本文主要是介绍Bobo老师机器学习笔记-数据归一化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

实现算法:
def normalizate_max_min(X):"""利用最大和最小化方式进行归一化,过一化的数据集中在【0, 1】:param X::return:"""np.asarray(X, dtype=float)if len(X.shape) == 1:normalizate_array = ( X - np.min(X) ) / (np.max(X) - np.min(X))else:normalizate_array = np.zeros(X.shape)for column in range(X.shape[1]):normalizate_array[:, column] = (X[:, column] - np.min(X[:, column])) / (np.max(X[:, column] - np.min(X[:, column])))return normalizate_arraydef standardization(X):"""利用z-scores实现,标准化后的数据大概在【-1.5到1.5】,数据的平均数为0,方差为1:param X: 可以是矩阵:return:"""np.asarray(X, dtype=float)if len(X.shape) == 1:return (X - np.mean(X)) / np.std(X)else:dt = np.zeros(X.shape)for i in range(X.shape[1]):dt[:, i] = (X[:,i] - np.mean(X)) / np.std(X[:, ])return dt
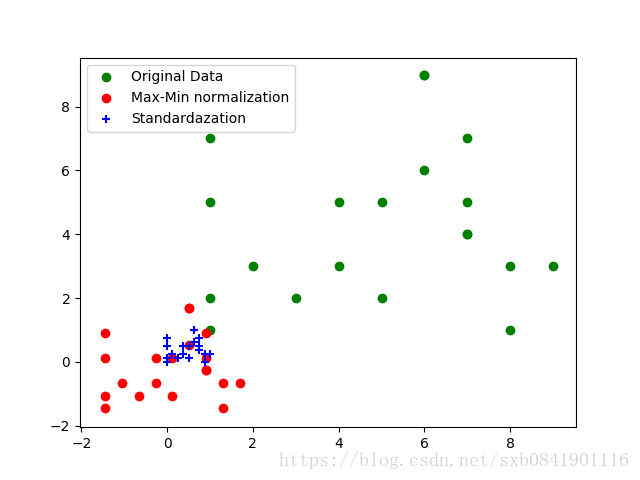
Y = np.random.randint(1, 10, (20, 5))nml_data = normalizate_max_min(Y)std_data = standardization(Y)plt.scatter(Y[:, 0], Y[:, 1], color='green', label='Original Data')plt.scatter(std_data[:, 0], std_data[:, 1], color='red', label="Max-Min normalization")plt.scatter(nml_data[:, 0], nml_data[:, 1], color='blue', marker='+', label="Standardazation")plt.legend()plt.show()把测试数据进行图形展示:
Sklearn中实现可以详细可以看下面链接:
http://cwiki.apachecn.org/pages/viewpage.action?pageId=10814134
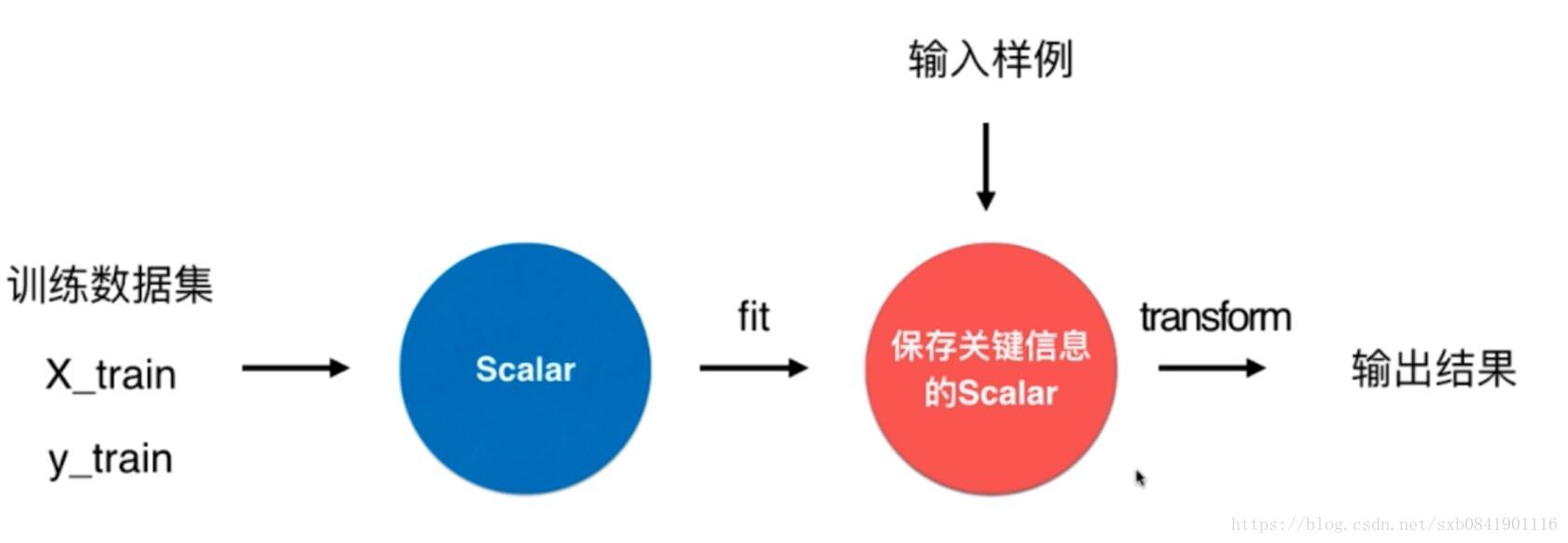
主要有一个模块交preprocessing,里面有实现各种scaler。
比如下面两个例子:
from sklearn.preprocessing import MinMaxScaler, StandardScaler, scalemax_min_scaler = MinMaxScaler()x_train_data = max_min_scaler.fit_transform(Y)print(x_train_data)standard_scaler = StandardScaler()x_train_data = standard_scaler.fit_transform(Y)print(x_train_data)用KNN算法测试:
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifieriris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target)standardscaler = StandardScaler()
standardscaler.fit(X_train)X_train_stanard = standardscaler.transform(X_train)
X_test_standard = standardscaler.transform(X_test)knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train_stanard, y_train)knn_clf.predict(X_test_standard)
print(knn_clf.score(X_test_standard, y_test))
这篇关于Bobo老师机器学习笔记-数据归一化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




