本文主要是介绍BioTech - ADMET的性质预测 概述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/136438192
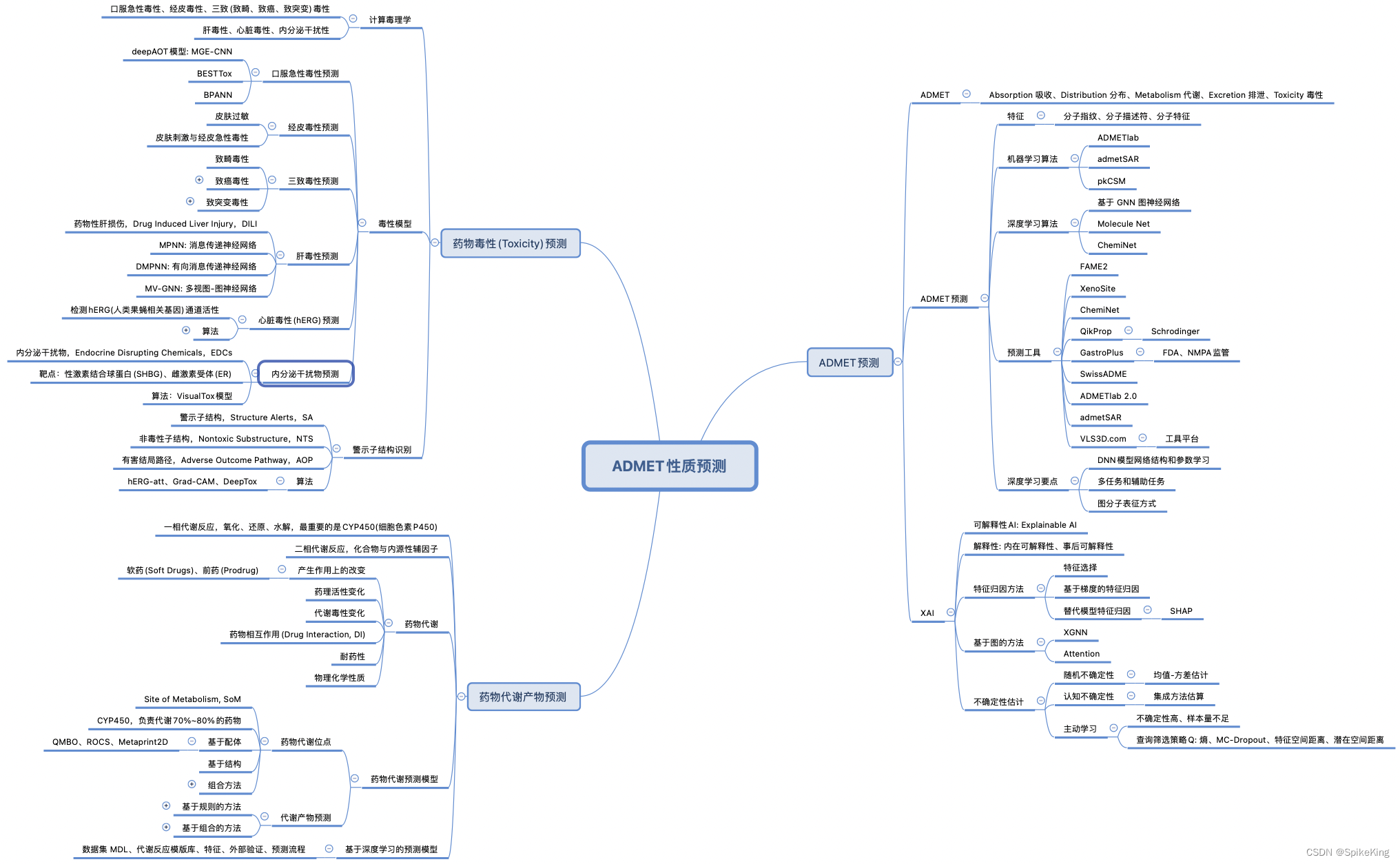
ADMET,即 Absorption、Distribution、Metabolism、Excretion、Toxicity,吸收、分布、代谢、排泄、毒性,这些性质对于药物的疗效和安全性有重要的影响。因此,在药物开发的早期阶段,就能依据化合物的 ADMET 性质,对于先导化合物进行有针对性的选取和优化,是非常必要的。然而,实验评估 ADMET 性质是耗时、耗费和有限的,因此,利用机器学习或深度学习等计算方法来预测 ADMET 性质,是一种有效的替代方案。
1. ADMET 预测算法
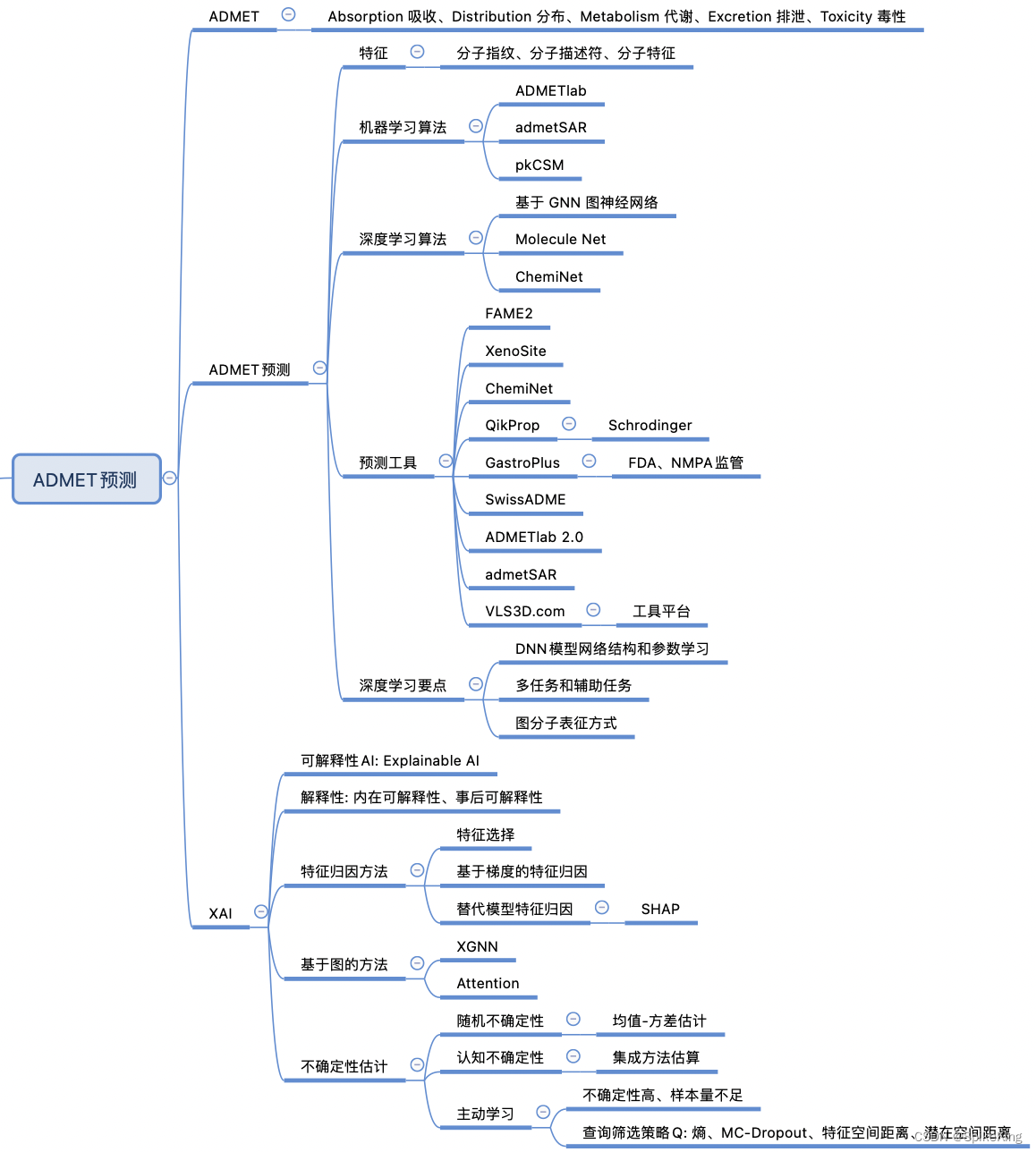
目前,有许多基于机器学习或深度学习的 ADMET 性质预测的算法和工具,主要利用了大量的公共数据库中的化合物数据和相关的 ADMET 实验数据,以及一些专业的特征提取方法,来构建不同的预测模型。例如:
- ADMETboost:基于树的机器学习模型,使用多种特征,包括指纹和描述符,来预测 22 个 ADMET 任务,包括溶解度、血浆蛋白结合、肝脏代谢、肾脏排泄等。该模型在 Therapeutics Data Commons (TDC,治疗数据共享) 的 ADMET 基准数据集上表现优异,对于 22 个任务,该模型在 18 个任务中排名第一,在 21 个任务中排名前三。
- ADMETlab:在线工具,提供了一系列计算模型,包括溶解度、血浆蛋白结合、肝脏代谢、肾脏排泄等,可以预测药物在人体内的吸收、分布、代谢和排泄过程,并且评估其潜在的毒性和安全性。该工具使用多种机器学习模型,如随机森林、支持向量机和 k-最近邻等,以及一些深度学习模型,如多任务图注意力网络等。该工具可以预测 53 个 ADMET 终点,覆盖了多种 ADMET 相关的性质。
- SwissADME:免费的在线工具,提供了一系列计算模型,包括溶解度、血浆蛋白结合、肝脏代谢、肾脏排泄和 CYP450 互作等,可以预测药物在人体内的吸收、分布、代谢和排泄过程,并评估其潜在的毒性和安全性。该工具还提供了一些额外的功能,如药物分子库筛选和药物相互作用预测等。
- XenoSite Web:这是一款非常有用的在线工具,采用多种机器学习算法和特征提取方法,可以帮助药物研究人员更好地了解和预测药物分子在细胞色素 P450 酶(CYP450)中的代谢过程及相应的代谢位点,并生成代谢产物的结构。这对于药物研究和开发来说非常重要,因为 CYP450 酶是药物代谢和毒性的主要通路之一。
尽管基于机器学习或深度学习的 ADMET 性质预测的算法和工具已经取得了很多进展和成果,但是仍然存在一些难点和挑战,例如:
- 数据的质量和数量:ADMET 性质预测的准确性和可靠性很大程度上依赖于数据的质量和数量。然而,目前,可用的数据往往是不完整、不一致、不可靠或不可获取的,这给数据的收集、整理、标准化和共享带来了困难。因此,需要更多的努力来提高数据的质量和数量,以及建立更好的数据管理和交换平台。
- 特征的选择和提取:特征是指用于描述和表示化合物的一些属性或参数,如指纹、描述符、拓扑、结构等。特征的选择和提取对于机器学习或深度学习模型的性能和效率有重要的影响。然而,目前,还没有一个统一的标准或方法来确定哪些特征是最适合或最重要的,以及如何从复杂的化合物结构中提取这些特征。因此,需要更多的研究来探索和开发更好的特征选择和提取方法。
- 模型的构建和评估:模型是指用于预测 ADMET 性质的一些数学或计算的方法或过程,如线性回归、决策树、神经网络等。模型的构建和评估涉及到很多的参数和指标,如训练集、测试集、验证集、交叉验证、超参数、准确率、灵敏度、特异度等。这些参数和指标的选择和调整对于模型的性能和效率有重要的影响。然而,目前还没有一个统一的标准或方法来确定哪些参数和指标是最适合或最优化的,以及如何从多个模型中选择或组合最佳的模型。因此,需要更多的研究来探索和开发更好的模型构建和评估方法。
ADMET 应用场景主要包括:
- 药物筛选:对于大量的候选化合物进行ADMET性质的评估,从中筛选出符合成药要求的化合物,以进入后续的药效和安全性的验证。
- 药物设计:对于已知的化合物进行ADMET性质的分析,从中发现影响ADMET性质的结构特征或分子描述符,以指导化合物的结构优化或改造,以提高药物的成药性。
- 药物代谢:对于药物在体内的代谢过程及相应的代谢产物进行预测和分析,以了解药物的代谢途径、代谢酶、代谢稳定性、代谢活性等,以评估药物的药效和毒性。
- 药物毒性:通过计算方法或实验方法,对药物在体内的毒性效应进行预测和分析,以了解药物的致癌性、致畸性、致敏性、肝毒性、肾毒性等,以评估药物的安全性和副作用。
2. 药物毒性预测
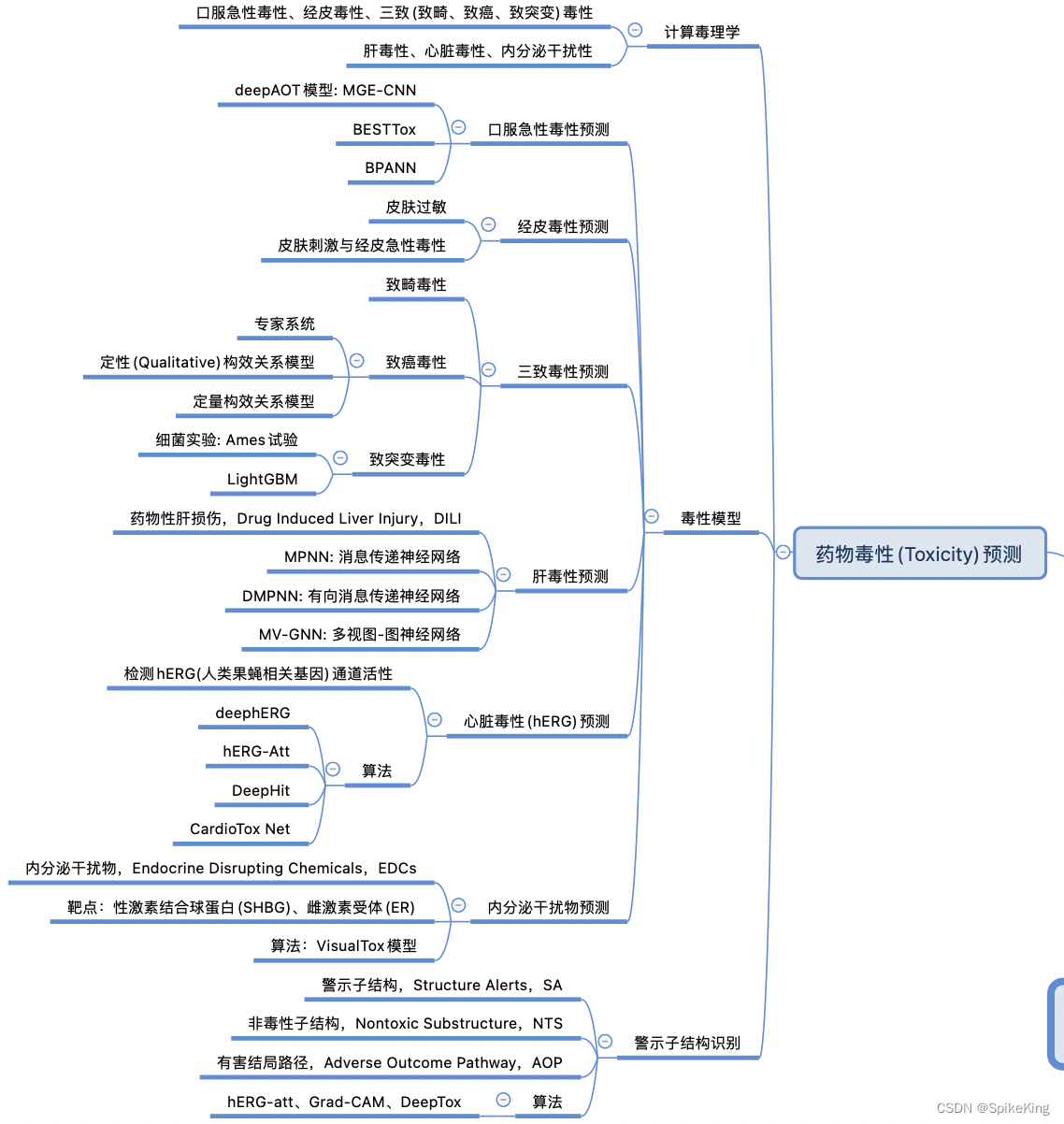
毒性是指化合物对生物体的不良影响,是药物发现过程中的一个重要因素,属于药物的 ADME/T (吸收、分布、代谢、排泄和毒性) 属性之一。药物毒性预测,是指利用计算方法来评估候选药物的潜在毒性,以筛选出安全有效的化合物,降低药物开发的时间和成本。
基于机器学习或深度学习的药物毒性预测是指利用人工智能技术来构建预测模型,从化学结构、基因组数据、高通量筛选数据等各种数据源中提取特征,学习化合物与毒性的关系,预测化合物在不同的毒性终点上的活性或风险。这些方法可以提高预测的准确性和效率,同时也可以减少对动物实验的依赖。
基于机器学习或深度学习的药物毒性预测,也面临着一些难点和挑战,主要包括:
- 数据的质量和数量。药物毒性预测需要大量的高质量的数据来训练和验证模型,但是,目前可用的数据往往存在不完整、不一致、不平衡、不可比等问题,导致模型的泛化能力和可靠性受到影响。
- 特征的选择和工程。药物毒性预测需要从复杂的数据中提取有效的特征来表示化合物的结构和性质,但是,目前还没有统一的标准和方法来选择和构造最优的特征,不同的特征可能导致不同的预测结果。
- 模型的解释性和透明度。药物毒性预测需要模型能够提供可解释的预测结果,以便理解化合物的毒性机制和作用途径,但是,目前的机器学习或深度学习模型往往是黑盒式的,难以揭示预测的内在逻辑和依据。
- 伦理和监管的问题。药物毒性预测需要模型能够符合伦理和监管的要求,以保证药物的安全性和有效性,但是,目前的机器学习或深度学习模型还没有得到广泛的认可和接受,需要更多的验证和评估。
3. 药物代谢产物预测
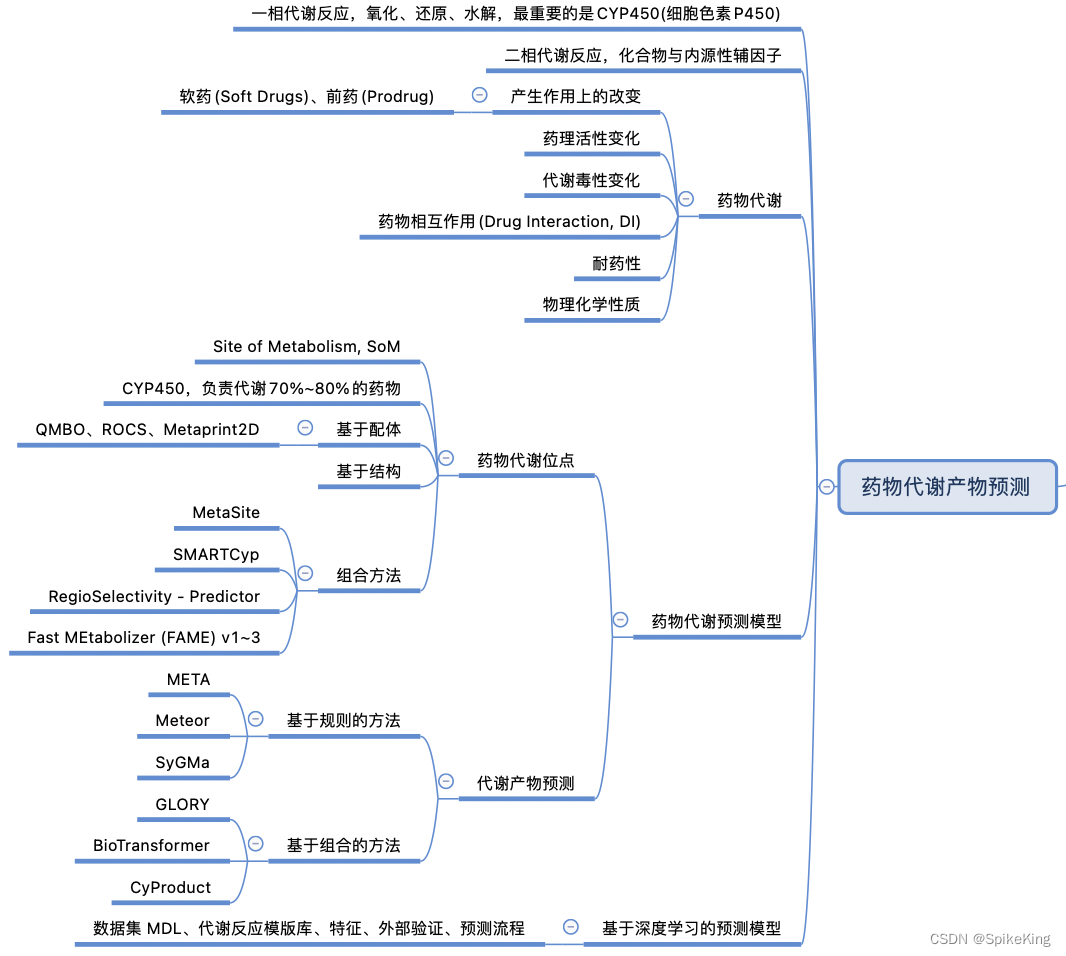
代谢 Metabolism 是药物在体内受酶系统或者肠道菌丛的作用而发生结构转化的过程,是药物代谢动力学 (ADME) 中的一个重要方面。代谢产物预测是指根据药物分子的结构和性质,预测其可能的代谢途径和代谢产物的结构。这对于评估药物的安全性、有效性和药物相互作用有重要意义。其中,细胞色素 P450 (CYP450) 是一类广泛存在于生物体中的氧化还原酶,参与了大约 75% 的药物代谢反应。因此,预测药物分子的 CYP450 代谢位点和代谢产物是代谢产物预测的核心问题。
基于机器学习或深度学习的代谢产物预测是一种利用计算模型和算法,从大量的实验数据中学习和推断药物代谢规律的方法。近年来,这种方法在代谢产物预测领域取得了一些进展和突破,提高了预测的准确性和效率。
药物代谢产物预测的难点和挑战,包括:
- 数据的质量和数量:代谢产物预测需要大量的高质量的实验数据来训练和验证计算模型,但是,目前可用的数据集往往规模有限、分布不均、缺乏标准化和注释,导致模型的泛化能力和可靠性受到影响。
- 模型的复杂性和可解释性:代谢产物预测涉及到多种代谢酶、多种代谢途径、多种代谢产物,以及它们之间的相互作用和影响,这使得模型的构建和优化变得非常复杂和困难。同时,基于机器学习或深度学习的模型往往缺乏可解释性,难以揭示药物代谢的分子机制和生物学意义。
- 模型的适应性和可扩展性:代谢产物预测需要考虑不同的生物体、不同的组织、不同的环境、不同的药物等多种因素的影响,这要求模型具有良好的适应性和可扩展性,能够适应不同的场景和需求,但是,目前的模型往往只针对特定的条件和数据进行训练和测试,难以泛化到其他情况。
CYP450 是细胞色素 P450 的简称,是含有血红素作为辅因子的单加氧酶,广泛存在于生物体中,参与许多重要的生物合成和代谢过程。CYP450 酶可以催化多种有机底物的氧化反应,例如将氧氛中的一个氧原子插入到底物分子中,而另一个氧原子被还原形成水。CYP450 酶在药物代谢中起着关键作用,影响药物的活性、安全性和药物-药物相互作用。CYP450 酶是一个庞大的酶超家族,有许多不同的同工酶和亚型,根据氨基酸序列和结构特征进行分类和命名。
这篇关于BioTech - ADMET的性质预测 概述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








