本文主要是介绍(OSLOM)Finding statistically significant communities in networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- Statistical significance of clusters
- Single cluster analysis
- Network analysis
- OSLOM
论文地址
作者提出OSLOM (Order Statistics Local Optimization Method),是第一种能够检测出包括有向、有权、重叠社区、层次结构和动态社区的网络中的社区的方法。该方法基于适应度函数的局部优化,该适应度函数表示社区相对于随机波动的统计意义,该适应度函数使用极值和order(顺序)统计工具估计的。是第一种基于统计显著性在网络中找到社区的方法。
主要问题:
现在的大多数网络不能处理好很多重要的网络特征与特殊结构,比如不容易(不能)扩展到有向图,有权图,重叠社区,层次结构,动态网络结构等等。
区分社区和伪社区的方法也非常重要。社区的存在表示一些顶点倾向于相互连接,但是,如果所有的顶点的连接概率都是相同的,就像在随机图中一样,那么就应该不存在社区。在这种情况下,节点群中的边的聚集只是随机波动的结果,它们不能代表潜在的非平凡结构。许多算法不能看到这种差异,在随机图中还是找到了社区,尽管他们没有意义。
本文提出的OSLOM算法是一种基于全局空模型定义的局部优化社区统计显著性的方法。
Statistical significance of clusters
significance:将其定义为在一个随机空模型中,即在没有社区结构的图中找到社区的概率。(此社区在随机化的网络中出现的可能性)
假设C是configuration model生成的一个子图,每个顶点保持在G上的度。假设子图的内部度是固定的,如果网络中所有其他边都是随机绘制的。那么i在c中有 k i i n k_i^{in} kiin个邻居的概率(也即是i与C相连的边的数目):
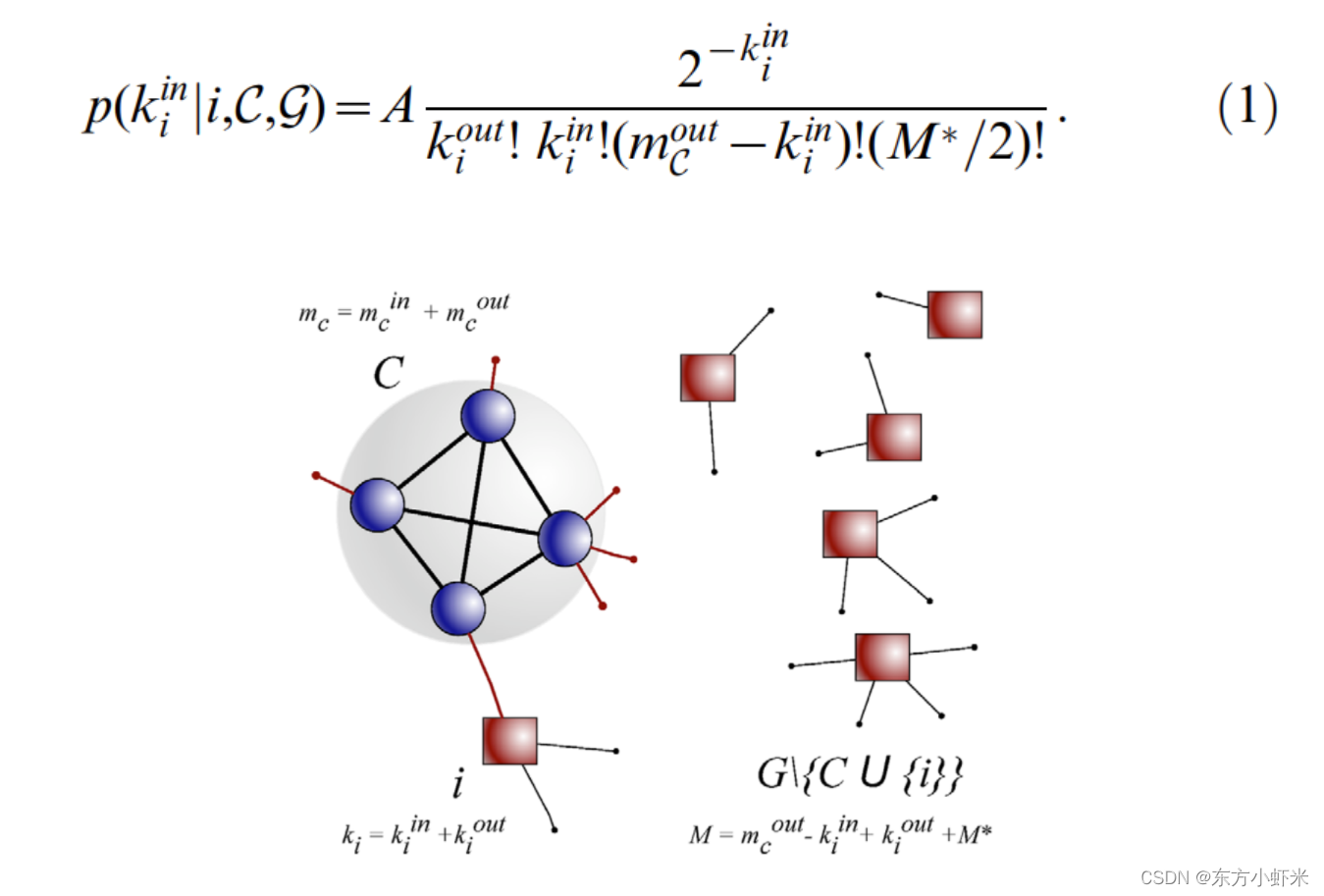
等式例举了i和c之间有边的所有可能构型。
G为图,C为子图,i为节点i,ki为节点i的出度和入度。子图的度和为 m c m_c mc,除去节点i和子图c外的部分的度和为M。M*代表内部度。都为固定的。
这个方程列举了i和c之间有kin连接的网络可能的结构,公式的阶乘表示了固定参数后的结构的多重性。
A为标准化因子,由不依赖于 k i i n k_i^{in} kiin的项组成,并确保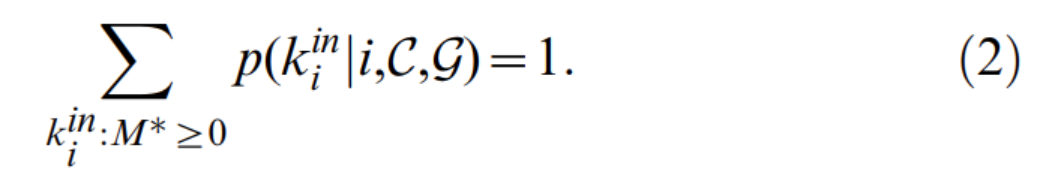
公式1的概率提供了一种工具,可以根据C之外的节点与C子图的拓扑关系的可能性对C之外顶点进行排序。如果顶点i与子图的顶点共享的边比空模型的预期的要多,我们就可以考虑在C中包含i,因为i和C之间的关系‘’‘出乎意料的强’。
为了排序,计算节点内部连接数等于或大于 k i i n k_i^{in} kiin(大于 k i i n k_i^{in} kiin的说明拓扑关系强)的累计概率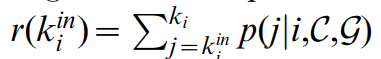
由于顶点的度是一个离散变量,累积分布对于ki的每个值都有一个特定的stepwise profile (逐步分布?)。为了便于比较不同度的节点,实现了一种Bootstrap策略,从区间 [ r ( k i i n ) , r ( k i i n + 1 ) ] [r(k_i^{in}),r(k_i^{in} + 1)] [r(kiin),r(kiin+1)]为每个节点i随机抽取一个r,作为ri值给每个顶点i。
变量r包含了关于每个节点与子图C的拓扑关系的可能性的信息,并且有一个特别的特征:对于空模型节点,它是分布在0到1之间的均匀的随机变量。因此,计算其order statistic distributions(顺序统计分布)是一项相对容易的任务。在C的外部节点中,第一个候选点是r值最小的顶点,记为r1.空模型中r1的累积分布:(在空模型中随机产生r1的概率)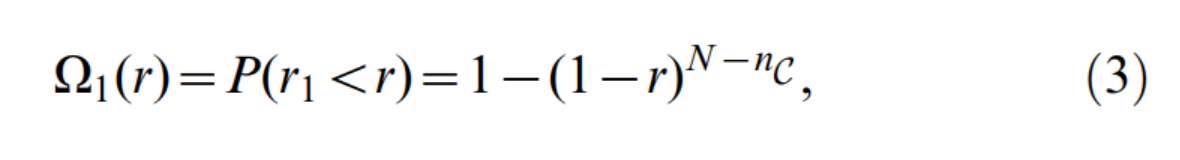
式中,nC为c中的顶点个数。一般情况下,设rq为变量r的排名为q的值(按变量r的递增顺序排列),其累积分布为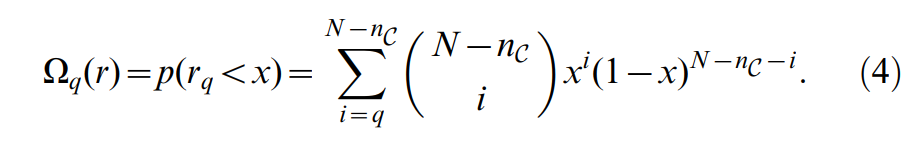
使用顺序统计的原因是我们假设聚类方法倾向于在每个社区中包含那些与社区的节点连接最紧密的节点。由于相关性(社区中的节点往往是连接的),我们无法计算得到社区内部连接的统计信息,但我们可以安全的对外部节点进行计算,不同的 Ω q \Omega_q Ωq值告诉我们一个组的外部节点与空模型中预期的统计数据兼容的程度(小说明不符合空模型,可能存在社区)。为了计算整个组,我们在c的所有邻居中定义 C m = m i n { Ω q ( r q ) } C_m = min\{\Omega_q(r_q)\} Cm=min{Ωq(rq)}, 其中 r q r_q rq是r变量对应的排序值。由于 C m C_m Cm的分布只取决于 N − n C N-n_C N−nC, 所以他可以很容易的用数字表示。累计分布记为 P ( c m < x ) = ϕ ( x , N − n C ) P(c_m<x) = \phi(x,N -n_C) P(cm<x)=ϕ(x,N−nC).我们称 ϕ ( x , N − n C ) \phi(x,N -n_C) ϕ(x,N−nC)为社区c的分数。OSLOM的聚类方法更倾向于将与社区联系更多的点包含进社区.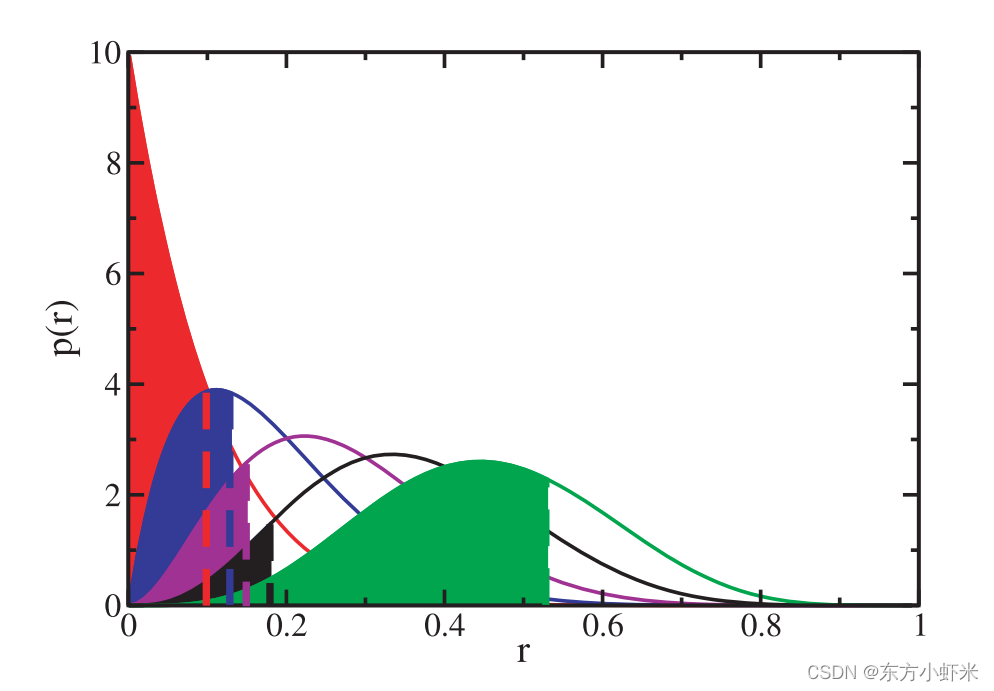
一个给定的子图C外的顶点的分数r的概率分布如上图。分数rq是第q小分数的外部顶点。在这种情况下,有10个外部顶点。在图中,从左到右画出p(r1), p(r2), p(r3), p(r4), p(r5)。例如,阴影区域显示了一些r值的累积概率 Ω q \Omega_q Ωq,这些值对应于实际情况中估计的值。在这种情况下,黑色区域q=4是最不广泛的,所以cm= Ω 4 \Omega_4 Ω4。如果 ϕ ( c m ) < P \phi(c_m)<P ϕ(cm)<P,分数为r1、r2、r3和r4的顶点将被添加到C中。
Single cluster analysis
现在已经引入了评价聚类统计significance(显著性)的分数,下一步是通过将网络划分为适当的社区来优化整个网络的分数。首先来描述单个社区分数的优化,然后将其扩展到整个网络。首先需要给该方法一个确定的tolerance(公差),称为P。该参数确定给定的分数在何时被认为是重要的。过程包括两个阶段:
- 我们探索向子图C添加外部节点的可能性。
- 删除C中不重要的节点
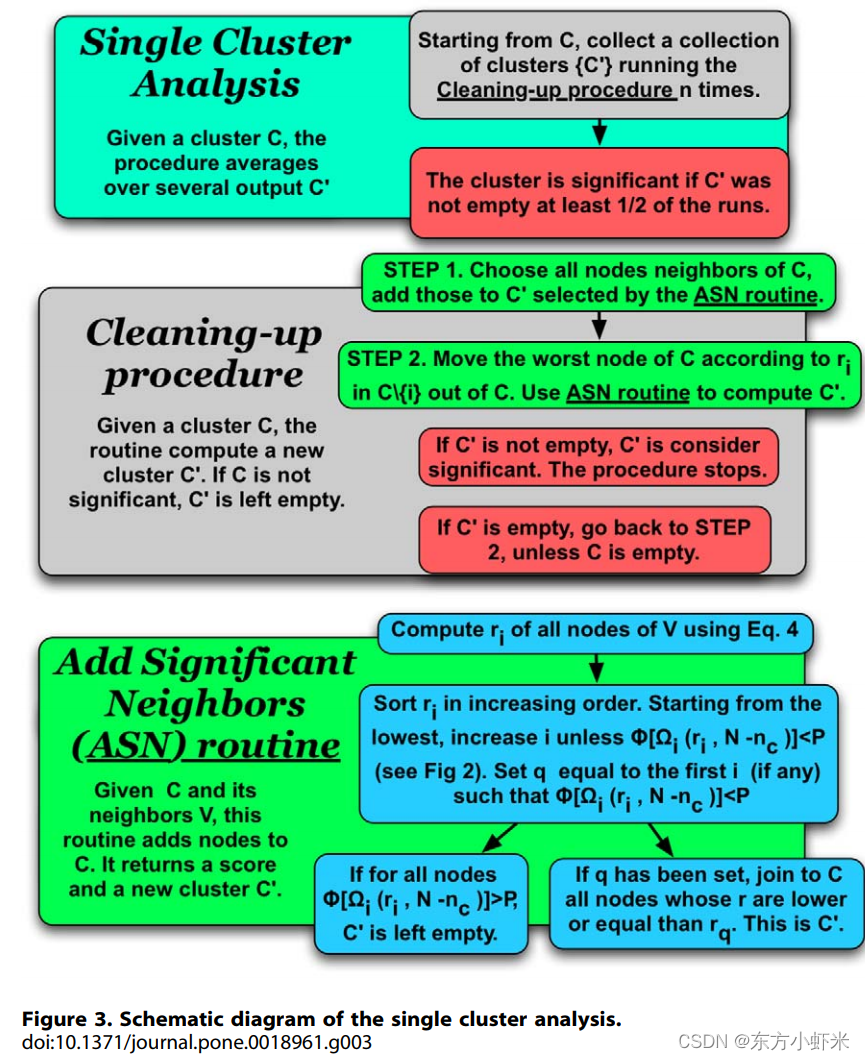
- 对于C外的与C至少有一条边的每个节点i,计算出r。然后根据公式计算出r最小的顶点的 Ω 1 ( r ) \Omega_1(r) Ω1(r).,如果 ϕ ( Ω 1 ( r ) , N − n C ) < P \phi(\Omega_1(r),N -n_C)<P ϕ(Ω1(r),N−nC)<P我们就将相应的顶点添加到子图中,新子图称为C’。如果大于P,我们就检查第二个最佳顶点,第三个最佳顶点,以此类推。如果最后 有一个顶点,比如说是第q个最佳顶点,使得式子小于P,将所有q个最佳顶点包含到子图C中,得到子图C’。此时,C之外的任何顶点都不配进入社区,因为所有外部顶点都与随机配置模型的统计数据兼容。也可能发生上式不等式<P对任何外部点都不成立,在这种情况下,C’ = C,没有添加新的节点。无论那种方式,都用子图C’进入第二阶段。
- 对于C’中点每个节点i,估计相对于集合C’\{i}的ri值。选择社区中最差的节点w,即ri值最高的节点。为了检查他的重要性significance,我们对子图C’\{i}重复步骤1。如果w被证明是重要的,则保持它在C’中,然后完成对社区的分析。否则,w被移除C’,然后继续搜索C’\{w}中的最差的节点。在某个时刻,我们最终得到了一个集群C,其中的内部顶点都是重要的,程序就结束了。
这两部过程是一种清理C的方法,只有在所有外部顶点与空模型兼容,并且所有内部顶点都不兼容时,才会保持社区。
C之外的顶点可以是好的,C里面的顶点也可以是坏的。 执行上面描述的完整过程非常重要,这可以保证最终的社区相对于当前的空模型非常重要(显著)。
由于累计概率r的计算存在随机成分,所以这个过程是不确定 。因此,所有步骤都要重复几次。聚类分析可以提供一个子图C’,不同于C或者一个空子图。对于每个顶点i,计算 参与频率fi,定义为i属于任何非空C’的次数与导致非空子图的总迭代次数的比值。通常,如果单个社区缝隙在超过50%的迭代中产生了一个非空的子图C’,我们就认为子图C是一个重要集群。最后清理的社区包括哪些fi>0.5的节点。
在最坏的情况下,聚类分析的复杂性随着C的顶点数、C的邻居数、fi的可靠值所需的循环数的增加而增加。通过跟踪每一步外部顶点的顺序(使用合适的数据结构),并仅计算一些比较好的顶点的得分,可以大大改善这种情况。例如,可以只选择那些r<0.1的顶点。我们通过数值验证,改变这个阈值并不会影响结果,但会导致算法更快。
Network analysis
前面的过程处理单个社区c。它找到外部重要的顶点,并将它们包含到c中。它还删除那些统计上不相关的内部顶点。 现在通过引入一种能够分析整个网络的算法来扩展这个过程。起始点是在没有任何信息的情况下随机选取的单个顶点。假设从节点i开始我们的第一个社区为C={i},方法步骤如下:
- 将q个顶点添加到C中,考虑到社区的邻居中最重要的一个。q是从一个分布中取来的,这个分布原则上可以是任意的。作者选择指数为-3的幂律。
- 执行上面单个社区的分析
为了探索网络的不同区域,会从几个顶点开始重复整个过程,这就产生了可能重叠的社区。这种局部优化算法最初是在局部适应度方法实现的。当算法不断的寻找到相似的社区时,他就会停止。理想情况相爱,希望能反复遇到完全相同的社区。但是,随机元素的映入导致不太可能实现,只能发现很多相似的社区。所以我们提出问题:给定一组重要的社区,我们应该保留哪些?
加入我们有两个社区C1,C2以及他们的并集C3.一种解决方法是考虑c3中的顶点子图G3,看C1,C2作为G3的模块是否重要。C1’,C2’是在G3中已清理的集群,如果 ∣ C 1 ′ ⋃ C 2 ′ ∣ > P 2 ⋅ ∣ c 3 ∣ |C_1'\bigcup C_2'|>P_2\cdot |c3| ∣C1′⋃C2′∣>P2⋅∣c3∣,设P2为0.7,那么丢弃C3,否则丢弃C1,C2保持C3。一般来说,我们检查每个社区是否有重要的子模块,方法是在社区给出的子图中寻找模块,并使用上述条件来决定采用哪些模块。这将导致一组显著的最小聚类,根据上述条件,最小意味着它们没有显著的内部聚类结构。根据我们的规则,我们还需要检查这些最小社区的联合是否具有内部社区结构,以决定社区是应该保持分离还是合并。
参数的取值可能会影响OSLOM的结果。显著性水平P的值对于确定OSLOM发现的簇的大小起着重要的作用。一般来说,P值越小,识别的聚类就越大,P值越大,识别的聚类就越小。同样地,控制模块内部结构的参数P2值越大,通常会导致标识大型社区。
OSLOM
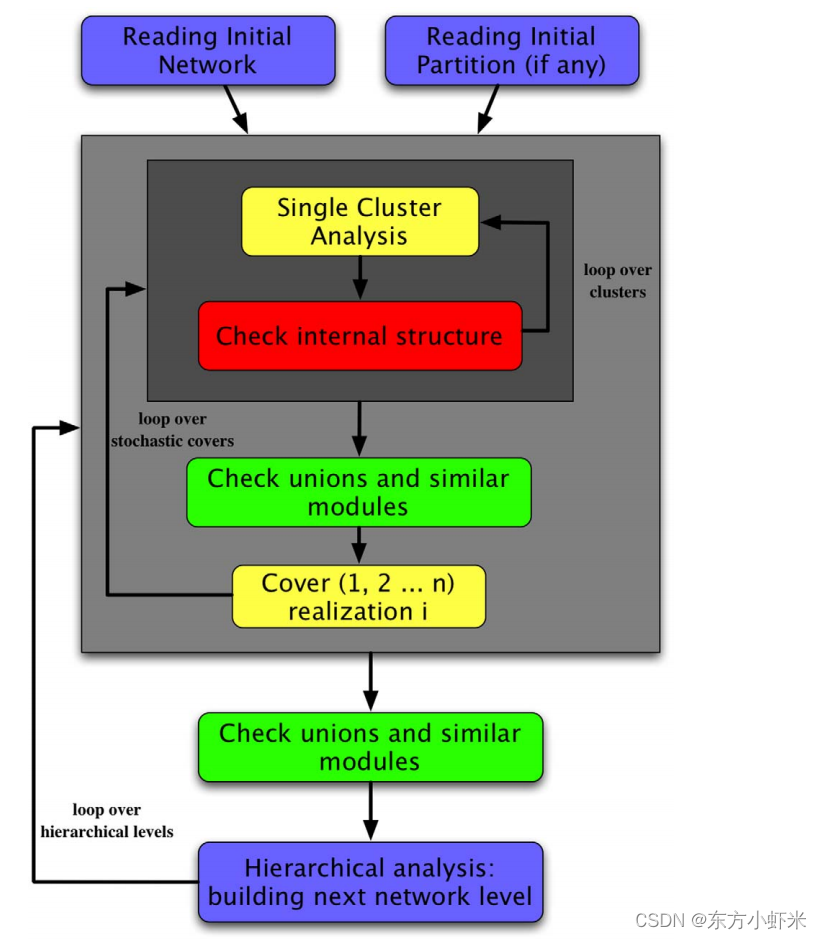
将上面的单个社区的清理以及整个网络的分析组合在一起就形成了OSLOM。它由三个阶段组成:
- 首先,寻找重要(显著)的社区,直到收敛
- 其次,分析产生的社区集合,尝试检测他们可能的内部结构或可能的联合
- 最后,检测集群的层次结构
为了加速该方法,可以从另一个快速算法或先验信息给定的划分开始,这样,第一步就成为了清理给定的社区。
找到最小的重要社区集之后,层次结构的分析包括以下步骤。
构建一个由社区组成的新网络,每个社区变成一个超顶点,如果社区之间相互连接,则存在边,边的权重就是初始社区之间的边数(和louvain凝聚类似)。
这篇关于(OSLOM)Finding statistically significant communities in networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






