本文主要是介绍基于上证指数为标的进行的区间择时买卖点的策略逻辑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于上证指数为标的进行的区间择时买卖点的策略逻辑
大盘在3400点附近是不是还有贝塔,是不是可以持仓等等吧,很玄学的一些东西。 公司给订午餐,貌似 就多出来很多这种玄学的问题七嘴八舌。 有才智的凭借聪明就明白了,有盘感的凭借直觉就可以结论,时间久了不乏有那么一些人,貌似有神通。
也有好奇,n次想着弄出来数据看看,并验证下 历史上究竟有多少时间超过了高分位数。
)进行一个逻辑统计 1、大盘在历史上有多少时间超过了四分之三分位数;有多少时间低于四分之一分位数;
(后面测好验证这句话就是个sb基于上证指数为标的进行的区间择时买卖点的策略逻辑)哈哈。不过,测测才明白的 无妨。
其实看看目前大盘点位在啥位置。一个常规的判断,大盘超过了四分之三分位,那就是哈哈很大可能有75%的概率 要往下走了,直接跟大盘收贝塔的想法 要歇菜吧。
2)验 一个投资策略模型:
在大盘从4分之一分位之下就持仓,一直到 四分之三分位数出场,之上空仓。
从四分之三到四分之一分位这个区间,但是处在下跌过程也不持仓,空仓。只有等到跌破四分之一,才持仓到四分之三。
1 数据和工具
数据:20091231 开始到20200819上证指数 ;
matlab excel 简单的功能足足的。
matlab R2016b 数据处理;之前版本也可以,但是遇到过矩阵的部分运算,如除法不能类比点成一样点除。就这个而言应该问题不大。
excel 作图;
win10 系统。
为什么是这个数据?其实是自己建设数据库就是这一天开始的,用的目前拿到的数据暴力测。
后面结果会发现弊端,然后和需要改进的地方。
所以量化本身不是一个高深的事,只是个有门槛的说法。
2、回测得到统计信息,和持仓信号并作图
基于上证指数为标的进行的区间择时买卖点的策略逻辑
第一个 统计问题的得到的结果, 四分之三之上和四分之一之下 其实是为了检验,肯定是25%的吶,基于上证指数为标的进行的区间择时买卖点的策略逻辑发现逗自己玩的。
主要是 在四分之一到四分之三的区间(即为主要持仓的上升过程,天数仅仅8%),目前的3451 呵呵,在四分之三分位之上的高区间。
基于上证指数为标的进行的区间择时买卖点的策略逻辑
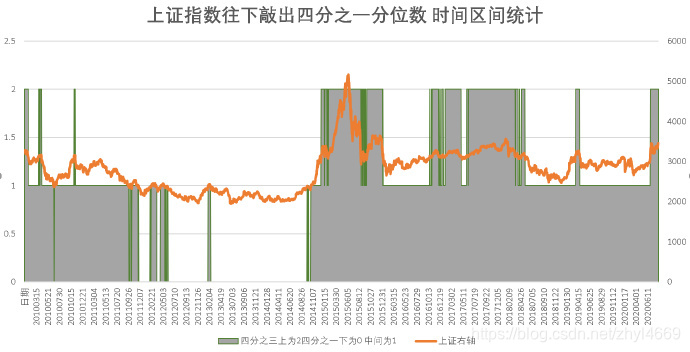

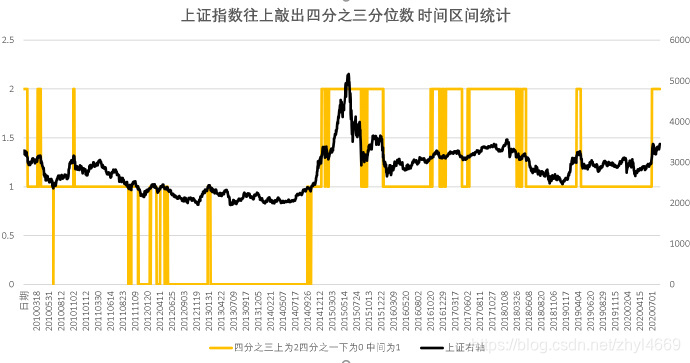
两图一样的 只是信号指标一个用了橘黄色先,一个用了灰色阴影罢了。方便看。
最后只有 6个区间有持仓哈哈,因为2015年开始之后的时间,大盘运行区间变化了,目前再也没有跌破四分之一分位数2366 。
基于上证指数为标的进行的区间择时买卖点的策略逻辑
三、结果 发现很诡异
实则 按照起初的设计 ,统计下来,持仓时间很短的,2014年12月5日之后,就没有时间落在四分之一之下,因此按照这个原则也没有了在四分之一上涨到四分之三这个区间的持仓机会。导致2015年之后要空仓。
嗯嗯想来,
其实这个可以设置一个回测区间窗口,比如以肉眼观察的中长期的区间震荡为窗口进行统计就比较好。
量化投资本来就是一个很神的东西,它的最高艺术还是量化的标的复合常人对现象任职的本质。而不是数据挖掘般的瞎胡搞。
如果真的这样说服不了自己,那就不放引入一个 参数为标的来划分回测区间好了,比如说滚动周期大于2年在某个区间震荡,区幅度不超过100%。就可以把区间划分了。基于区间的分位数去估计引入持仓入场上下限的范围。
棒哒哒。
量化的起点来源于人对已存在的感知和思考,量化作为一种工具让这种思考逻辑成为一个可以被精确执行的可能。而非仅仅混沌数据的挖掘。
想量化,先过感知关。
嗯嗯,自己捣鼓了好久,然发现数据区间这样太长了,需要截取下,来找个理由哈哈。
还是好好敲敲代码吧,然其他都是自动运行,只有数据入口可变,那样自己发现持仓频率不够问题就好优化了。
以上代码大概模块,链接打包下,没啥版权没啥秘密的,拿到软件还不会敲打的入个门吧
%信号:识别数据 四分之一位数之下为0, 四分之三之上为2。四分之一和 四分之三位数之上的部分区间为1,并在下降趋势部分的 1 改为-1。
%策略:上买入中间的、上升区间的部分,其他时间空仓
load indexCode indexCode
load zhibiaoIndex zhibiaoIndex
% 计算指标
IndexCalResult={};
IndexCalResult=zhibiaoIndex;
indicateCal={‘均值’,‘当前数值’,‘四分之三位数’,‘四分之一位数’,‘最大值’,‘最小数’,‘中位数’,‘众数’};
for i=10:size(zhibiaoIndex,1)
load (zhibiaoIndex{i,2}) ;
meanCal=nanmean(FactorSeries);
preCal=(FactorSeries(end,:));%当前
fenwei43Cal=quantile(FactorSeries,0.75,1);
fenwei41Cal=quantile(FactorSeries,0.25,1);
maxCal=max(FactorSeries);
minCal=min(FactorSeries);
zhognweiCal=nanmedian(FactorSeries);%‘中位数’,
zhongshuCal=mode(FactorSeries);%‘众数’,
tempZhibiao = [meanCal;preCal;fenwei43Cal;fenwei41Cal; maxCal;minCal;zhognweiCal;zhongshuCal];
IndexCalResult{i,3} = [indicateCal’, num2cell(tempZhibiao)];
end
save indicateResult indexCode zhibiaoIndex indicateCal IndexCalResult
%%%%%%%%%%%%%%%%%
load indicateResult indexCode zhibiaoIndex indicateCal IndexCalResult
%生成信号
for i= 1:size(IndexCalResult,1)
temp=load([IndexCalResult{i, 2} ‘.mat’]); % temp=load(‘收盘价.mat’);
yuzhiHigh= cell2mat( IndexCalResult{i, 3}( find(strcmp(IndexCalResult{i, 3},{‘四分之三位数’})) ,2:end )); %每个代码的阈值上限
yuzhiLow= cell2mat( IndexCalResult{i, 3}( find(strcmp(IndexCalResult{i, 3},{'四分之一位数'})) ,2:end )); % %每个代码的阈值下限tempData =temp.FactorSeries;IndDaxiaoBiaoji =NaN*zeros(size(tempData) );IndDaxiaoBiaoji (find((tempData>yuzhiHigh) ))=2;
IndDaxiaoBiaoji(find((tempData>yuzhiLow&tempData
IndDaxiaoBiaoji(find((tempData
IndDaxiaoBiaojiXiuzheng=IndDaxiaoBiaoji;% 下面在原来标记上进行标记
for ii=1:size(IndDaxiaoBiaoji,2) %本来为区间数据 都是1, 如果是下降趋势,标记为-1templie=IndDaxiaoBiaoji(:,ii);for iii=2:size(templie,1)if templie(iii)==1ind2= find(templie(1:iii)==2);ind0= find(templie(1:iii)==0);if (~isempty(ind2)&&~isempty(ind0)&&ind2(end)>ind0(end)) || (~isempty(ind2)&&isempty(ind0))IndDaxiaoBiaojiXiuzheng(iii,ii)= -1 ; % 把本来为1的区间数据,的下降趋势 的区间的 数据标记为-1endendendend
IndDaxiaoBiaojiXiuzheng(IndDaxiaoBiaojiXiuzheng==2)=0;% 把本来为2的阈值之上,变为0,以方便高位不再持仓
IndexCalResult{i,4}= (IndDaxiaoBiaoji);
IndexCalResult{i,5}= (IndDaxiaoBiaojiXiuzheng);
end
save IndexQujianSignalResult IndDaxiaoBiaoji IndDaxiaoBiaojiXiuzheng indexCode zhibiaoIndex indicateCal IndexCalResult
%% 模拟净值 计算。以上出来了 四分之一位数之下 和 四分之三位数之上的部分区间;四分之一位数买入,到了四分之三位数卖出,其他时间空仓。
load IndexQujianSignalResult IndDaxiaoBiaoji IndDaxiaoBiaojiXiuzheng indexCode zhibiaoIndex indicateCal IndexCalResult
Close=load(‘收盘价.mat’);
ret=[zeros(1,size(Close.FactorSeries,2));tick2ret(Close.FactorSeries)];
retQujianChicang= IndDaxiaoBiaojiXiuzheng.*ret;
netQujianChicang= ret2tick(retQujianChicang(2:end,:));
Datestr=cellfun(@(x) {num2str(x)},num2cell( Close.DateW )); % 代码规范)
Data=cellfun(@(x) {[x(1:4),’/’,x(5:6),’/’,x(7:8)] },Datestr); % 代码规范)
DatawithTime=datenum(Data,‘yyyy/mm/dd’);% 数据和日期
save IndexQujianStrategyResult netQujianChicang DatawithTime indexCode zhibiaoIndex indicateCal IndexCalResult IndDaxiaoBiaoji IndDaxiaoBiaojiXiuzheng
%画图
legent1=indexCode(:,2);
fig = plotDateMultiLin(DatawithTime,netQujianChicang,legent1);
saveas(fig,‘F:/2017fof/市场和净值/区间持仓策略.jpg’);
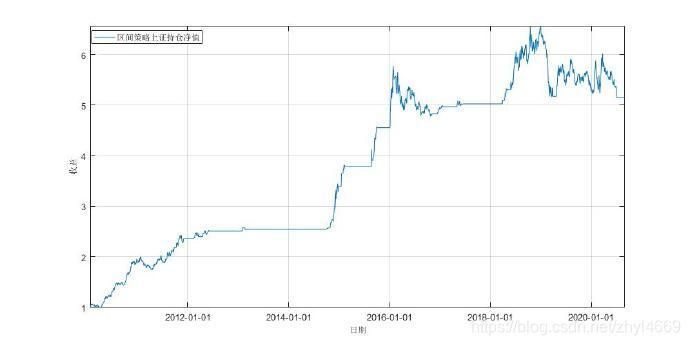
四、上一个持仓得到的累计净值曲线计算。
基于上证指数为标的进行的区间择时买卖点的策略逻辑
基于上证指数为标的进行的区间择时买卖点的策略逻辑
无论如何,就这个策略哈哈 至此发现,需要开始进行区间的选择,程序实现才行。然后 在价格持仓净值吧。
年度收益 分开看
基于上证指数为标的进行的区间择时买卖点的策略逻辑
基于上证指数为标的进行的区间择时买卖点的策略逻辑
五、
有时候你不知道你做的是什么事,你为啥做事,你该不该做事,那就静下心来做事吧。没主见的人善于等待嘛
可验证数据和策略逻辑统计(第三部分之上)结果源数据,打包下
https://474b.com/file/24889670-459827570 需要数据验证的参考
这篇关于基于上证指数为标的进行的区间择时买卖点的策略逻辑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





