本文主要是介绍LANA: A Language-Capable Navigator for Instruction Following and Generation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
最近,视觉语言导航(VLN)——要求机器人代理遵循导航指令——已经取得了巨大的进步。然而,现有文献最强调将指令解释为行动,只提供“愚蠢”的寻路代理。在本文中,我们设计了 LANA,一种支持语言的导航代理,它不仅能够执行人类编写的导航命令,还能够向人类提供路线描述。这是通过仅使用一个模型同时学习指令跟随和生成来实现的。更具体地说,分别用于路由和语言编码的两个编码器由两个分别用于动作预测和指令生成的解码器构建和共享,以便利用跨任务知识并捕获特定于任务的特征。在整个预训练和微调过程中,指令跟踪和生成都被设置为优化目标。我们凭经验验证,与最新的先进任务特定解决方案相比,LANA 在指令跟踪和路由描述方面都获得了更好的性能,并且复杂度接近一半。此外,LANA具有语言生成能力,可以向人类解释其行为并协助人类寻路。这项工作预计将促进未来构建更值得信赖和社交智能导航机器人的努力。
引言
开发能够以自然语言与人类交互,同时在环境中感知并采取行动的智能体,是人工智能的基本目标之一。作为朝着这一目标迈出的一小步,视觉语言导航(VLN)[4]——赋予智能体执行自然语言导航命令——最近受到了极大的关注。在 VLN 领域,人们在语言基础方面做了很多工作——教导智能体如何将人类指令与感知相关的动作联系起来。然而,在相反的方面——语言生成——教智能体如何用语言生动地描述导航路线,却很少有工作[27,71,1,78,23]。更重要的是,现有的 VLN 文献分别训练专门针对每个任务的代理。结果,交付的代理要么是强大的寻路演员但从不说话,要么是健谈的路线指导员但从不走路。
本文强调了 VLN 中的一个基本挑战:我们能否学习一个既能够遵循导航指令又能够创建路线描述的代理?
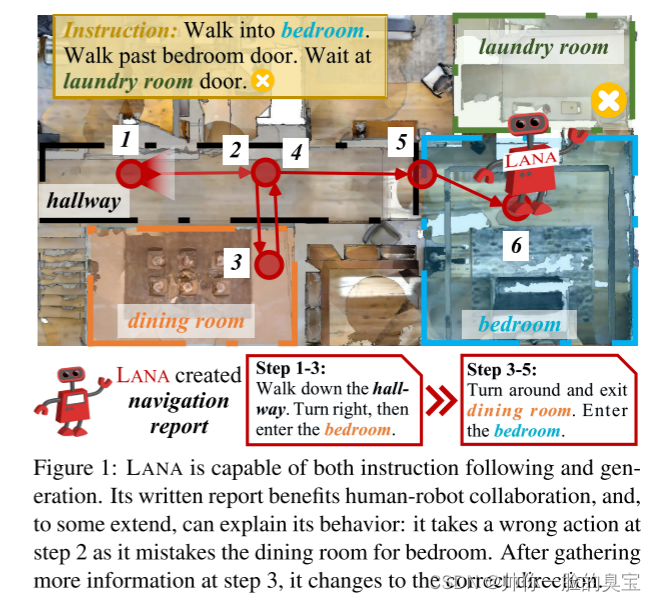
我们提出 LANA,一种具有语言能力的导航代理,它充分意识到这种挑战(图 1)。通过同时学习指令基础和生成,LANA 将人与机器人和机器人与人的通信形式化,并在统一的框架中使用面向导航的自然语言进行传达。这非常重要,因为:i)它完成了人类和智能体之间必要的通信周期,并促进了 VLN 智能体在现实世界中的效用[59]。例如,当代理需要很长时间来执行导航命令时,在此期间持续的人类注意力是不可行且不可取的,代理应该报告其进度[73]。此外,智能体还需要在智能体探索的区域中引导人类 [82],这与灾区的搜索和救援机器人 [72, 19]、公共场所的引导机器人 [78] 以及视障人士的导航设备相关[36]。 ii) 双向通信是紧密的人机协调不可或缺的一部分(即“我将继续这样……”)[7],并增强人类对机器人的信任[6, 24],从而提高导航机器人的接受度。 iii)发展语言生成技能可以制造出更易于解释的机器人,它们可以以人类可读的路线描述的形式解释其导航行为。
从技术上讲,LANA 是一个基于 Transformer 的多任务学习框架。该网络由两个单模态编码器组成,分别用于语言和路由编码,以及基于这两个编码器的两个多模态解码器,分别用于路由到指令和指令到路由翻译。在预训练和微调阶段,整个网络都是通过指令基础和生成任务进行端到端学习的。综上所述,LANA 提供了一个统一、强大的框架,探索模型设计和网络训练核心的特定任务和跨任务知识。因此,即使在没有明确监督的情况下,LANA 也可以更好地理解语言线索(例如单词、短语和句子)、视觉感知、长期行动及其关系,并最终使这两项任务受益。
我们在三个著名的 VLN 数据集(即 R2R [4]、R4R [38]、REVERIE [63])上进行了广泛的实验,用于指令跟踪和生成,给出了一些有趣的点:首先,LANA 使用以下方法成功解决了这两个任务:只需一台代理,无需在不同型号之间切换。其次,凭借优雅的集成架构,LANA 的性能可与最近领先的特定任务替代方案相媲美,甚至更好。第三,与单独学习每个任务相比,在两个任务上联合训练 LANA 可以获得更好的性能,同时降低复杂性和模型大小,证实了 LANA 在跨任务相关性建模和参数效率方面的优势。第四,LANA 可以通过口头描述其导航路线来向人类解释其行为。 LANA 本质上可以被视为一个可解释的 VLN 机器人,配备了自适应训练的语言解释器。第五,主观分析表明我们的语言输出质量高于基线,但仍然落后于人类生成的话语。虽然仍有改进的空间,但我们的结果揭示了未来 VLN 研究的一个有希望的方向,在可解释的导航代理和机器人应用方面具有巨大的潜力。
相关工作
navigation instruction following
构建基于语言的自主导航代理是自然语言处理和机器人社区的长期目标。 Anderson 等人并未将之前的研究局限于受控环境背景 [55,72,10,5,57]。 [4] 将此类任务提升到逼真的环境 - VLN,激发了人们对计算机视觉领域日益增长的兴趣。早期的努力是建立在循环神经网络的基础上的。他们探索不同的训练策略 [84, 83],从合成样本 [27, 71, 28] 或辅助任务 [83, 35, 53, 93, 78] 中挖掘额外的监督信号,并探索智能路径规划 [39, 54, 81]。对于结构化和远程上下文建模,最近的解决方案是通过环境地图[92,13,21,80],transformer架构[33,61,48,64,11]和多模态预训练[56,31,30,12]开发的。
与专门用于follower导航指令的现有 VLN 解决方案不同,我们雄心勃勃地构建一个强大的代理,它不仅能够执行导航指令,还能够描述其导航路线。我们在整个算法中都坚持这个目标——从网络设计到模型预训练,再到微调。通过共同学习指令执行和生成,我们的智能体可以更好地将指令转化为感知和行动,并在一定程度上解释其行为并培养人类信任。我们的目标导航和视觉对话导航[73]是不同的(但互补),因为后者只关注代理使用语言请求人类帮助的情况。
navigation instruction generation
对instruction creation的研究[17]可以追溯到20世纪60年代[52]。早期工作[88,2,51]发现人类路线方向与认知地图[42]相关,并受到许多因素的影响,例如文化背景[74]和性别[37]。他们还达成了共识,即涉及路线导航和显着地标可以使人类更容易遵循指令[50,77,67]。基于这些努力,一些计算系统是使用预先构建的模板 [50, 29] 或手工制定的规则 [18] 开发的。虽然在目标场景中提供高质量的输出,但它们需要语言知识的专业知识和构建模板/规则的大量努力。一些数据驱动的解决方案[16,59,19,26]后来出现,但仅限于简化的网格状或感知较差的环境。
生成自然语言指令长期以来一直被视为社交智能机器人的核心功能,并且引起了许多学科的极大兴趣,例如机器人学 [29]、语言学 [69]、认知 [42, 25]、心理学 [74] 和地球科学 [ 20]。令人惊讶的是,在具身视觉领域所做的工作却很少。对于罕见的例外[27,71,68,1,78,23],[27,71,68]只是为了增强寻路的训练数据,并且所有这些都学习专门用于指令生成的单个代理。我们的想法是根本不同的。我们要构建一个具有语言能力的导航代理,它能够掌握指令遵循和创建。因此,这项工作代表了对社交智能、具体化导航机器人的早期但扎实的尝试。
Auxiliary Learning in VLN
有几种 VLN 解决方案 [53,93,79] 利用来自辅助任务的额外监督信号来帮助导航策略学习。对于辅助任务,代表性的包括下一步方向回归[93]、导航进度估计[53]、路径反向翻译[93, 78]、轨迹指令兼容性预测[93]以及最终目标定位[92] ]。
这些 VLN 解决方案将重点放在指令遵循上;辅助任务是手段,而不是目的。相比之下,我们的目标是构建一个能够很好地掌握指令跟随和创建的单一智能体。尽管[78]在双任务学习方案下同样关注指令跟随和生成,但它仍然学习两个独立的单任务智能体。此外,上述辅助任务原则上可以被我们的代理利用。
Vision-Language Pretraining for VLN
大规模图像-文本对的视觉-语言预训练[65,70,14]最近取得了快速进展。事实证明,可转移的跨模式表示可以通过这种预训练来交付,并促进下游任务[85,47,91,65,44,46]。这种训练方式在 VLN 中越来越受欢迎。特别是,一些早期的努力 [45, 33] 直接采用通用视觉语言预训练来进行 VLN,而没有考虑任务特定的性质。随后,[30,31,12]使用不同的 VLN 特定代理任务对丰富的网络图像标题 [30] 或合成轨迹指令对 [31, 12] 进行预训练。 [11, 64] 引入历史感知代理任务以进行更多 VLN 对齐的预训练。
从代理任务的角度来看,现有的 VLN 预训练遵循屏蔽语言建模机制 [40]。不同的是,我们的预训练基于语言生成,这有助于智能体捕获语言结构,从而达到对语言命令的全面理解并促进指令执行。一般视觉语言预训练的最新进展[87,90,22,86]也证实了生成语言建模的价值。此外,对于 LANA 来说,指令生成不仅仅是预训练后经常被丢弃的代理任务,而且也是预训练期间的主要训练目标。微调,是部署时基于语言的路由导向能力的根本基础。
这篇关于LANA: A Language-Capable Navigator for Instruction Following and Generation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
