这个观察才奠定了这篇工作的基础。因为毕竟之前你说 clip 好,那是因为 clip 始终工作的区域都是这种自然图像,不论是检测还是分割,你见的都是这种 RGB 的这种普通的图像。所以说 CLIP 模型迁移得很好,但是现在你是从一个图像迁移到简笔画,它就只有几个线条,剩下大部分区域全都是白色的。你怎么知道 clip 模型还能工作得很好?那其实这时候前人的工作 14 就给出了这个答案。这个文献 14 其实我非常推荐大家去看一下,它是发表在那个可视化的那个期刊 distill 上的作者花了很大的功夫去写,而且真是把 CLIP 的模型分析得特别的透彻,可视化做得特别的炫酷。而且要对模型的稳健性,对抗性攻击,还有 OCR 攻击,各种各样有趣的实验非常值得一读。
1.4 本文改进
那说完了前任工作对这篇工作的影响,那其实还有自己的一些改进,那这篇工作不仅是在训练方式上,还有在 lost 选择上,还有在这个简笔画的初始设置位置上,都有独到的贡献,所以才能达到这么惊艳的。最后的这种生成的效果,也就是作者在图 3 里展示的这些结果类。

Parcel 不光是能把一个图像变成任意一个简笔画,而且它能通过控制这种笔画的多少来实现这种不同层次的这个抽象?如果你给定的这个笔画多,它就不那么抽象,你还能看出来它是很好的一个花,然后长颈鹿什么的。但如果你把这个笔画不停地缩小缩减,到最后可能是有三四画的时候,它还是能够兼顾这个几何和语义性,给你画出一个 Semantic aware 的这个简笔画。
1.5 主体方法:计算机图形学的文章是怎么用CLIP 模型的
那介绍了这么多,接下来我们就来看一下文章的主体方法部分。看看一篇计算机图形学的文章是怎么用CLIP 模型的。
1.5.1 问题定义
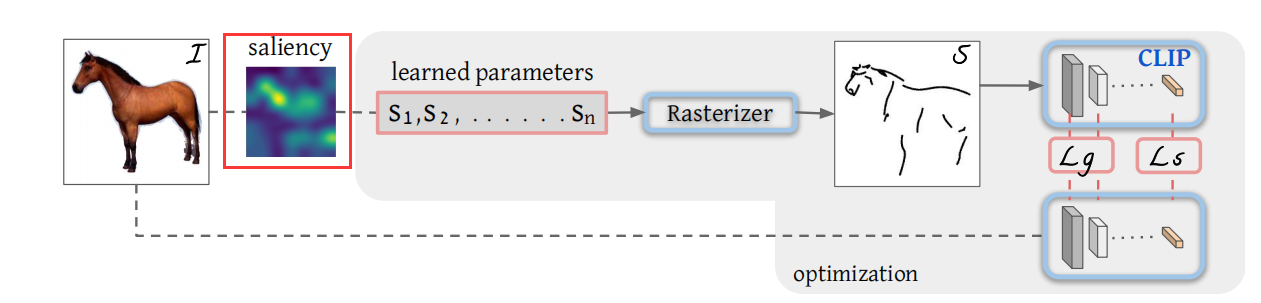
那首先作者先定义了一下问题,他说他现在的任务其实就是在一张白纸上,然后画几个这个曲线,也就他这里说的这种贝塞尔或者贝兹曲线。然后这些曲线当然都是随机初始化的,然后通过这种不停地训练,他希望这些曲线最后就变成了这个简笔画。
那现在我们就来具体地看一下每一步是怎么完成的。首先我们说到了这个倍资曲线这个概念,倍资曲线其实是通过一系列的这个空间上二维的点控制的一个曲线。比如说你现在有这样的几个点,那它可能就定义了这么一个曲线。如果用数学表达式来说,每一个曲线这个 SI 它用 s 的原因是 Stroke 的缩写,就是笔画。 在这篇文章里,一个笔画它用了四个点去控制,所以是 1- 4四个点。然后每一个点在空间上是一个二维的,所以是有一个 x 值,有一个 y 值,所以也就是说你这四个点控制了这个曲线,然后你通过这个模型的训练,你去更改这四个点的位置,然后通过倍资曲线的计算,你就能慢慢改变这条曲线的形状,最后变成你想要的简笔画的形式。那至于更深入地对倍资曲线的讨论,或者说怎么用这些点去控制生成这个倍资曲线,这些都是图形学那边的事情了,我这里就不过多介绍。
在这篇文章里,一个笔画它用了四个点去控制,所以是 1- 4四个点。然后每一个点在空间上是一个二维的,所以是有一个 x 值,有一个 y 值,所以也就是说你这四个点控制了这个曲线,然后你通过这个模型的训练,你去更改这四个点的位置,然后通过倍资曲线的计算,你就能慢慢改变这条曲线的形状,最后变成你想要的简笔画的形式。那至于更深入地对倍资曲线的讨论,或者说怎么用这些点去控制生成这个倍资曲线,这些都是图形学那边的事情了,我这里就不过多介绍。
然后假设说我们现在在一个空白的纸上已经定义了这几个曲线,也就这里说的 S1 到 SN 就是 n 个笔画,然后作者就把这 n 个笔画扔给了一个光栅化器 restrizer,他就能把这些笔画到这个二维的这个画布上,变成一个我们能看懂的图像。然后这里的这个光栅化器其实是一个可导的,而且就是用的图形学那边已有的一个工作没有做任何的改动。所以也就是说整个这一部分是没有任何 contribution 的。
这篇文章主要的 contribution 就在前面和后面,就是前面如何去做一个更好的初始化,后面如何选择一个更合适的 loss function
1.5.2 两个目标函数
那我们现在先按照文章的一个顺序说一下这个目标函数,那我们现在得到的模型的输出,也就是这里这个不太像马的这个简笔画之后,我们肯定是要算一些这个目标函数,然后再回去更新一些参数的。
那我们这里的 ground truth 是什么呢?或者说我们能选一个什么样的这个目标函数?这里其实就是 clip 模型发挥作用的地方,就跟之前我们讲目标检测里的 ViLD一样,它其实就是把 clip 模型当做了一个teacher,然后用它还去蒸馏自己的模型,去把 CLIP 模型里已有的那些概念都学过来。这里面大概就是这个意思,它就借助了我们之前讲过的 CLIP 模型的这个稳健性,就是不论对这种原始的好的这个图像,还是对后面的这个简笔画图像。如果他们描述的都是同一个物体,比如说是马。那它通过这个 CLIP 模型最后得到的这个特征,那它应该都是对马这个物体的描述,他们应该相差不远,八九不离十。所以这个时候我就应该让这两个特征尽可能的接近,于是乎第一个这个目标函数就出来了,也就他这里说的这个LS,也就是 Semantic loss,就是这种基于语义性的一个目标函数,它就是希望这种简笔画生成的特征和原始图像生成的特征尽可能的接近,那这个确实很好想了。但是这里还有一个问题,就是如果你只是保证它的这个语义接近,那还是会出很多问题。比如说你这里生成的简笔画,比如说码头,如果在这边怎么办?它最后编码出来其实还是码,但是这就不是你想要的那种简笔画,因为和你的原始输入图像不匹配了。
也就是说我们除了这个语义上的这个限制之外,我们还应该在这个几何形状上也对这个模型的输出做一些限制,这也就是作者这里提出的第二个目标函数,就这个基于 geometric 的目标函数,具体来说就是作者借鉴了之前一些 low level 视觉里的一些任务者,说那些衡量指标像 perceptual loss 一样,它是把模型前面几层的输出拿出来去算这个目标函数。我们拿最简单的 Resnet 50 做例子的话, Resnet 50 有四个阶段, RES 2345,它现在的意思其实就是把 REST 234 这些层的这个特征拿出来去算loss,而不是用最后的那个 2048 维的特征去算,这样子因为前面的这些特征它还有长宽的这个概念,所以说它对几何的这种位置更加的敏感。那用这种特征去算 loss 就能最大程度上保证这种几何形状,然后这种物体的朝向这种的一致性,那这篇文章里,其实这个 LG 就是在 clip 预训练的模型,比如说什么 rise 50、 rise 101 的前几层去算这两个图像不同层之间这个特征的相似性。那尽可能地让它们也保持一致。
这样在这两个目标函数的齐心协力的作用下,就能保证最后生成的这个简笔画,无论是在几何形状上、位置上跟原有的图像尽可能的一致,而且在语义信息上也能尽可能的保持一致。
1.6 初始化方法
所以到这里作者已经能够非常愉快地生成各种各样的图片了。但是经过很多张图片的生成之后,作者发现这个被资曲线的这个初始化就是最开始的一个点,放在那其实是很有讲究的,不同的初始化会带来很不一样的生成效果,有的生成的简笔画就又简单又好看,有的生成的简笔画那个语义信息就还是恢复不了,甚至就是一团糟。那这个时候作者就想得有一个比较稳定的这个初始化方式,才能让这个方法变得更普适,而且更加容易让大家去复现。所以这里作者又提出了一个基于 silency 的一个初始化的方式,具体来说它就是用一个已经训练好的一个 vision Transformer,然后把这个图片扔给那个 vision Transformer,然后把最后一层的那个多头自注意力取个加权平均,然后就做成了这么一个 sailency map,然后就在这个 sailency map 上去看哪些区域更显着,然后就在这些显着的区域上去采点,这样作者就发现最后的一个生成就稳定了很多,而且效果普遍也都好了许多。当然这个其实是很容易理解了,毕竟你在这些显著性的区域去踩点,其实说白了你已经知道这里有一个物体,或者其实你已经是沿着这个物体的边界再去画这条被滋曲线了。所以你的初始化曲线很有可能就跟你最后的那个简笔画已经相差不了多少了。这个其实在作者后面这个补充材料里也有验证,作者说他们这个模型的训练一般需要花 2000 个iteration,但往往在 100 个 iteration 的时候,你就已经能看出来这个模型工作的怎么样,就大致的那个简笔画轮廓就已经出来了,所以收敛是非常快的。
那我们来看一下它这个收敛过程。在文章的图 7 里,作者给了一个例子,如果这个输入是一个人脸,那总共这个训练一般是花 2000 个iteration。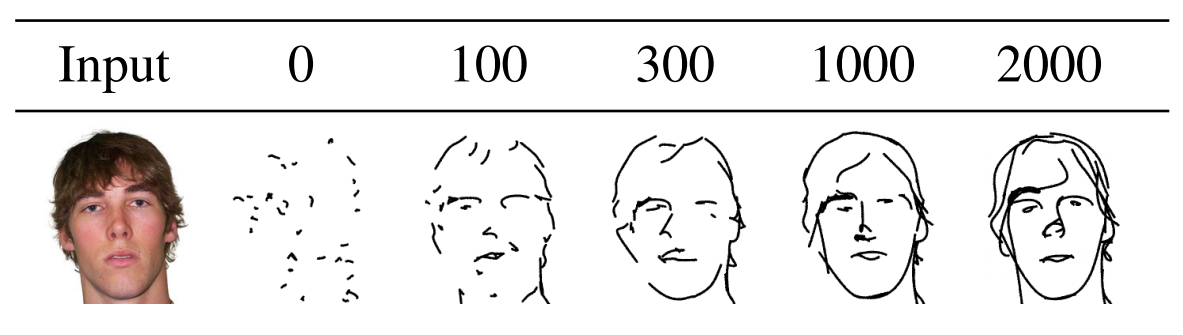
我们可以看到,从 100 个 iteration 开始,就已经基本能看出来是个人脸的形状了,而且眼睛、鼻子、嘴其实都在那了。然后在 300 iteration 或者 1000 个 iteration 的时候,其实这个人脸的简笔画就已经不错了,然后最后一直收敛到 2000 个iteration,变成一个更像简笔画的一个输出。
然后这篇论文其实还有一个很好的点,就是它的模型训练很快,作者在后面补充材料里说,他们只用一张 V100 的 GPU 就能在 6 分钟的时间里完成这 2000 个iteration,所以说它的这个迭代是非常快的,所以在我们没有那么多计算资源的时候,往往可以考虑一下这种跨界的研究,有的时候就能迸发出很好的这个想法,而且也不需要那么大的这个计算资源。如果你只是在 CV 或者多模态这边跟别人去卷的话,那没有几十张卡是很难做出来有影响力的工作。
然后我们再来看一下这种 cilency guided 的初始化方式到底能带来多大的提升。

作者这里给的例子还是一个人脸的一个输入,他说如果你是用初始化的方式去放那些背资曲线的话,最后你生成这个简笔画,就是像右边这样。当然也是不错的一个简笔画了,但是如果跟这篇文章最后提出的方法比就稍显逊色一些,比如文章提出的方法最后达到的简笔画就能有这个效果,既能做到头发上的这种简约,又能把眼睛这种重要的特征凸显出来。作者这里还把自制力的这个图和最后的这个踩点的分布图也都画了出来。我们其实可以看到了,这个踩点的分布图就已经跟最后的这个简笔画的形状了非常的接近了。所以说你在这些更显著的区域上去踩点,所以你最后得到的就会是一张更 semantic aware 的这种简笔画的形式。
1.7 后处理
然后有了这部初始化之后,作者得到的这些简笔画质量看起来就都不错了,但为了精益求精,作者还加了一步后处理的操作,

就是这里图 8B 画的自动的选择最后的那张 final Sketch:它每次都是根据一张输入,然后会生成三张简笔画,然后再根据之前提出的那个 LG LS 那两个目标函数,就算一算这几个简笔画哪个能给出最低的那个loss,他就把那个简笔画当成最后的这个输出。这个后处理其实也很常见,在文本图像生成那边也被广泛使用,比如说像DALLE,你给一个文本,它可以生成很多很多图片,那最后把哪张图片展现给观众,其实它是又用 CLIP 模型去算了一下,生成的这些图片和原有的那个文本哪个相似性最高,它就把相似性最高的那个图片返回给你了,这样往往能达到更好的效果。
1.8 展示结果:超越基础类、任意程度抽象、
那到这儿其实就算把文章的主体方法部分讲完了,接下来作者就展示一些结果,做一些消融实验。
那首先作者就把这篇文章最大的亮点,它最好的这个结果放在了前面。第一个就是在图9里。

他说我们的方法CLIPPasso 可以给那些不常见的物体也去生成简笔画,这个对于之前的方法来说是很难做到的,因为之前的方法都需要有对应的那个训练数据集,那个数据集里有什么物体,它最后就只能生成什么物体的这种简笔画,换个新物体模型就不能工作了。但是对于 CLIP puzzle 来说,因为借助了 CLIP 模型强大的 Zero shot 的能力,所以说他想画什么物体的简笔画就画什么物体的简笔画,我们从这里的几个例子也可以看出来,比如说跳芭蕾舞的演员,或者说红酒杯,或者说王冠,这些都是不常见的物体。
那第二个让作者引以为豪的功能,就是说 CLICK puzzle 能达到任意程度的抽象,它只需要控制你这个输入的笔画数就可以了。

比如说你最开始用了 4 个这个倍词曲线。它就给你更多的内容,就不那么抽象。但如果你把这个倍词曲线的数量减少到 2 画或者一画的时候,那可能就给你更为抽象的一个简笔画,这种随意性,还有这种对抽象程度的掌控也是之前的方法望尘莫及的。所以这就是这篇文章最大的两个卖点,那作者就把它放在最前面的两个结果图里
那在接下来就是和一些别的方法的对比了,比如说在这个图 11 里,作者就跟之前的这些方法去做对比。我们就可以看出来,不论是在这种笔画多的时候,还是在后面这种笔画特别少的时候, Clip Parcel 都能达到一个更好的抽象的结果,它的抽象化都更具备语义信息,更能抓住那个物体的本质。当然最后的这个对比我没太看出来为什么他们的方法更好,
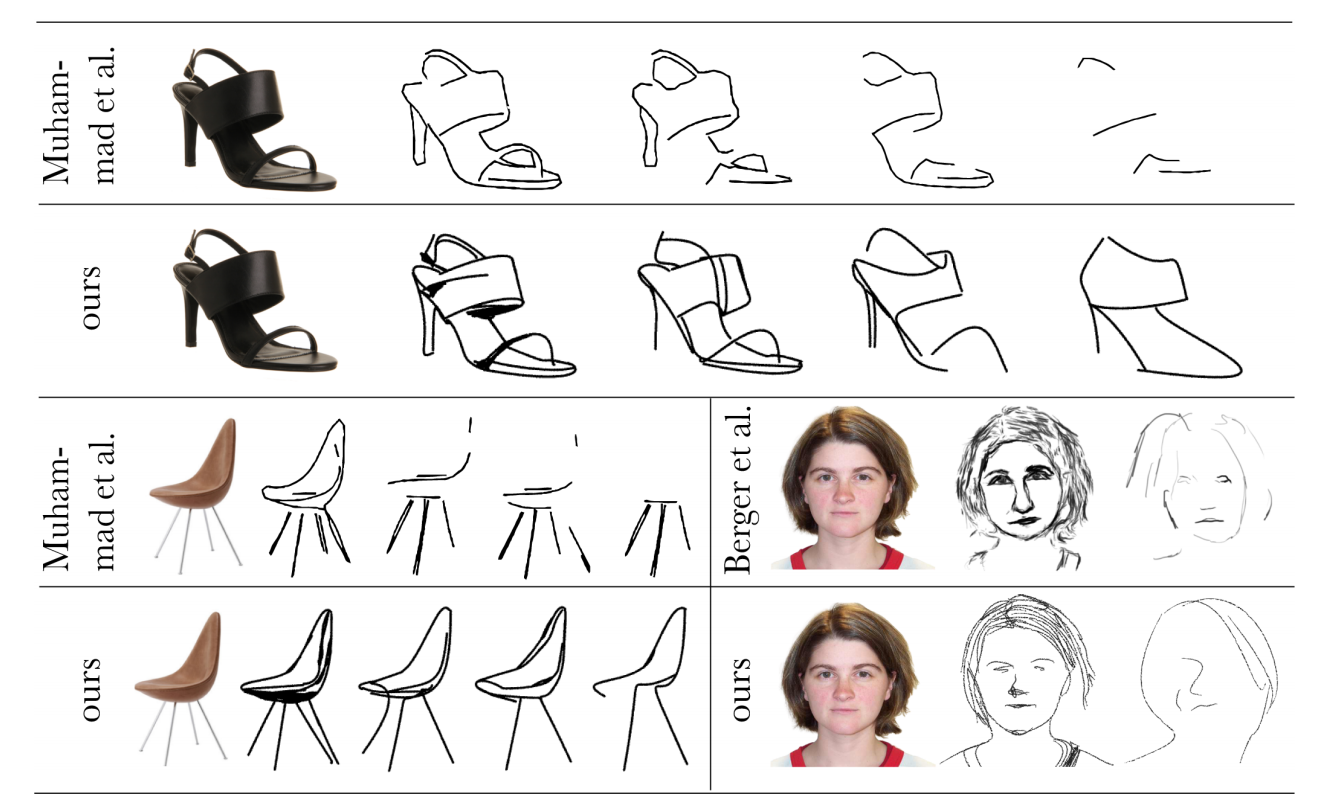
可能是这里的头发跟原图更加匹配,或者说这里这个画的更抽象,但是原来的方法反而是把眼睛画出来了。所以对于我这种不懂艺术的人来说,我也不知道这里到底谁好谁坏,但前面的几个例子明显 clizzle 还是要好不少的。
1.9 局限性
那最后我们一起来看一下文章的第五部分,就这个局限性,这个部分往往是最有意思的,因为它展示了这个工作目前还有哪些缺陷,有可能还能怎么继续去提高。读者和审稿人都很喜欢看这里。
那作者这里说的第一个局限性就是说 clip puzzle 这个方法,当这个图像有背景的时候。那么模型的这个效果就会大打折扣,它必须是一个物体,然后处在一个纯白色的这个背景上,他们这个方法变成简笔画以后,这个效果才非常的好。这个也是很理所当然,对吧?如果你只有一个物体,然后你背景都是白色的,那这样呢?你的那个自助力图就会很准确。你的初始化就会好,那你最后应该就很容易生成一张语义比较接近的这个简笔画。但如果带了背景之后,你的这个自注意力图,你的初始化,还有你的这种 edge detection,这个复杂度就上升了很多,自然效果就会大打折扣。那作者说在本文里,他们是选择了一个工作的比较好的一个 Automatic mask 的方式,叫做 u2net。这个方法其实就是先把一张图片就是带背景的那种图片,然后他把这个物体抠出来,就能变成一个前景是物体背景是一个白色幕布的片,然后他再把这个图片扔给 Clay puzzle 去生成简笔画就行了。不过作者这里觉得这样这个整个过程就变成了一个 two step的过程。你得先把前景抠出来,然后你再用 CLICK parcel,这个可能就不是最优的结构。那在这个深度学习时代,最优的结构永远都是 end to end。所以如果你能把这种 automatic masking 的方式融合到整个这个框架之中,甚至你能提出一个新的这种 loss function 或者模型的改进去,把这种带背景的图片也能解决得很好,那这个模型的适用范围就更广了。那就意味着不论你给什么图片,它都能生成质量很高的简笔画。
那第二个作者这里说的局限性了,就是在 Clip Parcel 里,它那些初始化的笔画都是同时生成的。而不是就是这种序列生成的。但我们知道,人在画简笔画的时候,其实都是一笔一画这样画的,甚至是那种一笔画就直接一笔画到尾了。它都是带有这种序列性质的。那之后是不是也可以把 CLICK puzzle 做成这种 auto regressive 的形式?就我先画一个笔画,然后再根据前一个笔去定位下一个笔画应该在哪,然后再看它再怎么优化,然后一步一步去生成最后的这简笔画,是不是就更像人在作画呢?而且是不是就能生成更加 diverse 的这个图片了?这个也是非常有趣的一个未来研究方向。
第三个局限性就是作者这里虽然最引以为豪的就是它能够通过控制这种笔画术去控制这个图片的这个抽象程度,但是毕竟这是一个手动的过程,就是我必须提前去指定你现在用多少个 笔画数,我让你用 8 话,你就只能用 8 话,我让你用 16 话,你就只能用 16 话。但事实上其实不同的图片它需要的这个抽象程度是不一样的。比如说像之前展示的那个马,或者说是长颈鹿,那其实真的就是一两笔就能把它最关键的部分展示出来,我们也能识别出来它是什么物体。但是对于某些非常复杂的概念来说,它可能就需要更多的这个笔画数。就像作者这里说的,即使你想达到同等程度的这个抽象化,要不同的图片其实需要不同的这种笔画树。所以最好的方式就是把这个笔画树也做成一个可以优化的参数,把它变成一个 learnable 的parameter,这样子用户之后的输入真的就是一张图片就够了,它也不用输入。我现在想用 5 画还是 10 画去画这个简笔画,都不需要模型自己去考虑,真的就像一个艺术家一样,它来决定到底用两三画还是十几画去把这个简笔画呈现出来,这个也是一个非常合理而且非常有趣的未来研究方向。
总结
总之, CLIP puzzle 是把 CLIP 模型用到图形学,而用到这种图片生成简笔画的这个方式里的一个非常好的工作。它很大程度上也借鉴了之前的一篇论文 clip draw,也就之前我们讲过 Clip 刚出来,然后才过了两三周, Clip draw 这篇论文就也出来了,所以我们这里就不精读 clip draw 了。至于大力兔,我们之前也讲过,所以图像生成这边我们就只读一下 Cliparcel 这篇论文就可以了。
2.视频CLIP4Clip: An Empirical Study of CLIP for End to End yideo Clip Retrieval
那接下来我们看一下 clip 是怎么用到视频领域里的。那我们第一篇要看的就是这个 clip for clip 论文,它是直接用这种 clip 模型去做视频里的这种 video text retrieval 的。clip4clip这篇论文放到 arxiv 上的时间也非常的快, 21 年4月 18 号就放上去了,也就是 clip 刚出来一个半月,然后这篇文章就已经怒刷了 video retrieval 里 5 个 数据集了。
论文的名字起的也很好,一语双关。CLIP4Clip:前面的 clip 指的是 OpenAI clip 模型,后面的 clip 指的是视频里的那种一段一段的小 video clip。总体来说这篇文章就是一个 empirical study,想法是非常简单的,但是有很多很有意思的insight,确实也推动了视频领域这个 video text retrieval 这个任务。
其实 clip 模型天生就很适合做这种 retrieve 的任务,因为它就是在算这个图像和文本之间的相似性,然后根据这个相似性你可以去做 ranking、matching、tetrieve 各种各样类似的任务。而且因为它是一个双塔结构,就是图像和文本的这个编码器是分开的,得到两个特征之后,只需要做一步点乘就可以得到这个相似度,所以这也就意味着它的扩展性非常的好,它甚至可以提前把一个特别大规模的数据集,它里面这些图像和文本的特征都提前先抽好,然后把特征存在本地,然后每当你有新的特征进来之后,你可以直接让特征和特征去做点乘,就可以知道相似度。然后直接做排位或者匹配就可以了。所以特别适合拿来做搜索和retrieve。
那 clip 出来之后,很自然大家就想着把它怎么能拓展到视频领域去做视频里这种文本和视频段落的这个匹配,那其实区别还就是那么一个,就是视频多了一个这个时间的维度。
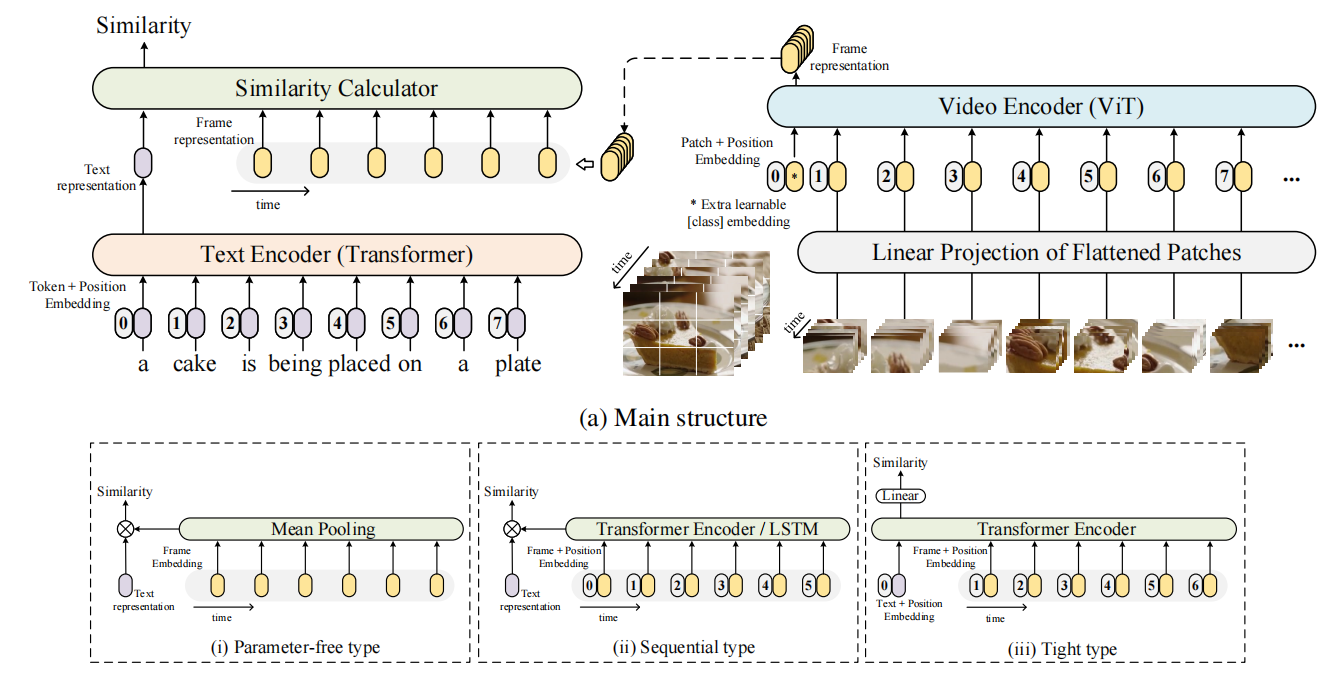
比如说在本文的这个图一里,你文本这边儿还是一个句子,然后你把它tokenize之后扔给一个text encoder(transformer),然后你最后就得到一个 CLS token,就是整体的这个句子的这个表达,这跟 CLIP 没有任何区别。
但是在视频这边,因为视频你是一系列的这个视频帧组成的,它有这个时序的概念。然后如果用最简单的形式,就是说我每一帧都单独的把它打成这种image patch。然后再把这个 patch 扔给这个VIT,然后去得到最后的这个 CLS token 的话,你得到的不再是一个 CLS token 了,你得到的是一系列的CLS token。比如说这里你如果有 10 帧,那你最后就会得到 10 个 CS token,也就是 10 个图片的这种 global 的整体表征。那现在问题就来了,原来你是一个文本特征对应一个图片特征,那你直接做点乘或者做什么这种相似度计算就可以了。但是现在你是一个文本特征对 10 个图像特征,那这个时候你怎么去做这种相似性计算?
那这篇文章因为是一个 empirical study,所以它其实就是把已有的各种方式全都尝试了一遍,然后看一下哪个方式的结果最好,它就尝试了 3 种,那接下来我们一个一个看。
- 第一种就是最简单的方式,而且是不带任何参数,就是你都不需要去学。如果你有 10 个这个图像的特征的话,我直接给你取个平均就完事了,那这样子 10 个特征直接就变成一个特征,那就跟 CLIP 一样了,还是一个文本特征一个图像特征,你直接点成或者用什么去算相似度就可以了。但是这个方式就有一个缺点,因为他在做这个平取平均的时候,他并没有考虑到这个时序的特性,那如果你现在有两个视频,一个是一个人逐渐地在坐下,另外一个视频是在描述一个人逐渐地在站起来,那现在如果你不考虑时间上这个顺序,你只是取一个这个平均的话,那你最后得到这个特征其实并不能展示出到底这个人是在坐下还是站起来。那这两个动作你就区分不了。那如果对应的文本就是在问你到底是在站起来还是坐下,你就没办法回答这个问题了。所以虽然简单,但是有它的局限性。但即使如此,这种方式其实是目前最被广泛接受的一个方式。因为它最简单,在一个很短的视频片段里去取平均,效果也不差。
- 那第二个方式也很直接,那你现在无非是两个目的,一个目的是把 10 个特征变成一个,另外一个是把时序性融合进去。那你想到时序建模,那最原始的肯定就是LSTM 了。那就说你把这 10 个特征扔给一个LSTM。然后你把最后的输出拿出来,它其实就是一个特征,而且也融合了之前的这个时序信息。那现在大家纷纷都用 Transformer 去取代了原来的LSTM。那对于 Transformer 来说,你只需要把这些 positional embedding 加上,就是 012345 加上它其实也能对这种时序进行建模,那这就是第二种方式,作者这里叫它sequential type。就是把时序信息考虑进去了。
- 那最后一种方式作者叫做tight type。但其实说白了就是在做 early Fusion,因为上一步我们在做那个 sequential type 的时候,其实做的是 late Fusion,就是你已经把图像和文本的特征抽完了,你只是在考虑最后怎么融合。那在第三种这个 tight type 里,其实从最开始它们就进行融合了。具体来说就是文本带上文本的这个编码也扔给了一个Transformer,这个视频帧得到那些特征也全都扔给了现在这个 Transformer encoder,他就把文本和这个图像帧的特征一起在学习,它有点是把这个文本特征当成是 CLS token 的那个意思了,然后通过这个 transformer 里不停地交互,最后就把这个文本的特征通过一个MLP,然它去算这么一个相似度。这样子它不仅实现了这种时序信息的融合,它还实现了这种文本和视频帧之间的融合,最后所有的特征都直接变成一个特征,然后去算相似度。
那其实说完了这 3 种如何计算这个相似度的方式,这篇文章的主要方法也就说完了。
实验结果
接下来我们就直接看实验,像刚才说的这篇论文,虽然出来的时间非常快,但是已经怒刷了 5 个数据集,也就这里说的MSRVTT、 MSVC LSMDC activity net 和 d demo 都是 video text retrieval 这个任务下面常刷的一些数据集。
我们先来看表一,就是 MSRVTT 上的结果
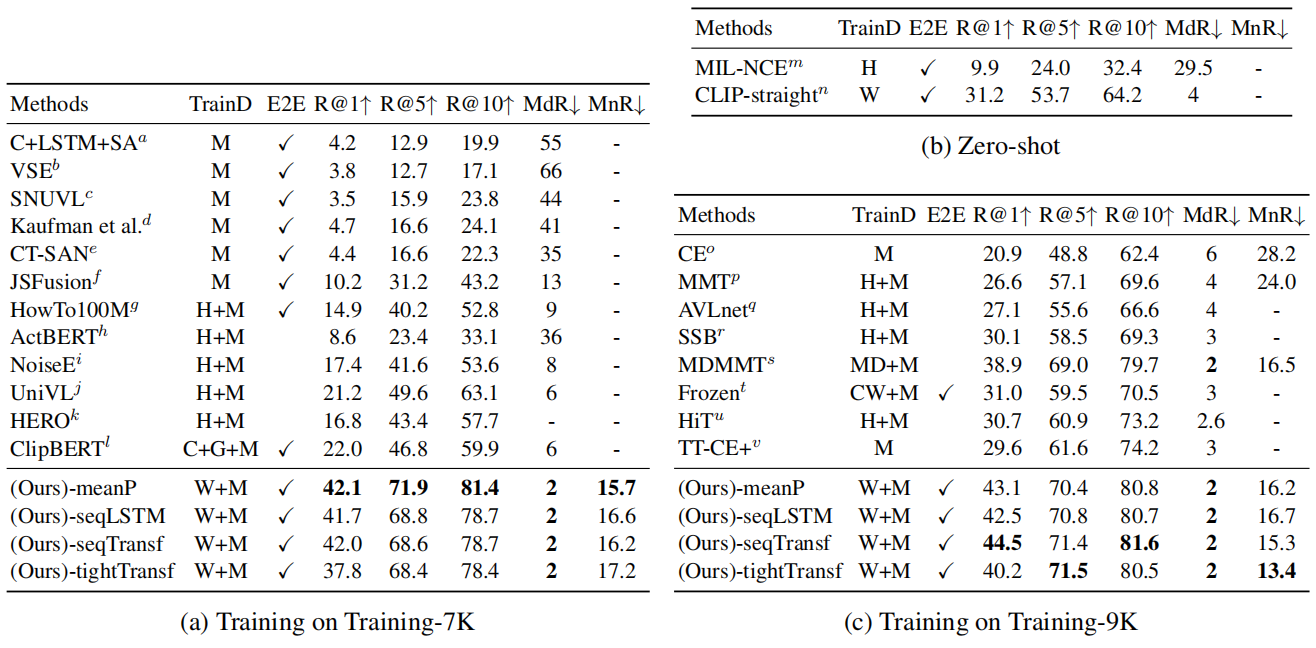
作者说用上了他们的方法之后,比之前所有的这些方法都高了不少,那确实从这个 recall 上来看, recall 是越高越好,所以说之前的方法都才是十几二十几,但是他们的方法直接都三十四十了,所以说确实是提升了一大截。
但是如果我们看一下接下来这两个表格,就是 b 和c,我们其实也就能理解为什么左边这个表格里提升这么明显。
那首先我们先来看b, b 里就是做 Zero shot 的结果,这里其实就是对比一下之前这种用 Mill NCE 的方法和用 CLIP 的这种方法,他们做 Zero shot 的这个差距到底有多大。这里面这个 HAW 就代表预训练的数据集,
h 就代表的是 how to 100 million,
那这里的 w 就代表 clip 训练的那个 WIT 数据集是 400 million。
虽然这两个数据集规模上相差不是很多, 100 million和 400 million就差 4 倍,但是明显 CLIP 预训练的这个数据集质量更高,所以它在 Zero shot 上这个差距也已经体现出来了。使用 CLIP 模型以后,直接 Zero shot 就有 30 多的这个结果就已经比左边这个表格里所有的之前的方法都高了不少了。所以其实他们下面的这些方法得分这么高,更多的助力是来自于使用了 CLIP 的这个预训练模型。也就是他这里说的这个 w 的数据集。至于这里的 m 就说他又加上 MSRVTT 的数据集,又去再训练了一下。所以这个算是第一个observation。就是 clip 模型确实迁移性很好,你直接拿它过来做视频文本的这种 retrieval 也完全不在话下,效果直接秒杀之前的那些方法。
那第二个 observation 就是对比一下这个表 a 和表c。
它们的区别其实就在于这个 m 的使用的数据量的情况,因为虽然是同一个数据集,但是它训练和测试集的这个划分是不一样,这个表 a 是在这个 7000 个视频上去训练的,
而表 c 是在 9000 个训练数据集上去训练的。也就是说表 c 在微调的时候使用了更多的训练数据。
那如果这个时候我们来对比一下文章中提出的这 4 种算相似度的方式,我们就会发现在使用少量数据集的时候,直接取平均的效果是最好的,就是说那种无参数学习的方式反而是最好的,只有当你把这个训练数据量提高的时候,有可能后面的这种学习的方式才会取得更好的一些结果。这个其实也比较合理,虽然说你现在处理的是一个视频问题,但视频也无非是由这个视频帧,也就是一张一张的图像组成的。那 clip 模型既然在 400 million 的这个图像文本对上去训练过,所以它的这个模型的参数已经非常非常好了。那如果你的这个下游数据集数据量并不大的话。其实并不建议你去微调这个模型,直接用往往是效果最好的。所以这也就是为什么这种 min pulling 的方式在这所有的 metric 上全面碾压后面的这些方式。但是当你的数据量逐渐增多了之后,那你在下游任务上去 fine tuning 的这个效果可能也就体现出来一些了。模型也就不那么容易过拟合了。所以这个时候后面这种以带参数学习的方式,可能效果就会稍微好一些,因为他学到这个特征更适合这个下游任务。所以我们这里可以看到这种 sequential type 的Transformer,或者这种 tight type 的Transformer,它的效果就会好一些,但是也仅仅就比这个 mean 铺令的方式好一点点。差距并不显著。
那这个现象光是 MSR v t 数据集独有的吗?其实并不是,我们接下来看表2、表3、表4、表 5 就分别在另外四个数据集上的结果。
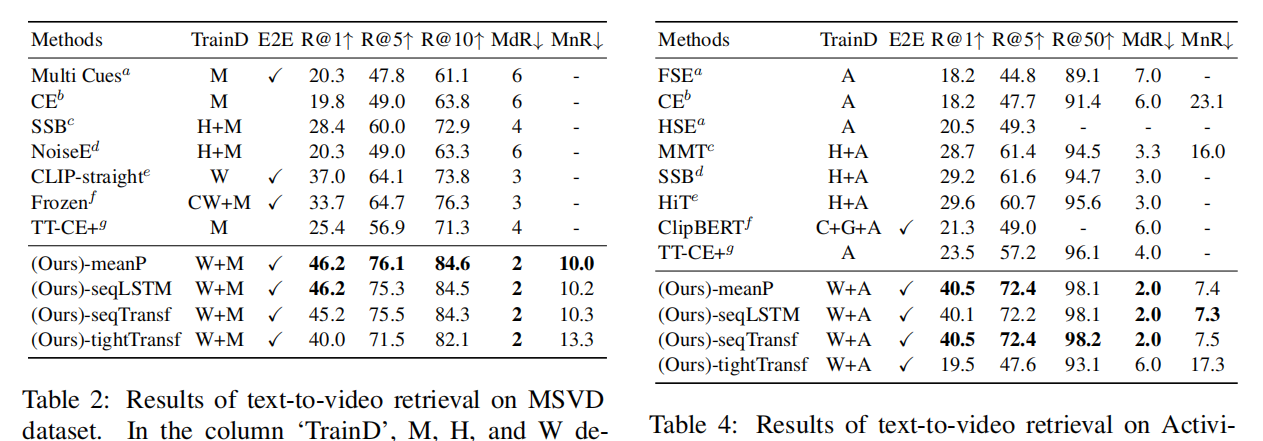
我们也都会发现这个 min pooling 的结果往往都比较好,经常是最好的。然后当下游这个数据量比较大的时候,有时候这样这个 sequential transform 的效果会好一点。比如说像 activity net,它就有一两万个视频,所以训练数据量相对丰富。所以其实这就是第二个observation,这个 min pulling 的这个方式,它的效果很能打。这也就是我之前说的,虽然它有那种缺陷性,它没法把这个时序信息建模进去,仿佛可能有一些例子它没法做。但在现实生活中,这个mean pooling 的方式已经工作得很好了。往往大家为了简单和这个速度,都是直接选择mean pooling,而不会选择在后面再加一层 LSTM 或者 Transformer 去做这种时序上的融合。
结论
那最后我们来看一下结论,作者说本文其实就是利用了一下这个预训练好的CLIP,来示例一下它在 video text retrieval 领域效果如何。鉴于图像和视频的区别,作者考虑了 3 种,这个 parameter free, sequential type 和 tight type 三种计算这个相似度的方式。那最后发现往往是这种 parameter free 就是 mean pulling 的这种方式效果最好,有的时候这个sequentialtype 也不错,但是这个 tight type 是完全不行,作者觉得这很有可能是下游训练数据集不够造成的。如果硬要去在这个已经训练好的这个文本图像的这个空间里去微调它,反而有可能会这个画蛇添足。然后经过了一些这个实验,也就是作者 team 里说的 empirical study 之后,本文在五个数据集上都获得了非常不错的结果,
insights
那除了这些非常好的结果之外,作者还给了一些insights。其实对于这种 empirical started 的论文来说, Insights 是最重要的,大家想看的也就是这些Insights,因为毕竟那些技术是之前都已经有的。
那首先第一个说的意思就是说用 clip 的这种图像特征也是能够提升这种视频的任务的。
第二个就是毕竟你有这种 domain gap,对吧?你是从图像转到视频,所以说如果你能在视频这边找到足够多的训练数据集,去再 post Pre train 一下,就是你 clip 预训练完之后,你再在视频这边再预训练一次,那你这个迁移效果就是迁移到视频这边来以后效果就会好不少。但同时这也就是一个 trade off,因为如果你再去做一次这个 post Pre train,其实你的计算代价也是很高的。
那第三个就是对于视频来说,你也可以用这种 2D 的Patch Linear projection 或者3D的Patch Linear.Projeciton.从实验来看, 3D 会稍微好一些,因为它毕竟在一开始就融合了这种时序的信息。
然后这个 sequential type similarity 也会好一些。
最后他说把 clip 用到这种视频文本的注入 retrieval 上,他对这个学习率是非常敏感的。这个也确实如此。其实从之前 MOCO 开始就是 backbone 还是 Resnet 的时候,就会发现,如果你用这种无监督训练好的这个模型参数,当你去做下游 fine tuning 的时候,最后的结果就会对这个学习率非常的敏感。当时我记得我也提过 MOCO 的那个 learning rate,这已经设到了30,是一个非常不可思议的数字。那现在在训练 transform 的时候,我们也发现这个 learning rate 基本上是最重要的超参数,可能都没有之一。像 layer wise,DK,它其实也是在做 learning rate 的调整,各个模型能不能训练成功,往往也都是这个学习率选择的正确还是不正确。所以说去调这个学习率,这个超三是非常非常重要的。如果想获得更好的结果,不妨再去做一下 grade search,多试几组这个学习率诶,有可能你就能得到一个很好的结果。
3.动作识别Actionclip
那说完了 video text retrieval 接下来我们就来看一下视频理解里另外一个更火的方向,就是动作识别。其实我们之前也讲过很多论文了,也串讲过,它其实就是一个分类任务,只不过做到视频里就加上了额外的这个时序信息。但既然是分类任务,那 CLIP 模型肯定很容易就能应用过来,那detection, segmentation 这些都已经用到 CLIP 了, action recognition 怎么可能不用?所以说在 CLIP 出来半年多之后,这个 action CLIP 这篇论文也就出来了。
3.1 研究动机
但具体的研究动机是什么?我们为什么想用CLIP?那我们来看一下之前的方法视频理解这个动作识别都是怎么做的?往往来说就是你有一些视频,然后你给一个这个视频的编码器,无论你是 2D 的或者 3D 的,那总之你最后给我一个这向量有可能 512 为、2048 维。然后过一个分类头,我就得到了我的这个输出。那一旦有了这个输出之后,我就去跟标好的数据集里这个 ground truth 去做对比,直接就 cross entry loss 一算就能把这个网络训练起来了,但是这里面就有一个巨大的局限性,就是对于有监督学习来说,我是一定需要标签的。
但是对于视频理解,尤其是动作识别来说,怎么定义这些标签,怎么去标记更多带标签的数据,而这些都是非常困难的问题。因为对于物体来说,比如说你标记一个Imagenet,它里面毕竟是有很多生活中常见的那些物体,而且这些物体的概念是非常清晰的,比如说苹果就是苹果,狗就是狗,而桌子就是桌子。所以这个时候如果你用这种 one hot label 去当它的 ground truth,其实是没什么问题的。但是对于动作识别来说,这个问题就完全不一样,那比如说在动作识别这边的数据集里,它有的时候有抽烟,有的时候有打电话,还有开门 open the door,但这个时候你会发现它变成一个短语了,而且它开 open 这个词它可以用来描述很多动作,它可以是开瓶盖儿,它可以是开门儿,它可以是开窗户,它可以是打开一本儿书还它甚至还可以是 open your mind。这一下就变成一个组合问题了,所以说它潜在的这个 label space 是接近于无穷的,那这里面就有一个 trade off 了。如果你标记很多类的话,那这个时候首先你的这个人工标注的费用就很高。其次当你有这么多类别的时候,可能 Softmax 就不工作了,你很难用常见的这种分类算法去做一个很好的模型,你得想新的方法。但如果你说,诶,我就把最常见的那些类标出来,或者说我就把那些大类标出来,那接下来如果遇到新的类怎么办?如果遇到细粒度的类怎么办?这些就又成了问题。
所以说对于动作识别来说,如何能摆脱这种带标签的数据?如何真的能够从很多很多这种海量的视频数据里千去学一个比较好的特征,然后再去 Zero shot 或者 few shot 做下游任务,那其实是最理想的。那基于此,基于这个研究动机,那再用上 CLIP 其实就是非常合理了。因为 CLIP 本身就是能做很好的 Zero shot,那如果能把 CLIP 迁移过来,那在动作识别里也能做 Zero shot 该有多好?一旦我们有了合理的这个研究动机,那接下来就是看啊怎么把 CLIP 沿用过来了。
那我们来看图一的下半部分,就是作者提出的这个 Multi model 的 framework 是怎么做的
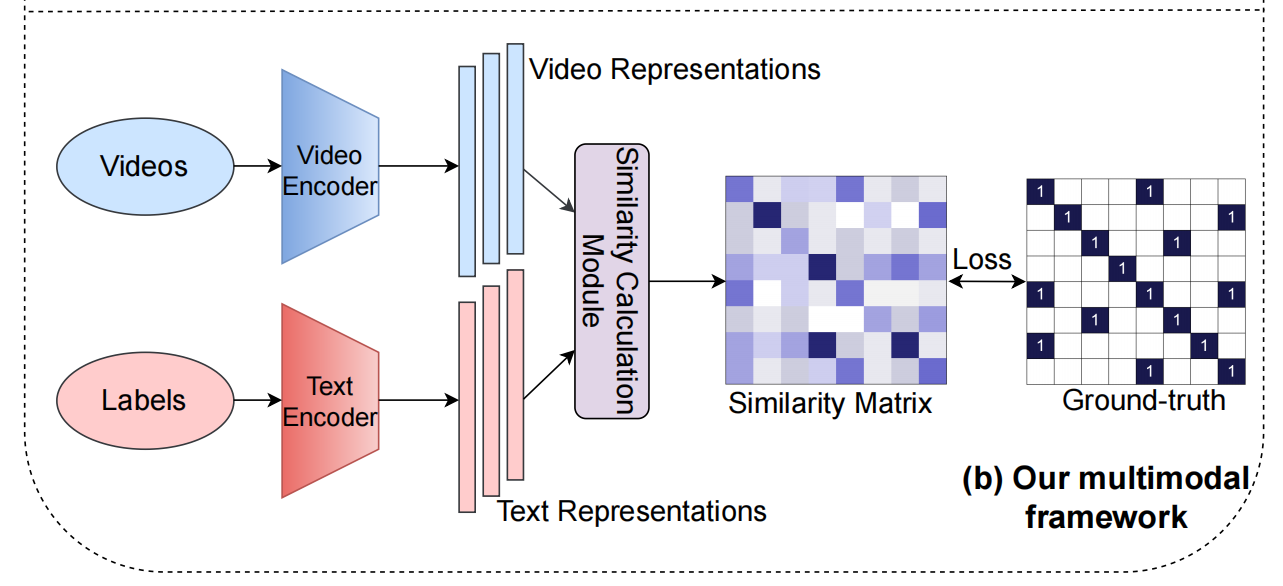
其实跟 CLIP 是非常像的。首先是视频的输入过一个视频的编码器,得到一些特征,然后把标签当做文本,给一个文本的编码器,得到一些文本的特征,接下来就去算文本和图像之间的这个相似度就好了。那一旦得到这个相似度矩阵,那就去跟我们提前定义好的 ground truth,就算一个 loss 就行了。
3.2 改进
但是这篇论文改进还是有的,主要是在两个方面,第一个方面就是如何把图像变成视频,就是这一块该如何去算这个相似度?但其实我们后面会看到这个,就跟我们刚才讲过的那篇论文 clip4clip 非常非常的接近,因为其实图像变视频也无非就是那些做法。也很难玩出什么别的花样来。
那第二个改进就是对于 CLIP 来说,CLIP 是一个完全无监督的方法,它的 ground truth 是来自于网络上这种匹配的图像文本对,所以说从数据集收集的这个角度上来看,它每一个图像文本对都是独立的。所以在当时我们讲论文的时候也提到过 CLIP 的这个正样本,它就是这个对角线上的才是正样本,所有剩下的区域都是负样本。那在这篇论文里情况就不是这样了,因为在这篇论文里它用的这个文本就是那些标好的标签。所以这就会出现一个问题,就是当你这个 batch 比较大的时候,它的同一行里或者同一列里就会出现多个正样本,因为有可能你第一个样本也是跑步,这个样本也是跑步,后面可能还有别的样本也是跑步,它们都属于这个跑步这个标签。所以这个时候它不再是一个 one hot 的问题,它这个矩阵就变成这个样子了,它不是对角线的地方,也有正样本的存在。我这个问题是比较好解决的,作者其实在文中就说了一下,他们就把 cross entry loss 换成 KL divergence 就好了,就去利用两个分布的相似度,就算这个 loss 就好了。
3.3 主体方法部分
那么接下来就来看一下文章的这个主体方法部分,其实也就是另外一个改进,如何把 CLIP 迁移到这个视频领域来做这个动作识别。作者这个图 2 其实画的有点复杂,牵扯的内容非的多。我们先大概放大一点看这个流程图,也就是这里这个部分。
我们会发现从这个整体输入输出的角度来看,其实它跟 clip 或者跟前面我们讲过那个 clip for clip 都很像。
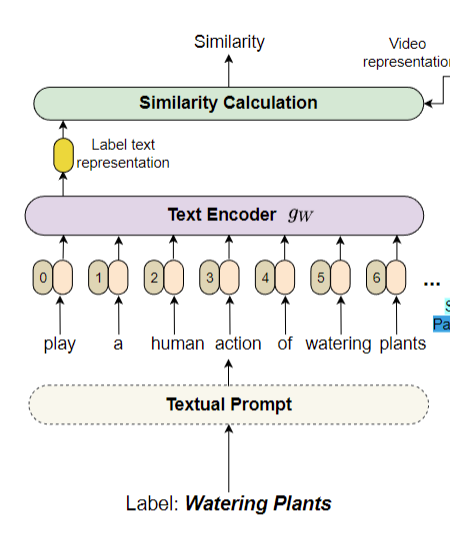
对于文本标签来说,它这里先过一个 text prompt,这个我们一会说这个也可以先不考虑。然后这个句子就变成token,然后过一个文本编码器,然后最后得到一个单一的文本表示
你在视频这边也是视频的帧一个个过 linear projection 得到一些 vision token,然后就给一个 Pre network prompt,这个我们也可以暂时不考虑,其实就是给了一个视频的一个编码器,最后就得到一个视频的输出,
那这个视频输出和文本输出直接去做这个相似率计算就好了。
而接下来作者就搞了一些比较 fancy 的东西,也就是利用了一个最近大火的概念,它叫做prompt。那其实这里除了文本这边的这个prompt,还是原始的那个 prompt 的意思。在视觉这边儿,不论是它定义的这个 Pre network in network, a postnetwork prompt 其实都已经不是原始的 prompt 的意思了,它这里可能也就是为了整体写作的这个连贯性,所以把这些通通都叫做了prompt。其实视觉这边加的东西更有点像加了adapter.不过 prompt tuning 、 adapter, LoRA.什么最近的这些 efficient fine tuning 的方法,他们都非常接近,我们回头也会有一期串讲,专门来讲这些方法是一个非常好的研究方向。这些方法的目的其实都是在原来已经训练好的预训练参数之上,通过加一些小的模块儿,然后通过训练这些小的模块儿,能够让这个已经训练好的模型参数能尽快地迁移到这个下游任务上去。
3.3.1 文本 prompt
那接下来我们就先从这个文本 prompt 开始,最简单的开始看看这个 prompt 是什么意思。然后再一个把视觉这边的这个 Pre network, in network, post network prompt 都大概过一下。那首先为了和视觉这边儿 Pre、in 和 post network 对应起来,它文本这边儿也做了 prefix close suffix prompt 其实就是前缀、完形填空,后缀的意思。那我们一看它给的例子,其实就非常容易理解,

那对于前缀来说,它就是说在原来的这个标签之上,比如说打篮球,它在后面告诉你这是 a video of action,它是一个视频的动作。其实就是又解释了一下。
然后这种完形填空的prompt,那其实就是在中间加个什么东西,那就像它这里说的一,这是一个什么样的标签?它代表了一个视频的动作,
最后就是后缀,那显而易见它就是放在后面,就是说这是一个人类的动作,这是什么一个动作?
所以总之文本这边的 prompt 是非常简单的,它跟 CLIP 里的那个 prompt engineering 或者 prompt ensembling 其实就是一个东西,只不过作者这里把它 劈成了三类,去跟视觉那边对齐。
3.3.2 视觉 prompt
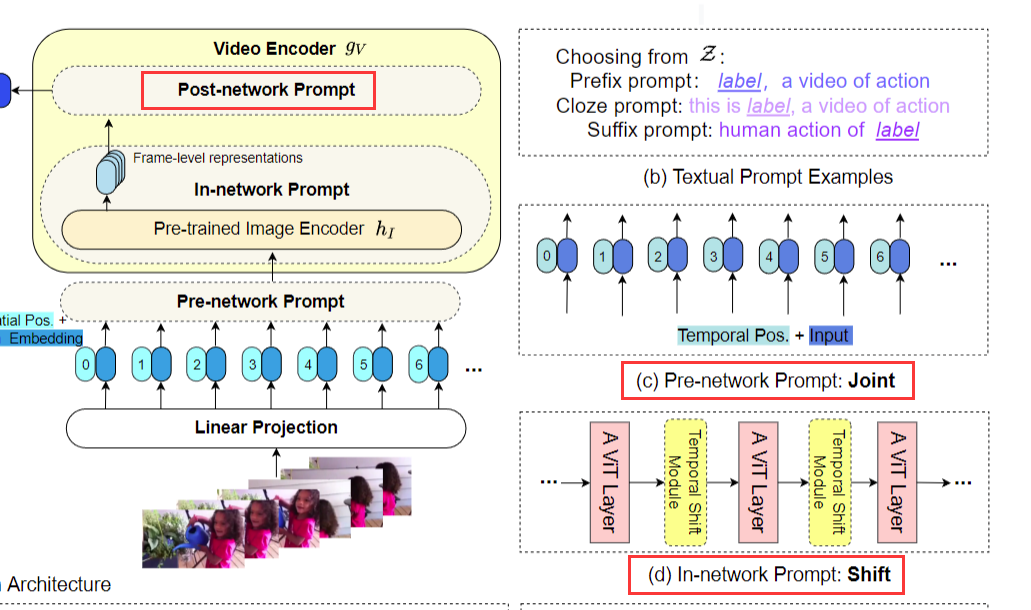
那接下来我们就挨个儿看一下视觉这边儿的 prompt 是怎么做的。
首先最开始的这个 Pre network prompt 叫joint,这个其实很简单,它的意思其实就是把时间和空间上的 token 都放到一起,然后直接扔给网络去学习,他这里一开始也会把时序上的这个 positioning embedding 也加进去一起学,所以这就是作者这里说的这个 Pre network prompt。在输入层面加了一些东西。
那第二个 in network prompt,其实它就是利用了之前shift的这个概念,最开始好像是 1718 年的时候,在图像那边先被提出了。它就是在特征图上做了各种各样的这个移动,然后达到更强的这个建模的能力,但是并不介绍更多的参数,也不增加运行复杂度。所以我记着那篇论文的卖点好像就是说 Zero cost, Zero memory ,就是什么额外的开销,其实都是0。后来这个概念被引入到了视频领域,因为视频领域需要学这种时序上的改变,所以 19 年的那个 TSM 那个论文就把 shift 这个概念用到了这个时序领域。然后 shift 这个概念就大火了,因为不光是简单高效,而且确实效果是非常好,因为我记着 something 这个数据集当时可能还是四五十的这个准确度,结果 TSM 一出来就刷到快60了,非常的厉害。然后最近其实 swin Transformer 也是利用了这样同样的 shift 的概念,他提出了这个shift window。所以说在这篇论文里,作者就把这个 shift 这个操作拿过来放到了每一个 VIT block 的这个中间,它就又加了一个这个 TSM 的这个module,就增强模型的这个时序建模的能力,但是又不引入过多的参数和计算量。
最后就来到我们这个 post network prompt,其实这里就跟 clip4clip 是一模一样,原因就是因为你现在得到了很多这个单帧的这种表示![]() a frame level 的representation。但是如果你要去和文本这边儿单个特征去做这种相似度计算的话,你最好是把它先总结成一个 video level 的 representation 去做比较好。那这个时候就出现了怎么把 10 个特征变成一个特征?那我们现在来看一下作者提出的三个方式,
a frame level 的representation。但是如果你要去和文本这边儿单个特征去做这种相似度计算的话,你最好是把它先总结成一个 video level 的 representation 去做比较好。那这个时候就出现了怎么把 10 个特征变成一个特征?那我们现在来看一下作者提出的三个方式,

我们就会发现其实都一样,连名字都叫的一样。
- 第一个就是mean pulling,
- 第二个就是用 LSTM 或者 one d convolution,
- 最后一个就是加一个 temporal Transformer,
跟刚才那篇论文完美对应,所以就再次验证了把一个图像的工作迁移到视频里,能玩的几种方案无非就是这几种,没有什么太多的选择。那因为这里都一样,所以我就不过多介绍了,总之他们的目的就是把多个特征融成一个特征,希望最后的这个特征既能兼顾 appearance information,又能兼顾temporary information。
3.4 实验
那接下来我们就来看一下这篇文章的实验,这篇文章其实它这个消融实验是非常有意思的,作者是以问题的方式给你呈现出来,每次都先问一个问题,然后再尝试去回答。
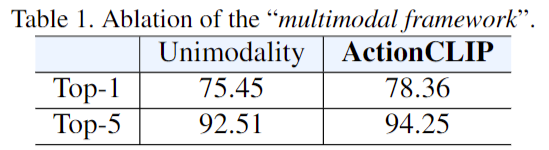
1、Multi model framework 到底有没有用
比如说最开始他就说他们提出的这个 Multi model framework 到底有没有用,也就是说把那种 one hot 的标签变成这种 language guided目标函数有没有用?作者这里就仿照他们这个 action CLIP 的这个框架,保持模型不变,输入不变,这个特征融合的方式不变,什么都不动,只是把最后的目标函数换一下,他就发现这种 Uni modelity 他们这个 baseline 其实就只有 75 的 top one,但是他们提出的这个 action CLIP 框架就有78,这三个多点的提升还是非常显著的,也就证明了他们这个 Multi model framework 也就用 language guided 的这种方式是更合理的。
2、Pre train 的阶段到底重不重要?
那作者接下来第二个问题,就是说他们提出了一个框架叫做 Pre train,然后prompt,然后 fine tuning,是一个三阶段的方式,那在这三阶段里头,这个 Pre train 的阶段到底重不重要?这个其实答案很不言而喻了,因为你图像也是 RGB 图像,那你也做的是个分类任务,所以肯定用上 clip 这个预训练参数是会更好的。那从这个图里看出来也毋庸置疑,你如果随机初始化结果很差,这 36 你连一半的这个准确度都不到,那是因为你的训练数据量也不够。最开始这个 vision Transformer 提出的时候就已经说过了,训练数据不够的时候是很难训练出来的一个很好的模型的。那如果现在这个文本端也用了这个 clip 初始化,图像端也用了 clip 初始化,就可以看到最后的这个性能是非常之高的。另外一个比较有意思的就是,其实文本这边的初始化没有什么关系,即使文本这边是随机初始化,最后的结果也有 76 点多,也就掉了一个多点,并不是那么显著,所以这个问题也很有意思。

我们之后讲多么态的串讲的时候也会提到,基本现在所有多模态的工作都把更多的注意力放到了视觉这边,而且这个模型的初始化一般也都用 vision Transformer 去初始化,从来不用 Bert 去初始化。因为往往用 vision Transformer 初始化效果就很好,但是用 Bert 初始化就根本训练不起来。是一个非常有意思的现象。
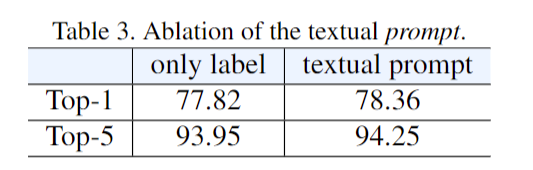
3、提出的这个 prompt 有没有用?
那作者接下来第三个问题,也就是这篇文章的亮点,就他提出的这个 prompt 有没有用?那我们先来看这个文本的prompt,其实就跟刚才的初始化一样,文本端这边不论是初始化还是这个prompt,基本都没什么用。我不用这个 prompt 也就掉了零点几个点而已。
但是如果我们来看视觉这边的话,这个结论就完全不一样。
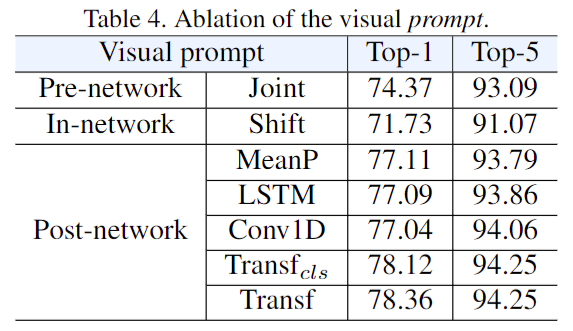
对于 Pre network 和 innetwork prompt 来说,它基本没什么用,掉点是非常显著的,尤其是用了这个 in network shift 之后,它的这个性能 71 比最高的 78 掉了 7 个点,非常的显著,说明它甚至拖了这个 clip 模型的后腿。
比较有用的就是这个 post network prompt 了,这个结论跟之前的 clip4clip 那篇论文的结论也是比较一致的。首先就是在这个模型的后面加这么一些层,能够把这个时序信息融合进去,那它对于视频理解来说肯定是效果要好一些的。其次就是说用了 Transformer 的这种结构,它的结果也好一些。这里稍微和 clip for clip 不太一样的,就是说对于 clip for clip 来说,他们的那个 min pulling 的结果非常的强,但在这里minpoling 不太行。原因还是因为对于动作分类来说,它的这个训练数据集还是相当大的, something 20 万个视频, K 40020 多万将近 30 万个视频,所以它这个量用来做fine tuning 是足够了。但是对于 video test retrieval 那些一两万甚至只有几千个视频的数据集来说,它就不足以去 funtune 这个模型。所以对他们来说 main pulling 更好,但是对动作识别来说有更多的数据,所以他们这个transformer 就更好。
4、Zero shot 和 few shot 的能力
但总体来说,这两篇论文的观察和结论都是比较一致的。那最后我们还想提一下的,因为本文的研究动机就是说用了 CLIP 之后,我们有可能可以做这种 open word 的setting,也就是可以做这种 zoshot 了。所以作者在图 3 里也展示了一下 Zero shot 和 few shot 这个能力,

这三张图分别是在K400, HMDB51 和 UCF 101 上的结果,最左边的这条虚线其实就代表的是 Zero shot 的能力。作者这里说之前的那些方法,不论他有多么的强,但他们都没法做Zero shot。所以对于他们而言,他们的 Zero shot 的能力就是0。但是 action CLIP 就可以直接做,因为它只需要去算这个文本和图像的这个相似度就可以了。所以说它一开始这个性能就已经非常之高了,它甚至比之前的方法在 few shot 这种情况下性能还高。
第二个就是如果我们接下来看 feel shot 的能力,下面从一个样本,两个样本,四个样本八个样本我们可以看到 action clip 也可以继续地在增长,但它的增长其实是比较缓慢的,因为它主要的能力其实都来自于clip。在 Zero shot 的时候,它其实也已经用到了CLIP,所以它后面的增长就没有那么快了。但即使如此,在最后 8 个 shot 的时候, action clib 还是在这三个数据集上都超过了之前的方法,但是作者这里也就没有再往下画了。我就在想,比如说对于 UCF 这个数据集来说,那如果到 16 个 sample 的时候,是不是这个 3D rise 50 就超过action CLIP 了?
总结
总之,在视频理解领域,不论你是做 video text retrieval 还是做动作识别,其实我们可以看到它把 CLIP 模型借鉴过来的方式是非常直接的。视频领域也确实比较难,之前那些很有影响力的工作大部分。也都是 empirical study,包括之前的 r 加ED,还有耳熟能详的 times former,还有之前一篇自监督学习这个视频表征的。所以视频这边真的是任重道远,无论是训练数据集、测试数据集、测试指标、模型,以及做什么任务,怎么考虑时序建模,这些通通都是难点,通通到目前为止都是 open question。
4. 其他领域的应用
那说完了在视频领域怎么使用 CLIP 模型,接下来我们就快速过几篇 CLIP 用在其他领域里的论文。
初始化视觉编码器:How much can clip benefit vision-and-language tasks?
第一个就是在 clip 出来之后,很快就有人又把 clip 模型运回到这个 vision language 的下游任务里去了。这个也确实很有意思,因为当 clip 出来之后,本来它就是做多模态的,所以大家更容易想到的是把它扩展到其他领域里去。但这篇文章的作者都是一直深耕多模态的,所以说他立马又把 CLIP 的模型拿来试了试,看看用这个模型初始化能不能带来更多的提升。那类似这种拿问题做题目的论文,往往其实也是 empirical study,他就是想把什么东西拿过来,然后仔细的调研一番,看看这个问题的答案到底是 yes 还是no,还是继续是个open question。那在这篇文章里,最后的答案是yes。就是 clip 模型拿来做这个预训练参数,还能继续提高下游 vision language task 的准确度。但具体来说,其实这篇文章并不需要精读,他们所研究的问题,其实也就是他们的contribution,他们在这里也写了,作者说他们认为他们是第一个做这种大规模的 Imperago study。什么study?就是拿预训练好的 clip 模型当做这个视觉编码器的这个初始化参数,然后再在下游的各种各样的 vision language 下游任务上去做这个 fine tuning,看 clip 的这个初始化参数到底好不好使。所以所有的这些任务、数据集、模型训练的细节,其实都是之前的方法,他们就是把这个视觉的编码器换成了 clip 模型。
语音:Audioclip: Extending clip to image, text and audio
那接下来我们再换一个领域,就是在语音领域里, CLIP 也已经被应用过去了,所以有了Audio CLIP。它就是在 已有的 image text 基础上又加上了 Audio 的这个模态,具体来说他们就是找了一些视频的数据集,因为在视频里它既有这个视频的帧,又有这个文本的标签,然后还有这个对应的语音信息。所以说这三个模态都是同时存在的。那接下来它无非就是仿照着 clip 的这个模型结构,然后再把 Audio 的这个模态加进来就好了。
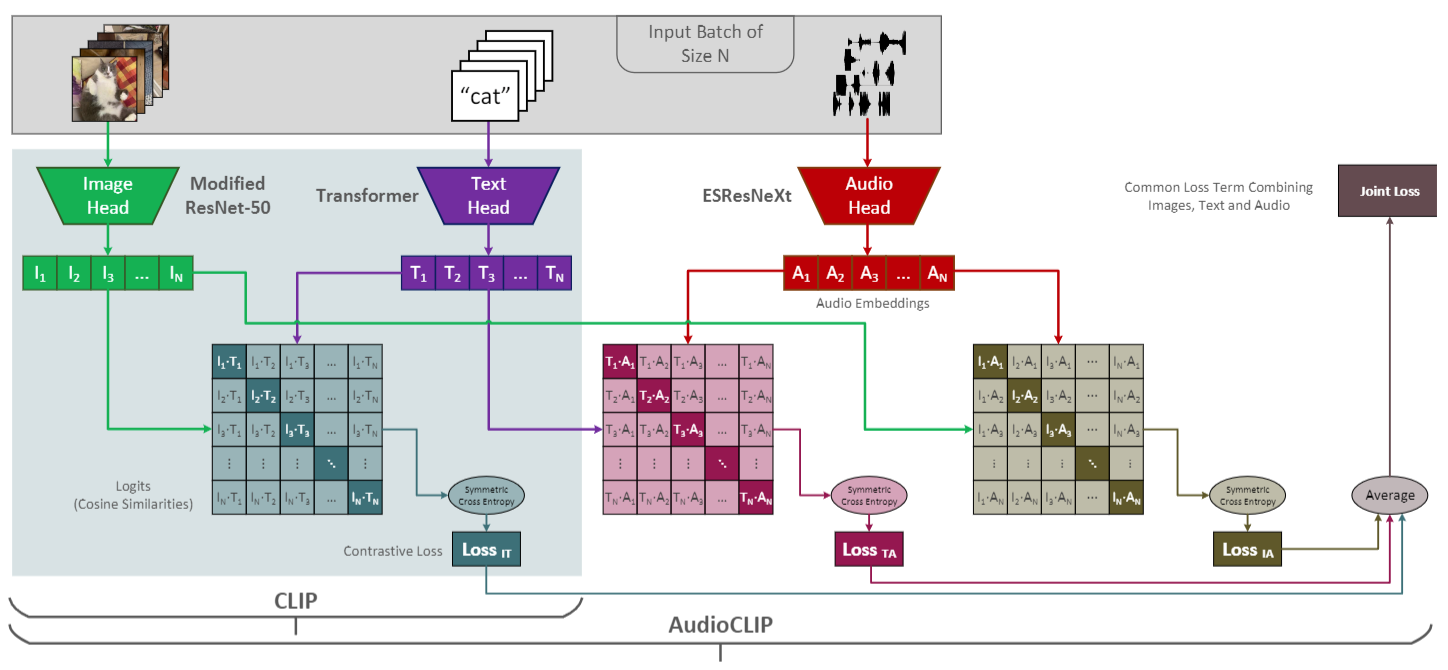
那比如说原始的clip,它就是说文本在这图像在这最后算一个这个对比学习就好了。
那现在就是新增了一个语音的模块,那这边是一些语音的这个频谱输入,然后通过一个语音的编码器之后,就得到了一些语音的特征,那这个语音编码器用的就是一个叫 ES breast next 模型,那因为对于一个视频数据集来说,你的这个文本图像和语音其实都是成对,或者说成 triplet 出现。所以说你这里也很容易模仿CLIP,就做这种正样本对,负样本对,然后从而做这种对比学习。
那这里这个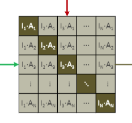 就是说怎么做文本和语音之间的对比学习。
就是说怎么做文本和语音之间的对比学习。
那下面这个相似的矩阵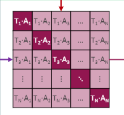 就是在算图像和语音之间的这个目标函数。
就是在算图像和语音之间的这个目标函数。
那最后只需要把这三个相似度矩阵的这个目标函数加起来一起去更新模型的参数就好了。最后也可以 Zero shot 的去做这种语音分类的任务,所以说 CLIP 模型的强大就强大到这里,它非常灵活简单,你想加其他的模态也很容易加。
3D:Pointclip: Point cloud understanding by clip
那说完了 2D 领域,接下来可以讨论一下 3D 这个point。 clip 其实是今年 CVPRR 的一篇论文了,它其实想解决的问题就是毕竟现在 3D 的那边数据集也很小,很难学一个很好的模型。那如何把 CLIP 里已经学到的这么好的这个 2D 的表征能够迁移到 3D 领域里来?那关键的问题就是怎么把这个 3D 和 2D 找一个桥梁,能让它们连接起来就可以了。
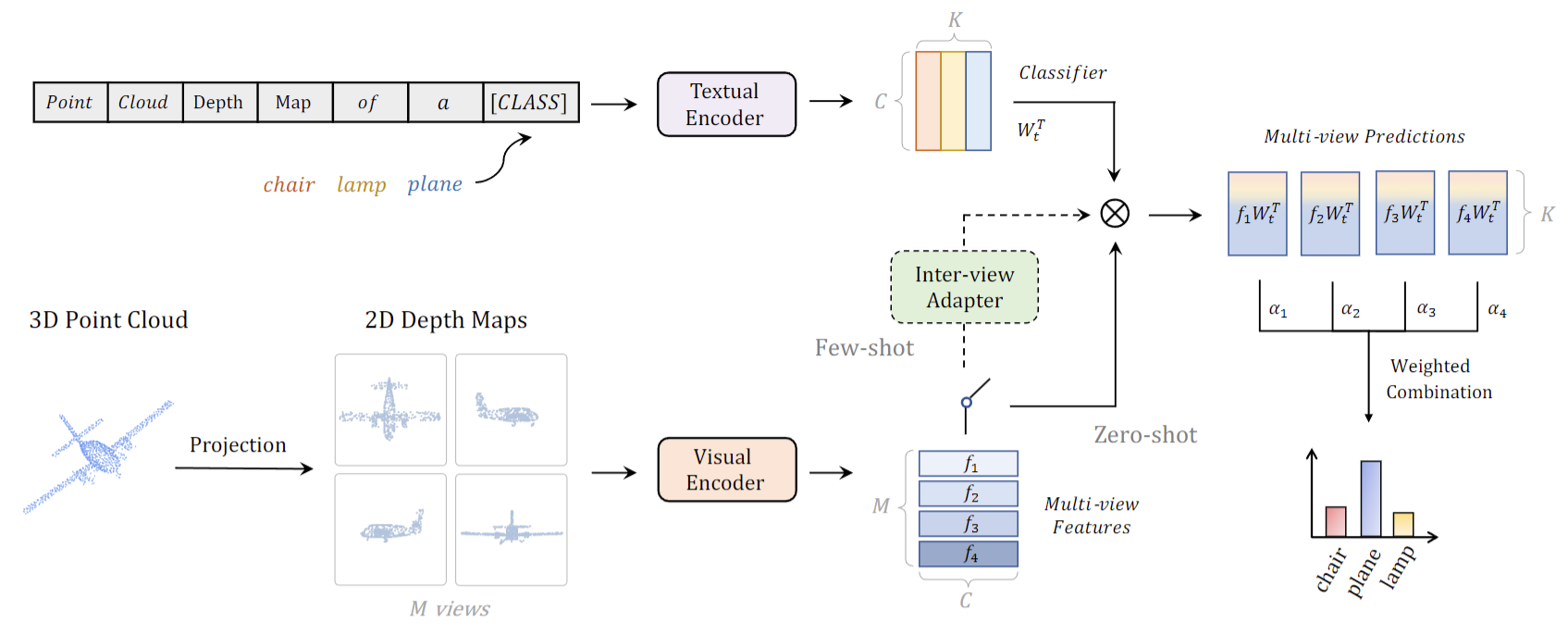
那作者这里很巧妙的就把这个 3D 点云先做了一个投射,投射到 2D 平面上就变成了 2D 的这个深度图。那你一旦变成这种 2D 的深度图之后,其实你就是一个 2D 的图像。那我们在这次最开始讲 clip puzzle 的时候就提到过clip,因为在特别多的数据集上训练过,对,不论你怎么改这个图像的风格,不论是简笔画还是这种 2D 的 depth map,或者说是动画,就是任何一种只要你是 RGB 图像, CLIP 模型都能处理得很好。所以这个时候你只要扔给 CLIP 的这个视觉编码器,它就能给你一些比较好的这个视觉表征。
然后上面文本端其实还是一样,只不过现在这个 prompt 变成了 point cloud depth map。of a。明确的告诉模型,这是一个点云,它是一个点云生成的这个深度图,所以在变相地帮助这个模型去适应这种 3D 变成 2D 之后的这个图像改变,那这样子不仅我们可以做训练,最后也可以做 Zero shot 的这种推理,而了当你把它用到每个单独的领域去的时候,你肯定还要融合一些领域内的知识。这也就是这里这个绿框,这个 interview Adapter 所干的事情。但这里我们就不过多介绍,就只是展示一下大概的这个模型流程图就可以了。
理解深度信息:Can language understand depth?
那最后我们来看一篇更有意思的论文,它的题目是说这个语言能不能理解这个深度信息,因为这个问题确实很难。我之前也说过很多次 CLIP 模型对这个物体非常的敏感,就你要说个篮球、足球人、飞机什么的, CLIP 绝对能给你抓出来,不论你是做什么任务,目标检测、分割,2D, 3D 、识别这些通通都可以。但是如果对于一些概念,他可能理解的不是很好,因为对比学习的这种方式也不太适合去学一个概念。
那这个深度信息其实就有点概念的意思。而且这个深度的远近它有绝对的距离和相对的距离,所以很少会有人去把 clip 用到这个领域里,甚至之前做 Optical flow 或者 depth estimation 这些工作也和主流的 CV 还是略有一些差别的。比如说他们经常就不用初始化,直接 train from Scratch往往结果也就很好了。
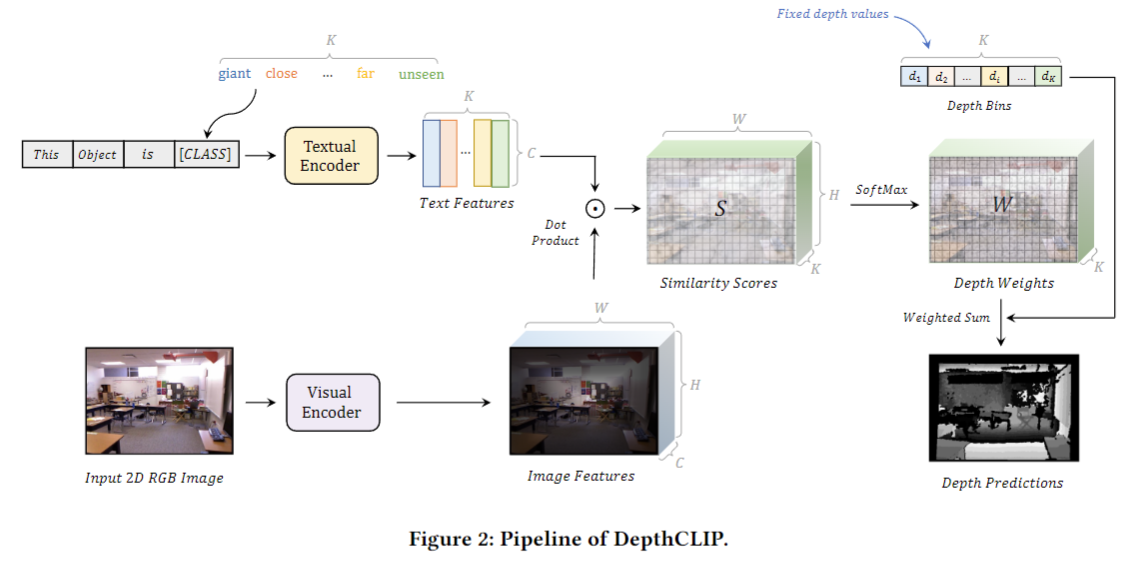
那我们接下来简单来看一下模型的这个方法流程图。那我们乍一看,发现这跟刚才的 point CLIP 的流程图简直好像,尤其这里的这个画图方式,连配色都基本一致,但这也是好事,更方便我们理解了,那作者这里到底是怎么做的?
他其实是把深度估计这个问题给简化了,与其把深度估计看成是一个回归问题,它这里把深度估计看成了一个分类问题。它强制性的把这个深度距离分成了几个大类,也就是它这里说的 a giant close far unsing,它一共分了 7 类,就是从近到远,用这些单词来描述这个距离的远近。那这里这个文本的 prompt 也就变成了 this object is,到底它是近远,看起来大还是小什么的?那这里如果有 k 类,那你最后就会得到 k 个文本的特征,
那接下来我的这个文本通过文本编码器就会得到一些特征,然后我这些特征和文本的特征去做个点称,现在就能得到这个相似的矩阵了。这里我们会发现跟我们上期讲的那个 LSeg 也非常像,对吧?文本的特征乘以视觉的特征,得到一个像素质矩阵,也是 h 乘以 w 乘以k,
那接下来就比较容易了,因为你把它变成了一个分类问题,所以你只需要用 Softmax 一下,然后做一下argmax,你就知道它到底属于哪一类,或者说它的距离到底是多远了。最后你就能得到这样一张深度估计图,
我们这里也可以简单看一下这个实现细节,主要就是来看一下这个七个分类,这个prompt,它这里七个分类其实就是 giant extreme close,意识到最后的这个 far on sing 是从最大变得。越来越小了。然后它这里人为的提前把这些单词都跟后面的这个深度距离做了一个一一对应。也就是说离你最近最大这个物体也就是一米,然后离你越远的物体,它这个距离就越远,这样你就可以把一个深度估计的问题变为一个文本理解的问题。非常巧妙地利用了 CLIP 模型。
总结
到这儿我们就粗略地讲了一些把 CLIP 模型怎么用到各个领域里的一些工作。当然这只是几个我觉得比较有意思或者比较有代表性的工作里,还有很多很多其他优秀的工作。大家如果对某个方向更感兴趣的话,其实就可以看对应那个方向里的论文的参考文献,你也能多多少少找出来一些相关的工作。总之在看完这些论文之后,我们总结一下就会发现。其实大家对 clip 模型的使用无非就是三点。
第一点就是改动最小的情形,我就把我目前的这个图像或文本,通过这个 clip 的预训练模型,我得到一个特征,然后我就把这个特别好的特征跟我原来的那个特征做一下融合,点成或者拼接之类的。然后之前的那个训练框架保持不动,我只是用一个更好的特征去加强我之前的模型的训练,这个就是改动最小的方式,
那中间的方式就是说我把这个 clip 模型有可能当做一个teacher,然后我把它的那个特征拿来做这个蒸馏,不论是前面的特征还是最后的那个特征,我都可以去蒸馏。这样子不论我是做什么模态或者做什么别的task,比如说3D,我都可以拿这个 2D 的模型来蒸馏一些这个预训练好的知识,能帮助我现有这个模型收敛的更快。
那第三种方式就是我不太借助于 CLIP 这个预训练参数,我只是借鉴它这种多模态对比学习的思想,然后我把它应用到我的这个任务里来,然后我去定义我自己的正样本对,负样本对,然后去算这个多模态的对比。学习loss。从而能实现 Zero shadow detection 或者segmentation。
总之这个方向真的是很好,因为毕竟现在训练大模型是一个趋势,越来越多更大更强的这些模型都被训练出来了,那对于下游任务来说,我们不可能针对每一个很小的任务都去训练一个大模型,我们既没有那个数据,也没有那个算力。所以更好的一个问题应该是如何去使用这些已经训练好的模型。所以不论是类似于 CLIP 这样 Zero shot 的方式,还是我们接下来会讲到的 efficient fine tuning 这种 prompt tuning, Adapter 这种 data efficient, memory efficient 方式,去尽量不改变原来大模型的参数,只是加一些可调的这个模块,去训练一点点 1% 甚至 1/ 10000 的参数,然后就能让他在这个下游任务上工作得很好。这个感觉会是一个更有用而且更做得动的方向。
这篇关于CLIP 改进工作串讲(下)【论文精读·42】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






