本文主要是介绍Mamba与MoE架构强强联合,Mamba-MoE高效提升LLM计算效率和可扩展性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文题目: MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
论文链接: https://arxiv.org/abs/2401.04081
代码仓库: GitHub - llm-random/llm-random
作为大型语言模型(LLM)基础架构的后起之秀,状态空间模型(State Space Models,SSMs)在序列数据建模领域中已取得了惊人的发展。其中Mamba模型改进了传统的SSM,其通过输入依赖的方式来调整SSM中的参数,允许模型自适应的根据输入数据选择性的传输或遗忘信息,来提高模型在密集型数据上的计算效率。与此同时,Mixture of Experts(MoE)框架也显着改进了基于Transformer的LLM,如何设计更高效的MoE混合策略也成为了LLM研究领域中的潮流方向。
本文介绍一篇来自IDEAS NCBR和华沙大学合作完成的文章,本文作者探索了如何将SSM与MoE结合起来,提出了一种名为MoE-Mamba的框架,MoE-Mamba继承了SSM序列模型的递归计算特性,在推理速度方面相比传统Transformer具有天然优势,同时预测精度优于 Mamba 和 Transformer-MoE。特别的是,MoE-Mamba可以在减少训练steps的情况下达到与普通 Mamba 相同的性能。
01. 引言
SSMs模型相比Transformer具有很多优势,例如可并行训练、推理时的线性时间复杂度以及在长上下文任务上的依赖捕获能力。特别是近期提出的Mamba模型[1],基于选择性的SSM和硬件感知设计在多种语言理解任务上取得了优异的结果,被学术界广泛认为是下一个替代注意力Transformer结构的有力竞争者。Mamba对GPU显存的占用不依赖于上下文长度,因为其反向传播所需的中间状态不会被保存,而是在反向传播期间重新计算,强调了状态压缩的重要性。此外,专家混合模型MoE[2]被证明可以有效扩展和提升Transformer模型的性能,其可以大幅增加模型的参数数量,而不会对模型推理和训练所需的 FLOP 产生太大影响,例如近期开源的Mixtral8×7B [3],性能与LLaMa-2 70B相当,但是推理计算量仅为后者的1/6。
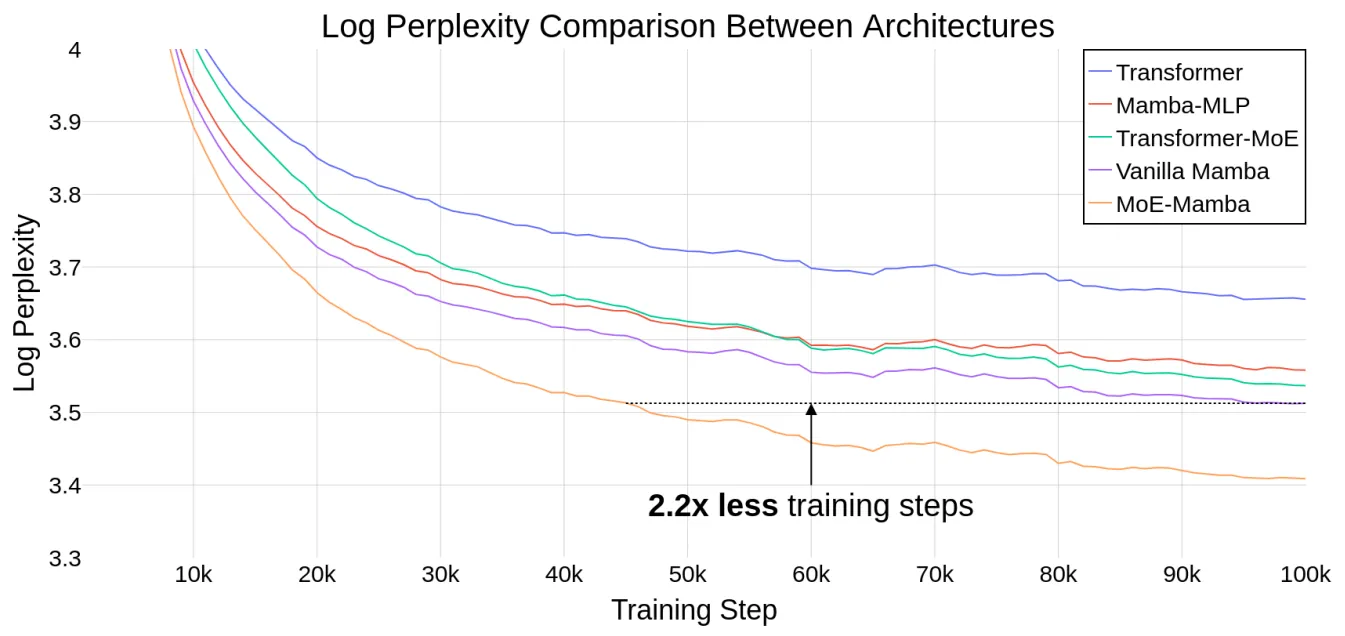
本文引入了一种将Mamba与MoE层相结合的模型MoE-Mamba,MoE-Mamba实现了a+b>c的效果,上图展示了MoE-Mamba与其他baseline方法的性能对比效果,可以看到,MoE-Mamba可以在普通Mamba的基础上实现对模型训练步骤缩减的效果。如上图黑色虚线所示,MoE-Mamba在减少2.2倍训练steps的情况下达到了与普通Mamba相同的性能。后续的其他实验也表明,MoE-Mamba拥有大规模扩展模型参数规模的潜力。
02. 本文方法
尽管 Mamba 的主要底层机制与 Transformer 中使用的注意力机制有很大不同,但 Mamba 仍然保留了 Transformer 模型的层次结构(即块叠加)。例如包含一层或多层的相同块依次堆叠,每一层的输出会被汇聚到残差信息流中再送入到下一个块中,残差流的最终状态随后被用于预测语言建模任务中的下一个token。下图展示了这些架构的细节对比,从左到右分别是vanilla Transformer、MoE-Transformer、Mamba、MoE-Mamba。
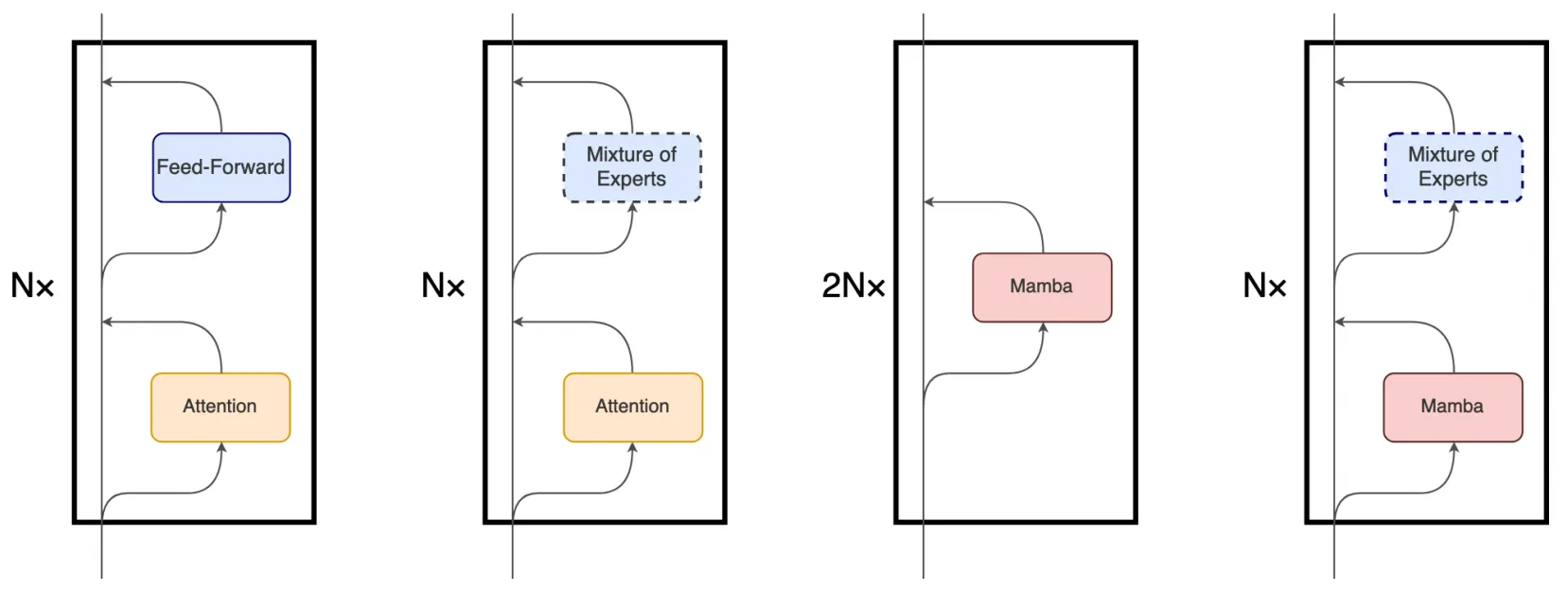
本文提出的MoE-Mamba充分利用了前两种架构的兼容性,例如,在原有Mamba结构的基础上仿照MoE-Transformer将两个mamba块中的其中一个替换成一个可选择的MoE块。这种将mamba层与MoE交错设置的模式可以有效地将序列的整个上下文集成到mamba块的内部表示中,从而将其与MoE层的条件处理分开。
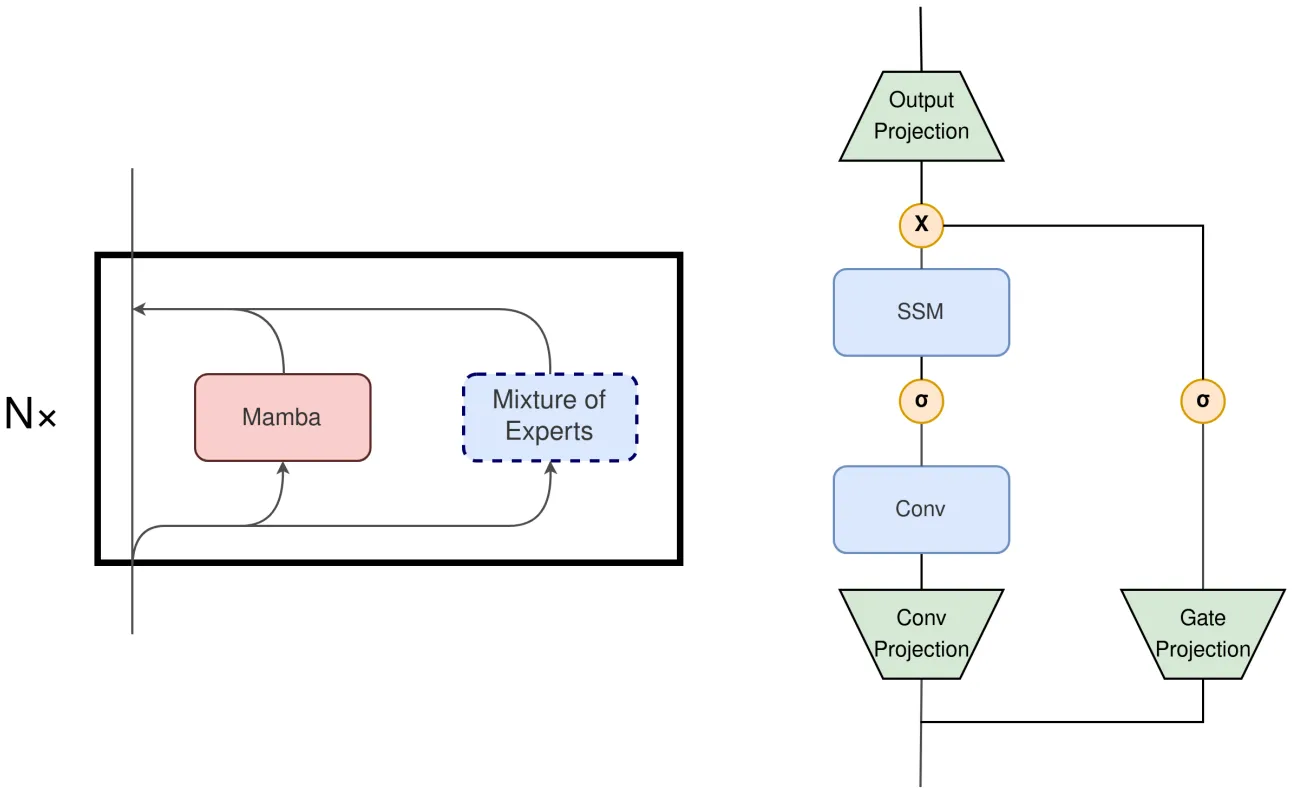
此外,本文作者认为如果将Mamba块和MoE块在局部层的范围内进行并行执行也是一个非常有前景的改进方向,如上图左侧展示了一种并行的Mamba+MoE 架构,右侧展示了Mamba Block的构成。如果将Mamba Block中的输出投影也替换为MoE,模型可以选择更少的模块来匹配当前输入计算的需要,也能实现与原始Mamba架构相当的效果。当然,也可以进一步将MoE替换Conv Projection层来进一步减少计算量。
03. 实验效果
在本文的实验部分,作者比较了5种不同的设置:vanilla Transformer、Mamba、Mamba-MLP、MoE 和 MoE-Mamba。为了保证 Mamba 和本文MoE-Mamba模型中每个token的活动参数数量大致相同,作者将每个MoE前馈层的参数量进行了缩减。不包括嵌入层和非嵌入层,所有模型的每个 token 大约需要访问 26M 个参数,训练数据集使用C4,整体的训练量为大约6.5B个token和10万个训练steps。
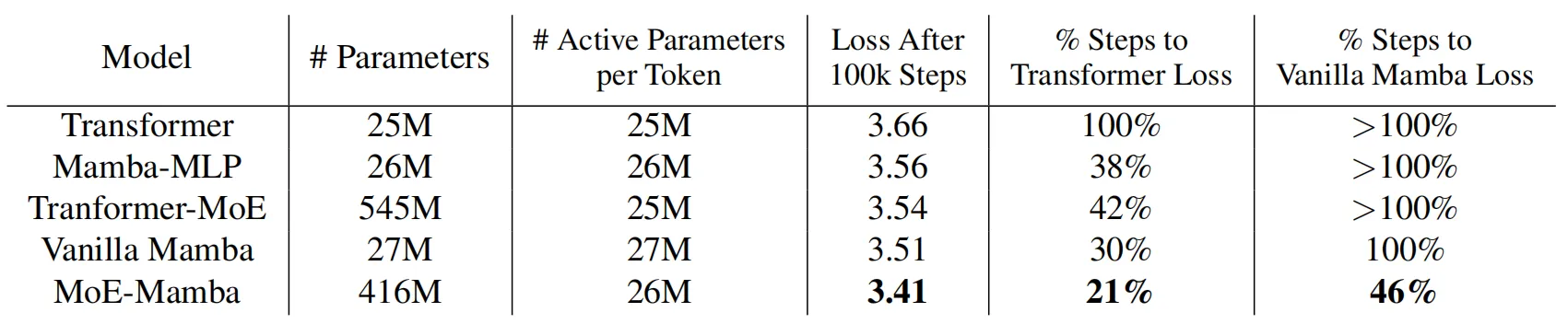
上表展示了上述几种对比模型的训练效果,可以看到,MoE-Mamba 比普通 Mamba 模型有了显着的改进。值得注意的是,MoE-Mamba 只需 46% 的训练steps即可达到与 vanilla Mamba 相同的性能。
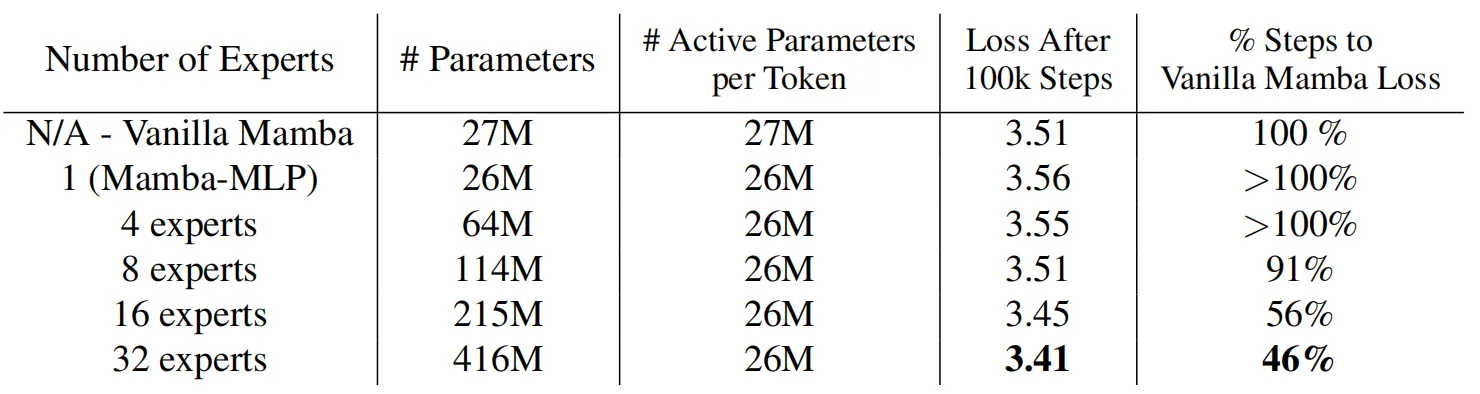
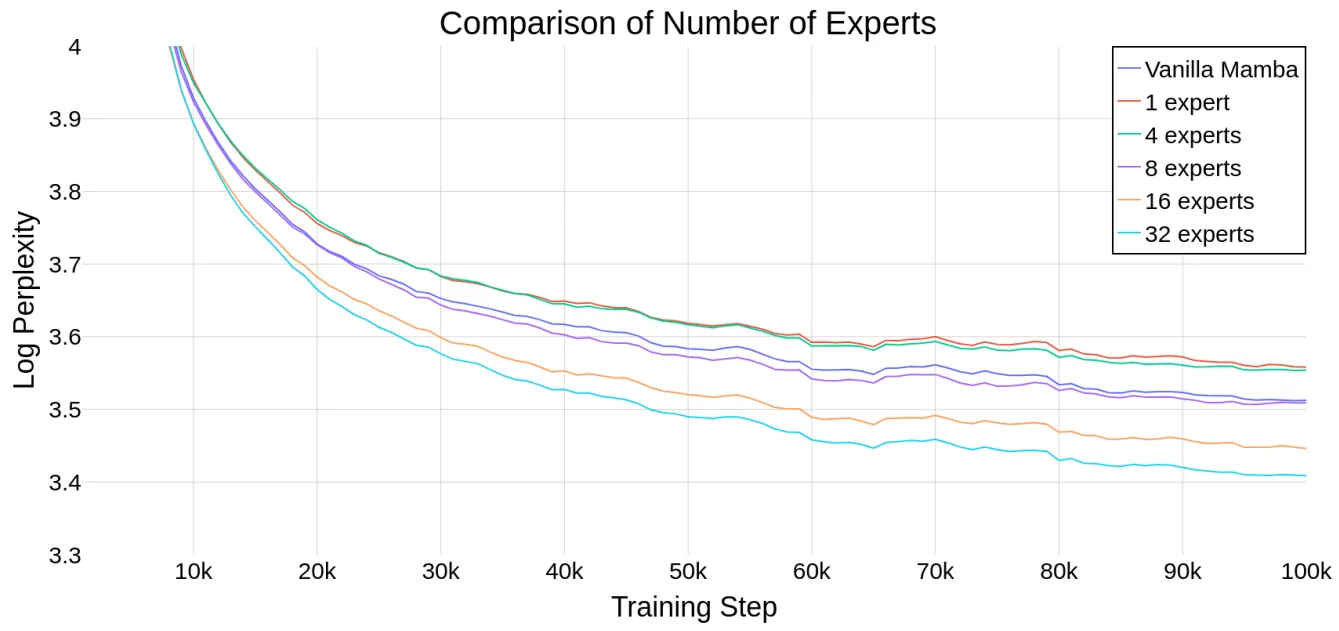
MoE中的专家数量是MoE-Mamba中的一个重要超参数,为了评估Mamba能否随着专家数量的增加而扩展,作者在下图绘制了模型在不同专家数量情况下的运行情况,并且加入了Mamba 和 Mamba-MLP(后者相当于具有单个专家的 MoE-Mamba)作为参考。上表展示了模型在10万训练steps之后的结果,结果表明,MoE-Mamba可以很好的适应专家数量的变化,如果专家数量设置为8或超过8,MoE-Mamba可以获得比普通Mamba模型更好的最终性能。
04. 总结
本文提出了一种将专家混合MoE技术与Mamba架构进行集成的模块,即MoE-Mamba。基于并行计算的天然优势,Mamba减轻了大模型中复杂循环顺序性质的影响,并且对硬件进行感知来实现参数扩展。Mamba相比普通注意力机制Transformer解决了序列模型中效率和有效性之间的基本权衡,强调了状态压缩的重要性。将Mamba与高度稀疏的MoE前馈层交错设置可以实现更高推理效率的LLM,但目前的组合方式仍然非常简单,作者也探索了一种局部并行的Mamba+MoE架构以实现更高的预测准确率和更稀疏的推理效果。期望后续有更多基于条件计算与状态空间模型技术相结合的技术出现,作者认为这条道路将能够更有效地扩展到更大的语言模型中。
参考
[1] Gu A, Dao T. Mamba: Linear-time sequence modeling with selective state spaces[J]. arXiv preprint arXiv:2312.00752, 2023.
[2] Sanseviero, O., Tunstall, L., Schmid, P., Mangrulkar, S., Belkada, Y., and Cuenca, P. Mixture of experts explained, 2023. URL https://huggingface.co/blog/moe.
[3] Mistral. Mixtral of experts, Dec 2023. URL https://mistral.ai/news/mixtral-of-experts/.
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
这篇关于Mamba与MoE架构强强联合,Mamba-MoE高效提升LLM计算效率和可扩展性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






