本文主要是介绍CKKS EXPLAINED: PART 1, VANILLA ENCODING AND DECODING,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CKKS EXPLAINED: PART 1, VANILLA ENCODING AND DECODING
Introduction
同态加密是一个有前途的领域,它允许在加密数据上进行计算。一篇名为“同态加密是什么”的博文提供了广泛的解释,说明了同态加密的含义以及这一研究领域的重要性。
在本系列文章中,我们将深入研究 Cheon-Kim-Kim-Song (CKKS) 方案,该方案首次在论文《用于近似数算术的同态加密》中进行了讨论。CKKS 允许我们在复数值向量上进行计算(因此也包括实数值)。我们的目标是使用 Python 从头开始实现 CKKS,然后通过使用这些密码学原语,探索如何执行复杂操作,比如线性回归、神经网络等等。
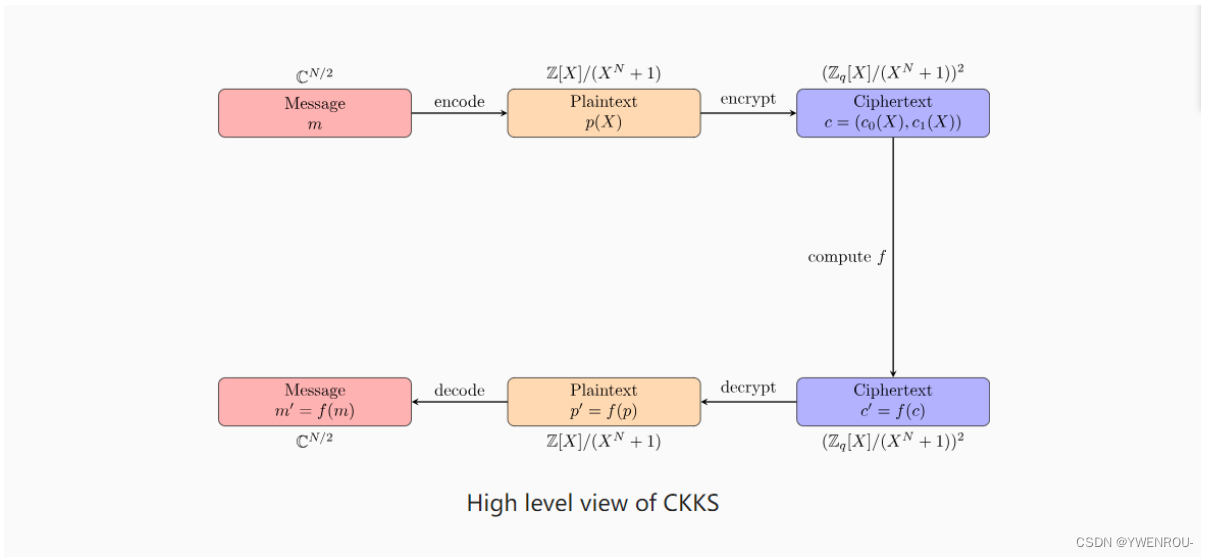
上图提供了 CKKS 的高层视图。我们可以看到,一个消息 m m m,即我们想要进行某些计算的值向量,首先被编码成一个明文多项式 p ( X ) p(X) p(X),然后使用公钥进行加密。
CKKS 使用多项式进行操作,因为与向量上的标准计算相比,它们在安全性和效率之间提供了很好的折衷。
一旦消息 m m m 被加密为 c c c,即一对多项式,CKKS 提供了几种可以在其上执行的操作,例如加法、乘法和旋转。
如果我们用 f f f 表示一个函数,它是同态操作的组合,那么用秘密密钥解密 c ′ = f ( c ) c' = f(c) c′=f(c) 将产生 p ′ = f ( p ) p' = f(p) p′=f(p)。因此,一旦解码,我们将得到 m = f ( m ) m = f(m) m=f(m)。
实现同态加密方案的核心思想是在编码器、解码器、加密器和解密器上具有同态属性。这样,密文上的操作将被正确地解密和解码,并且提供的输出就像直接在明文上进行操作一样。
因此,在本文中,我们将看到如何实现编码器和解码器,而在后续文章中,我们将继续实现加密器和解密器,以构建一个同态加密方案。
相关知识:
循环多项式
在数学中,对于任意正整数 n n n,第 n n n 个循环多项式是满足以下条件的唯一不可约多项式:
- 它具有整数系数;
- 它是多项式 x n − 1 x^n - 1 xn−1 的因式,但不是 x k − 1 x^k - 1 xk−1 的因式,其中 k < n k < n k<n;
- 它的根是所有与 n n n 互质的正整数 k k k 所对应的第 n n n 个原始单位根 e 2 i π k n e^{2i\pi \frac{k}{n}} e2iπnk。
换句话说,第 n n n 个循环多项式可以表示为:
Φ n ( x ) = ∏ 1 ≤ k ≤ n gcd ( k , n ) = 1 ( x − e 2 i π k n ) \Phi_n(x) = \prod_{\substack{1 \leq k \leq n \\ \gcd(k,n)=1}} (x - e^{2i\pi \frac{k}{n}}) Φn(x)=1≤k≤ngcd(k,n)=1∏(x−e2iπnk)
这个多项式也可以定义为具有整数系数的首一多项式,它是有理数域上任意一个原始 n n n 次单位根的最小多项式。一个重要的关系是:
∏ d ∣ n Φ d ( x ) = x n − 1 \prod_{d|n} \Phi_d(x) = x^n - 1 d∣n∏Φd(x)=xn−1
这表明如果 x x x 是 x n − 1 x^n - 1 xn−1 的根,那么它就是某个能整除 n n n 的 d d d 次原始单位根的根。
这些公式描述了循环多项式的形式,具体如下:
- 如果 n n n 是一个素数,循环多项式 Φ n ( x ) \Phi_n(x) Φn(x) 为:
Φ n ( x ) = 1 + x + x 2 + … + x n − 1 = ∑ k = 0 n − 1 x k \Phi_n(x) = 1 + x + x^2 + \ldots + x^{n-1} = \sum_{k=0}^{n-1} x^k Φn(x)=1+x+x2+…+xn−1=k=0∑n−1xk
这里的 x n − 1 x^{n-1} xn−1 表示最高次幂是 n − 1 n-1 n−1 的项,系数 1 , x , x 2 , … , x n − 1 1, x, x^2, \ldots, x^{n-1} 1,x,x2,…,xn−1 都是整数。
- 如果 n = 2 p n = 2p n=2p,其中 p p p 是一个奇素数,循环多项式 Φ 2 p ( x ) \Phi_{2p}(x) Φ2p(x) 为:
Φ 2 p ( x ) = 1 − x + x 2 − … + ( − 1 ) p − 1 x p − 1 = ∑ k = 0 p − 1 ( − x ) k \Phi_{2p}(x) = 1 - x + x^2 - \ldots + (-1)^{p-1}x^{p-1} = \sum_{k=0}^{p-1} (-x)^k Φ2p(x)=1−x+x2−…+(−1)p−1xp−1=k=0∑p−1(−x)k
在这个公式中,奇数次幂的系数是负的,这是为了满足循环多项式的定义,其中的系数必须交替正负。
规范嵌入(Canonical embedding)
规范嵌入(Canonical embedding)是用于编码和解码的一种技术,常用于将向量映射到多项式空间中。规范嵌入具有很好的性质,其中一个重要性质是它们是同构的(isomorphism),即向量空间与多项式空间之间存在一一映射,保持了向量和多项式之间的关系。
具体来说,规范嵌入确保了向量空间中的每个向量都对应唯一的多项式,反之亦然。这意味着,通过规范嵌入,我们可以将向量空间中的运算映射到多项式空间中,从而实现对编码和解码过程的管理和控制。
同构性质使得向量和多项式之间的转换更加灵活和高效,这在许多应用中都是非常有用的,尤其是在使用多项式表示数据时,比如在密码学中的同态加密方案中。
让我们以一个简单的例子来说明规范嵌入的概念。
假设我们有一个 n n n 维的向量空间,其中的向量可以表示为 ( a 1 , a 2 , … , a n ) (a_1, a_2, \ldots, a_n) (a1,a2,…,an),其中 a i a_i ai 是向量的第 i i i 个分量。
现在,我们希望将这个向量空间中的向量映射到一个 n n n 次多项式空间中。我们可以使用规范嵌入来实现这个映射,其中每个向量对应一个唯一的多项式。
例如,对于一个二维向量空间 ( x , y ) (x, y) (x,y),我们可以将其映射到一个二次多项式空间中。规范嵌入可以将向量 ( x , y ) (x, y) (x,y) 映射为多项式 a x + b y ax + by ax+by,其中 a a a 和 b b b 是我们选择的系数。
同样地,我们可以将多项式 a x + b y ax + by ax+by 解码为向量 ( a , b ) (a, b) (a,b)。这样,我们就建立了向量空间和多项式空间之间的一一对应关系,这就是规范嵌入的作用。
在实际应用中,规范嵌入可以用于将数据转换为多项式形式,从而应用于密码学、信号处理和编码理论等领域中。
范德蒙矩阵(Vandermonde matrices)
范德蒙矩阵(Vandermonde matrices)是一种特殊的矩阵,通常用于将一组数据映射到多项式空间中,以及在多项式插值和拟合问题中的求解中。在文中提到的背景下,范德蒙矩阵被用于实现规范嵌入的逆运算。
规范嵌入将向量映射到多项式空间中,而逆运算则将多项式映射回向量空间。使用范德蒙矩阵可以实现逆运算。具体来说,如果我们有一个 n n n 维的向量空间,我们可以通过规范嵌入将其映射到一个 n n n 次多项式空间中,形式如下:
f ( x ) = a 0 + a 1 x + a 2 x 2 + … + a n − 1 x n − 1 f(x) = a_0 + a_1 x + a_2 x^2 + \ldots + a_{n-1} x^{n-1} f(x)=a0+a1x+a2x2+…+an−1xn−1
其中 a 0 , a 1 , … , a n − 1 a_0, a_1, \ldots, a_{n-1} a0,a1,…,an−1 是多项式的系数。
如果我们想要从多项式空间映射回向量空间,我们可以利用范德蒙矩阵的逆来实现。范德蒙矩阵的逆矩阵可以将多项式的系数转换回原始的向量形式。
让我们以一个简单的例子来说明范德蒙矩阵的使用,特别是在规范嵌入的逆运算中。
考虑一个三维的向量空间 ( a , b , c ) (a, b, c) (a,b,c),我们希望将其映射到一个三次多项式 f ( x ) = a x 2 + b x + c f(x) = ax^2 + bx + c f(x)=ax2+bx+c。这是一个规范嵌入的过程。
现在,如果我们有一个包含不同 x x x 值的数据集,例如 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3,我们可以构建范德蒙矩阵。对于 n n n 次多项式,范德蒙矩阵的第 i i i 行第 j j j 列的元素是 x i j − 1 x_i^{j-1} xij−1。
范德蒙矩阵 V V V 如下:
V = [ 1 x 1 x 1 2 1 x 2 x 2 2 1 x 3 x 3 2 ] V = \begin{bmatrix} 1 & x_1 & x_1^2 \\ 1 & x_2 & x_2^2 \\ 1 & x_3 & x_3^2 \\ \end{bmatrix} V= 111x1x2x3x12x22x32
然后,我们可以将向量 ( a , b , c ) (a, b, c) (a,b,c) 通过矩阵乘法 V × a V \times \mathbf{a} V×a 映射到多项式空间,其中 a \mathbf{a} a 是包含系数 a , b , c a, b, c a,b,c 的列向量。
如果我们现在有多项式 f ( x ) = a x 2 + b x + c f(x) = ax^2 + bx + c f(x)=ax2+bx+c 的系数 a , b , c a, b, c a,b,c,我们可以通过范德蒙矩阵的逆 V − 1 V^{-1} V−1 进行逆运算,得到原始向量:
a = V − 1 × [ f ( x 1 ) f ( x 2 ) f ( x 3 ) ] \mathbf{a} = V^{-1} \times \begin{bmatrix} f(x_1) \\ f(x_2) \\ f(x_3) \\ \end{bmatrix} a=V−1× f(x1)f(x2)f(x3)
这个例子展示了范德蒙矩阵如何在规范嵌入的逆运算中发挥作用,通过逆运算,我们可以从多项式的系数还原回原始的向量。
因此,范德蒙矩阵在规范嵌入的逆运算中具有重要作用,它允许我们从多项式空间返回到原始的向量空间。
Encoding in CKKS
CKKS利用整数多项式环的丰富结构来构建其明文空间和密文空间。然而,数据更常见地以向量的形式出现,而不是多项式的形式。
因此,有必要将输入 z ∈ C N / 2 z \in \mathbb{C}^{N/2} z∈CN/2 编码成一个多项式 m ( X ) ∈ Z [ X ] / ( X N + 1 ) m(X) \in \mathbb{Z}[X]/(X^N+1) m(X)∈Z[X]/(XN+1)。
我们将我们的多项式的度数模数记为 N N N,它将是2的幂。我们用 Φ M ( X ) = X N + 1 \Phi_M(X) = X^N+1 ΦM(X)=XN+1 表示第 m m m 个循环多项式(注意这里 M = 2 N M=2N M=2N)。明文空间将是多项式环 R = Z [ X ] / ( X N + 1 ) R = \mathbb{Z}[X]/(X^N+1) R=Z[X]/(XN+1)。让我们用 ξ M \xi_M ξM 表示第 M M M 个单位根: ξ M = e 2 i π / M \xi_M = e^{2i\pi/M} ξM=e2iπ/M。
为了理解如何将向量编码为多项式以及多项式上的计算如何反映在底层向量中,我们首先通过一个简单的示例来实验,其中我们简单地将一个向量 z ∈ C N z \in \mathbb{C}^N z∈CN 编码为一个多项式 m ( X ) ∈ C [ X ] / ( X N + 1 ) m(X) \in \mathbb{C}[X]/(X^N+1) m(X)∈C[X]/(XN+1)。然后,我们将讨论CKKS的实际编码,它将一个向量 z ∈ C N / 2 z \in \mathbb{C}^{N/2} z∈CN/2 编码成一个多项式 m ( X ) ∈ Z [ X ] / ( X N + 1 ) m(X) \in \mathbb{Z}[X]/(X^N+1) m(X)∈Z[X]/(XN+1)。
Vanilla Encoding
在这里,我们将讨论简单情况下将 z ∈ C N z \in \mathbb{C}^N z∈CN编码成多项式 m ( X ) ∈ C [ X ] / ( X N + 1 ) m(X) \in \mathbb{C}[X]/(X^N+1) m(X)∈C[X]/(XN+1)。
为此,我们将使用规范嵌入 σ : C [ X ] / ( X N + 1 ) → C N \sigma: \mathbb{C}[X]/(X^N+1) \rightarrow \mathbb{C}^N σ:C[X]/(XN+1)→CN,它解码和编码我们的向量。
这个想法很简单:要将多项式 m ( X ) m(X) m(X)解码为向量 z z z,我们在某些值上评估多项式,这些值将是循环多项式 Φ M ( X ) = X N + 1 \Phi_M(X) = X^N+1 ΦM(X)=XN+1的根。这些 N N N个根是: ξ , ξ 3 , … , ξ 2 N − 1 \xi, \xi^3, \ldots, \xi^{2N-1} ξ,ξ3,…,ξ2N−1。
因此,要解码一个多项式 m ( X ) m(X) m(X),我们定义 σ ( m ) = ( m ( ξ ) , m ( ξ 3 ) , … , m ( ξ 2 N − 1 ) ) ∈ C N \sigma(m) = (m(\xi), m(\xi^3), \ldots, m(\xi^{2N-1})) \in \mathbb{C}^N σ(m)=(m(ξ),m(ξ3),…,m(ξ2N−1))∈CN。注意, σ \sigma σ定义了一个同构,这意味着它是一个双射同态,因此任何向量将被唯一编码为其相应的多项式,反之亦然。
棘手的部分是将一个向量 z ∈ C N z \in \mathbb{C}^N z∈CN编码成相应的多项式,这意味着计算逆变换 σ − 1 \sigma^{-1} σ−1。因此,问题就是找到一个多项式 m ( X ) = ∑ i = 0 N − 1 α i X i ∈ C [ X ] / ( X N + 1 ) m(X) = \sum_{i=0}^{N-1} \alpha_i X^i \in \mathbb{C}[X]/(X^N+1) m(X)=∑i=0N−1αiXi∈C[X]/(XN+1),给定一个向量 z ∈ C N z \in \mathbb{C}^N z∈CN,使得 σ ( m ) = ( m ( ξ ) , m ( ξ 3 ) , … , m ( ξ 2 N − 1 ) ) = ( z 1 , … , z N ) \sigma(m) = (m(\xi), m(\xi^3), \ldots, m(\xi^{2N-1})) = (z_1, \ldots, z_N) σ(m)=(m(ξ),m(ξ3),…,m(ξ2N−1))=(z1,…,zN)。
进一步追求这个线索,我们得到以下方程组:
∑ j = 0 N − 1 α j ( ξ 2 i − 1 ) j = z i , i = 1 , … , N . \sum_{j=0}^{N-1} \alpha_j (\xi^{2i-1})^j = z_i, \quad i=1, \ldots, N. j=0∑N−1αj(ξ2i−1)j=zi,i=1,…,N.
这可以看作是一个线性方程:
A α = z A \alpha = z Aα=z
其中 A A A是 N N N个根 ( ξ 2 i − 1 ) i = 1 , … , N (\xi^{2i-1})_{i=1,\ldots,N} (ξ2i−1)i=1,…,N的范德蒙德矩阵, α \alpha α是多项式系数的向量, z z z是我们想要编码的向量。
因此我们有: α = A − 1 z \alpha = A^{-1} z α=A−1z,并且 σ − 1 ( z ) = ∑ i = 0 N − 1 α i X i ∈ C [ X ] / ( X N + 1 ) \sigma^{-1}(z) = \sum_{i=0}^{N-1} \alpha_i X^i \in \mathbb{C}[X]/(X^N+1) σ−1(z)=∑i=0N−1αiXi∈C[X]/(XN+1)。
Example
让我们现在看一个例子,以更好地理解我们到目前为止所讨论的内容。
设 M = 8 M=8 M=8, N = M / 2 = 4 N=M/2=4 N=M/2=4, Φ M ( X ) = X 4 + 1 \Phi_M(X)=X^4+1 ΦM(X)=X4+1, ω = e 2 i π / 8 = e i π / 4 \omega=e^{2i\pi/8}=e^{i\pi/4} ω=e2iπ/8=eiπ/4。
我们的目标是编码以下向量: [ 1 , 2 , 3 , 4 ] [1,2,3,4] [1,2,3,4] 和 [ − 1 , − 2 , − 3 , − 4 ] [-1,-2,-3,-4] [−1,−2,−3,−4],对它们进行解码,然后对它们的多项式进行加法和乘法,并最终解码结果。
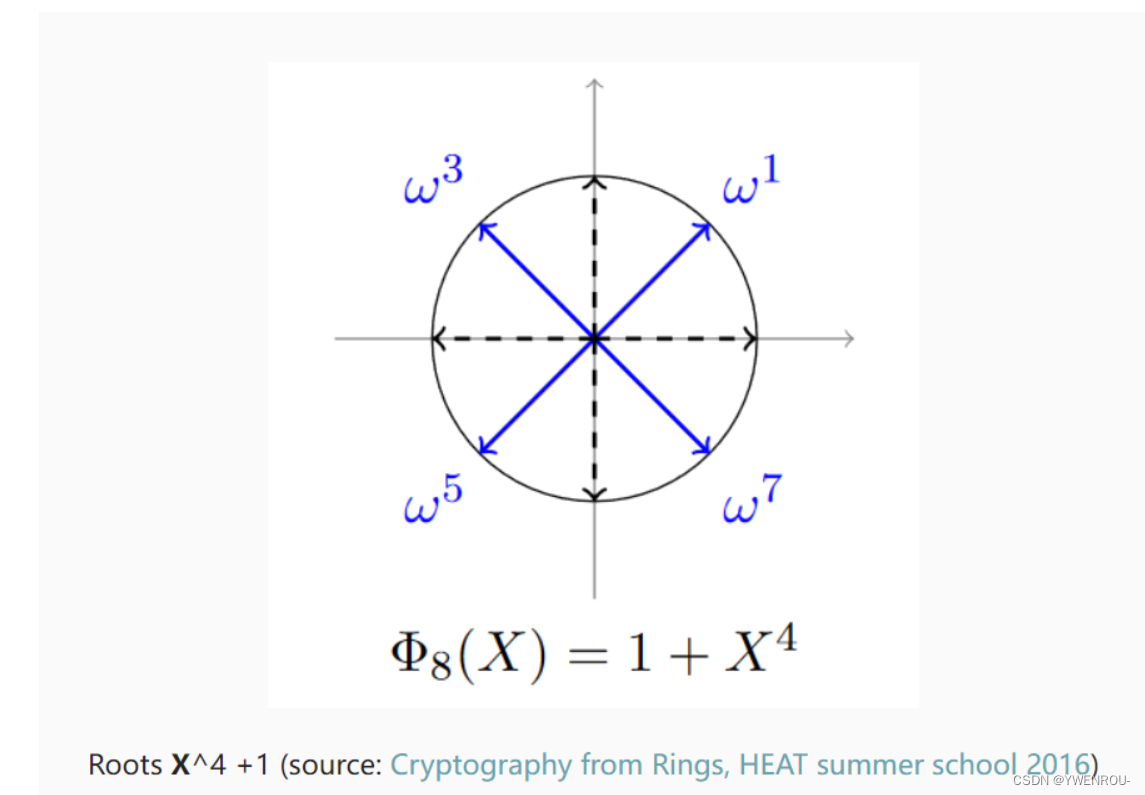
正如我们所看到的,在解码多项式时,我们只需要在M次单位根的幂上对其进行评估。在这里,我们选择 ξ M = ω = e i π / 4 ξ_M = ω = e^{i\pi/4} ξM=ω=eiπ/4。
一旦我们有了 ξ ξ ξ 和 M M M,我们就可以定义 σ σ σ 及其逆 σ − 1 σ^{-1} σ−1,分别用于解码和编码。
这篇关于CKKS EXPLAINED: PART 1, VANILLA ENCODING AND DECODING的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






