本文主要是介绍c 数据压缩算法_数据结构与算法在前端领域的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是一个我即将做的一个《数据结构与算法在前端领域的应用》主题演讲的一个主菜。 如果你对这部分内容比较生疏,可以看我的数据结构和算法在前端领域的应用(前菜)
这里我会深入帮助大家如何根据业务抽离出纯粹的模型,从而转化为算法问题,
如果大家对数据结构和算法感兴趣,欢迎关注我的个人公众号,或者入群和我交流,二维码在文章末尾。
关于我
我是一个对技术充满兴趣的程序员, 擅长前端工程化,前端性能优化,前端标准化等。
做过 .net, 搞过 Java,现在是一名前端工程师。
除了我的本职工作外,我会在开源社区进行一些输出和分享,GitHub 共计获得 1.5W star。比较受欢迎的项目有leetcode 题解 , 宇宙最强的前端面试指南 和 我的第一本小书
以上帝角度来看前端
让我们以更高的层次来看一下,从大的范围上前端领域都在做什么?
从业务上来说,我们会去做各个端的开发、网关、接口、工程化。 从技术上说,则是基于 WEB、Node 的通用技术,以及各平台(最常见的就是安卓和 IOS)的专有技术。
在这里我以自己的标准总结了以下三点:
- 架构和平台
其实平台建设也是架构中的一环,之所以列出来单独讲是因为这块内容相对比较大。 每个公司,部门,项目都有自己的架构设计和规范。它们环环相套组成了整个公司的架构体系。
很多公司在做工具链,在做跨端方案,在做底层融合等,这些都属于这个范畴。 比如最近比较火的 Serverless 也是属于这个范畴。
- 规范和标准化
前端行业规范目前来看的话就两个,一个是 ECMA 的规范,一个是 W3C 的规范。 前端行业规范是非常重要的,不然前端会非常混乱,想一下前端刚刚诞生出来的时候就知道了。
公司内部也会有一些规范,但是很难上升到标准层次。 目前国内没有一个行业认可的标准化组织, 这算是一个遗憾吧。 好消息是国人在标准化组织的参与感越来越强,做了更多的事情。
其实这部分我们的感知是比较弱的,一个原因就是我们一直在努力对接行业的标准,很少去自己创造一些标准。 原因有几点,一方面自己做标准,维护更新标准很难,另一方面自己做标准需要学习成本和转换成本。
但是这并不意味这做公司标准或者行业领域规范就没有用,相反非常有用。我之前做过一个《标准化能给我们带来什么》的 分享,详细介绍了标准化对于我们的重要性。
- 生态体系
其实前端的工作就是人机交互,这其中涉及的东西很多,相关领域非常广泛。
比如智能手表、智能 TV、智能眼镜、头戴 AR,VR 等新的交互模式我们如何去融入现有开发体系中 ? 人工智能在前端开发可以发挥怎么样的作用 ? 这些其实很多公司已经在尝试,并且取得了非常不错的效果。
比如 IDE 是开发过程非常重要的工具,我们是否可以去做标准化的 IDE,甚至放到云端。
无处不在的算法
上面我们从多个方面重新审视了一下前端,除了人工智能部分,其他部分根本没有提到算法。 是不是算法在前端领域应用很少呢? 不是的。
一方面就像上一节介绍的,我们日常开发中使用的很多东西都是经过数据结构和算法的精心封装, 比如 DOM 和 VDOM,以及 JSON。 JSON的序列化和反序列化是我们无时无刻使用的方法, 比如我们需要和后端进行数据交互,需要和其他线程(比如webworker)进行数据交互都要经过 序列化和反序列化,如何减少数据传输,如何提高序列化和反序列化的效率,如何在两者 之间寻求一种平衡都是我们需要研究的。
JSON 也是一种树结构
甚至还有很多框架以数据结构直接命名,比如 GraphQL,就是 用图这种数据结构来命名,从而体现其强大的关联查询能力。 比如 tensorflow 以张量(tensor)来加深大家对上面两点的印象命名,
TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。
上面提到的各个环节都或多或少会用到算法。首先网络部分就涉及到很多算法, 比如有限状态机,滑动窗口,各种压缩算法,保障我们信息不泄漏的各种加密算法等等,简直不要太多。 虽然这些网络部分很多都是现成的,但是也不排除有一些需要我们自己根据当前实际场景自己去搭建一套的可能。 这在大公司之中是非常常见的。
我们再来看下执行我们代码的引擎,以 V8 为例,其本身涉及的算法不算在内。 但是当我们基于 V8 去做一些事情,我们就需要了解一些编译相关的原理。 这里我举个例子,下图是支付宝的小程序架构。 如果我们不懂一些算法的话, 是很难像支付宝一样结合自己的业务去做一些突破的。
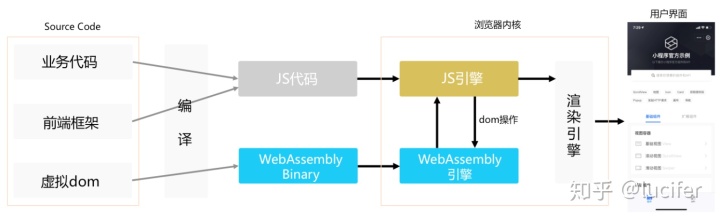
(图片来自 https://www.infoq.cn/article/ullETz7q_Ue4dUptKgKC)
另外一些高层的架构中也会有很多算法方面的东西,比如我需要在前端做增量更新的功能。 增量更新在APP中早已不是新鲜的东西了,但是真正做JS等静态资源的实时增量更新还比较少, 这里面会涉及非常复杂的交互和算法。
上面提到的更多的是高层面上,事实上即使是业务层面也有很多值得挖掘的算法模型。 我们需要从复杂的业务中提炼出算法模型,才能得到实际应用。可惜的是很多时候我们缺乏这种抽象能力和意志。
除了上一节我讲述的常见场景之外,我还会在下一节介绍几个实际业务场景,从而加深大家的理解。 希望大家看了之后,能够在自己的实际业务中有所帮助。
性能和优雅,我全都要
从表象上看,使用合适的数据结构和算法有两方面的好处。
第一个是性能,这个比较好理解一点,我们追求更好的时间复杂度和空间复杂度, 并且我们需要不断地在两者之间做合理的取舍。
第二点是优雅,使用合适的数据结构和算法。能让我们处理问题更加简洁优雅。
下面我会举几个我在实际业务场景中的例子,来加深大家对上面两点的印象。
权限系统
假如你现在开发一款类似石墨文档的多人在线协作编辑文档系统。
这里面有一个小功能是权限系统。 用户可以在我们的系统中创建文件夹和文件, 并且管理角色,不同的角色可以分配不同的文件权限。 比如查看,下载,编辑,审批等。
我们既可以给文件夹分配权限,又可以给文件分配权限,如果对应文件该角色没有权限, 我们需要递归往上搜索,看有没有相应权限,如果有,则这个角色有文件的该操作权限。
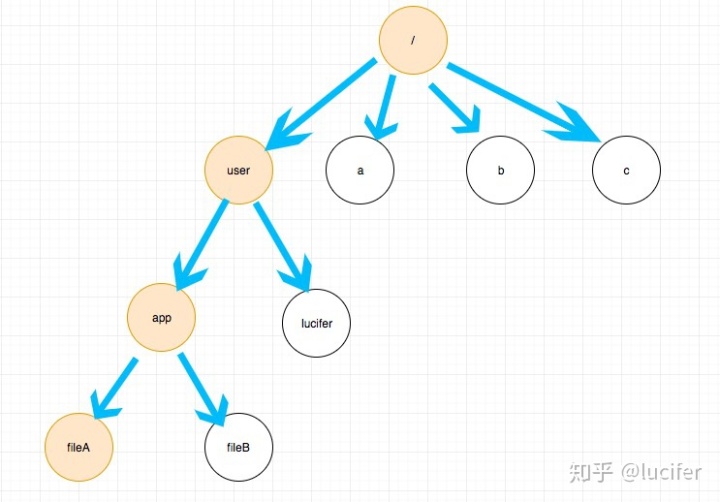
如图,fileA 的权限就需要从 fileA 开始看有没有对应权限,如果有,则返回有权限。 如果没有,则查找 app 文件夹的权限,重复这个过程,直到根节点。
如果你是这个系统的前端负责人,你会如何设计这个系统呢?
其实做这个功能的方案有很多,我这里参考了 linux 的设计。 我们使用一个二进制来标示一个权限有还是没有。
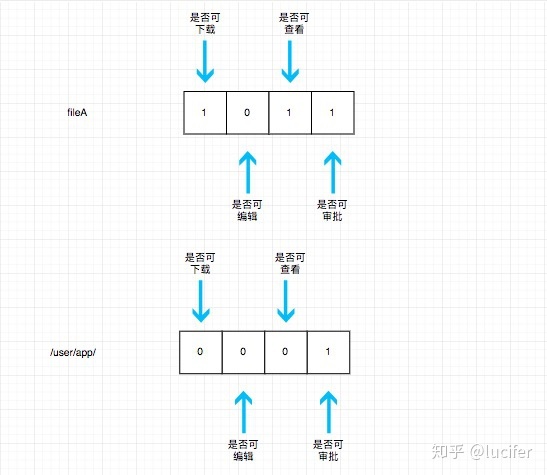
这样的话,一方面我们只需要 4 个 bit 就可以存储权限信息,存储已经是极限了。 另一方面我们通过位运算即可算出有没有权限,二进制运算在计算性能上也是极限了。
另外代码写起来,也会非常简洁,感兴趣的可以自己试试。
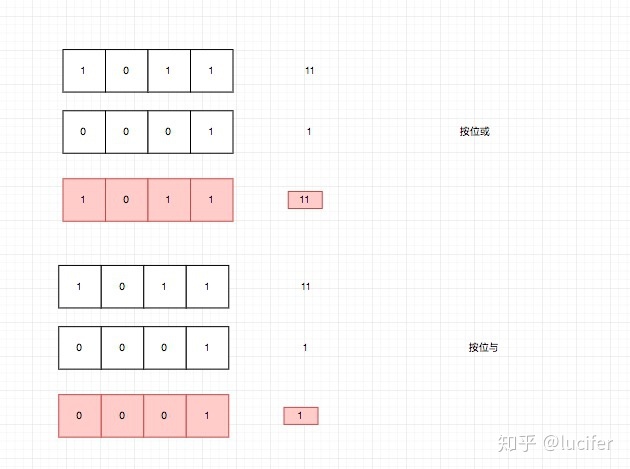
扩展: 假如文件权限不是只有两种可能,比如有三个取值怎么办?
状态机
什么是状态机
状态机表示若干个状态以及在这些状态之间的转移和动作等行为的数学模型。 通俗的描述状态机就是定义了一套状态変更的流程:状态机包含一个状态集合, 定义当状态机处于某一个状态的时候它所能接收的事件以及可执行的行为,执行完成后,状态机所处的状态。
我们以现实中广泛使用的有限状态机(以下简称 FSM)为例进行讲解
FSM 应用非常广泛, 比如正则表达式的引擎,编译器的词法和语法分析,网络协议,企业应用等很多领域都会用到。
其中正则中使用的是一种特殊的 FSM, 叫 DFA(Deterministic Finite Automaton), 通过分裂树形式来运行。
为什么要使用状态机
第一个原因,也是大家感触最深的一个原因就是通过状态机去控制系统内部的状态以及状态流转,逻辑会 比较清晰,尤其在逻辑比较复杂的时候,这种作用越发明显。
第二个原因是通过状态机,我们可以实现数据以及系统的可视化。刚才我提到了正则表达式用到了状态机, 那么正则是否可以可视化呢? 答案是肯定的,这里我介绍一个可视化正则表达式的一个网站。

实际业务中如果使用状态机来设计系统也可以进行可视化。类似这样子:
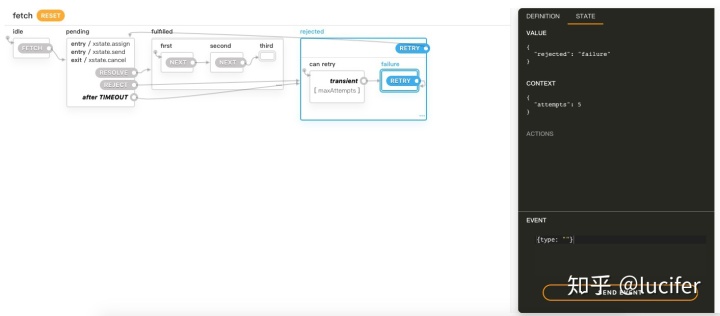
(图来自 https://statecharts.github.io/xstate-viz/)
可以看出,逻辑流转非常清晰,我们甚至可以基于此进行调试。 当然,将它作为文档的一部分也是极好的,关于状态机的实际意义还有很多,我们接下来举几个例子说明。
状态机的实际应用场景
匹配三的倍数
实现一个功能,判断一个数字是否是三的倍数。 数字可以非常大,以至于超过 Number 的表示范围, 因此我们需要用 string 来存储。
一个简单直观的做法是直接将每一位都加起来,然后看加起来的数字是否是三的倍数。 但是如果数字大到一定程度,导致加起来的数字也超过了 Number 的表示范围呢?
一个方法是使用状态机来解决。
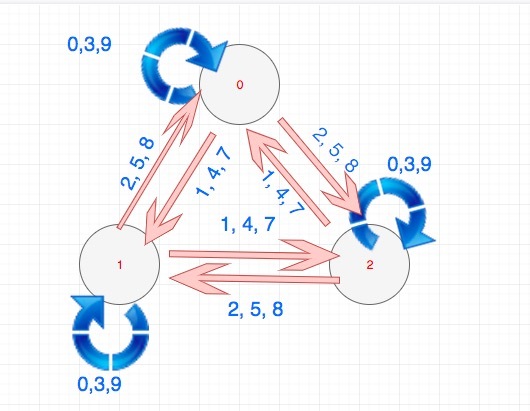
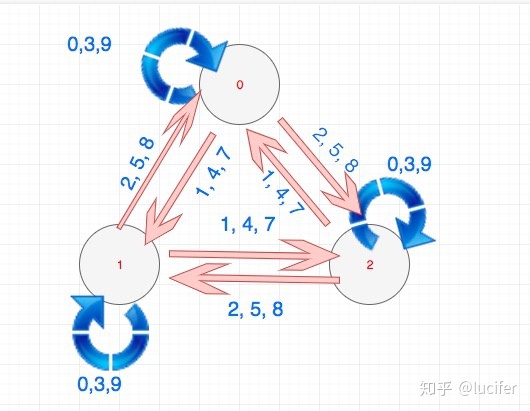
我们发现一个数字除以 3 的余数一共有三种状态,即 0,1,2。 基于此我们可以构建一个 FSM。 0,1,2 之间的状态流转也不难得出。
举个例子,假设当前我们是余数为 0 的状态,这时候再来一个字符。
- 如果这个字符是 0,3 或者 9,那么我们的余数还是 0
- 如果这个字符是 1,4 或者 7,那么我们的余数是 1
- 如果这个字符是 2,5 或者 8,那么我们的余数还是 2
用图大概是这个样子:
如果用代码大概是这样的:
function createFSM() {return {initial: 0,states: {0: {on: {read(ch) {return {0: 0,3: 0,9: 0,1: 1,4: 1,7: 1,2: 2,5: 2,8: 2}[ch];}}},1: {on: {read(ch) {return {0: 1,3: 1,9: 1,1: 2,4: 2,7: 2,2: 0,5: 0,8: 0}[ch];}}},2: {on: {read(ch) {return {0: 2,3: 2,9: 2,1: 0,4: 0,7: 0,2: 1,5: 1,8: 1}[ch];}}}}};
}const fsm = createFSM();
const str = "281902812894839483047309573843389230298329038293829329";
let cur = fsm.initial;for (let i = 0; i < str.length; i++) {if (!["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"].includes(str[i])) {throw new Error("非法数字");}cur = fsm.states[cur].on.read(str[i]);
}
if (cur === 0) {console.log("可以被3整除");
} else {console.log("不可以被3整除");
} 其实代码还可以简化,读者可以下去尝试一下。
可以看出,我们这种方式逻辑清晰,且内存占用很少,不会出现溢出的情况。
正则是基于自动机实现的,那么使用正则匹配会是怎么样的呢?大家可以自己试一下。
答题活动
经过上面的热身,我们来一个真实的项目来练练手。
有这样一个业务场景,我们需要设计一款答题活动,让用户过来进行答题, 我们预先设置 N 道题目。 规则如下:
- 初始状态用户会进入欢迎页面
- 答对之后可以直接进入下一个题目
- 答错了可以使用复活卡重新答,也可以使用过关卡,直接进入下一题
- 用户可以通过其他途径获取复活卡和过关卡
- 答对全部 N 道题之后用户过关,否则失败
- 不管是过关还是失败都展示结果页面,只不过展示不同的文字和图片
这其实是一个简化版本的真实项目。 如果要你设计这样的一个系统,你会如何设计?
相信你肯定能想出很多种方法来完成这样的需求,接下来我会用 FSM 来实现。
我们很容易画出整理的流程图:
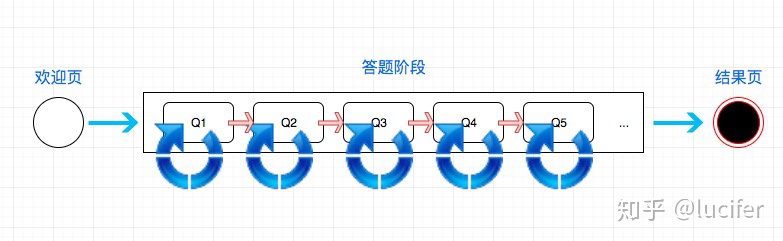
对于答题部分则稍微有一点麻烦,但是如果你用状态机的思维去思考就很容易, 我们不难画出这样的图:
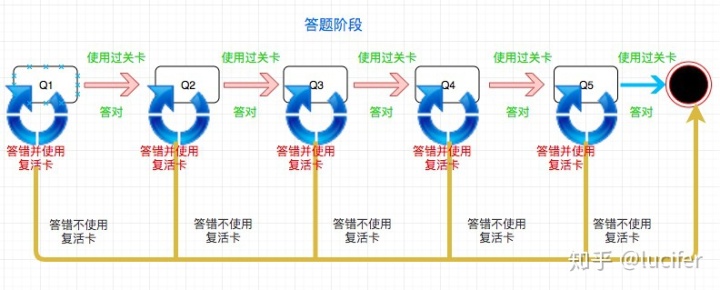
JS 中有很多 FSM 的框架, 大家都可以直接拿过来使用。 笔者之前所在的项目 也用到了这样的技术,但是笔者是自己手写的简化版本 FSM,基本思想是一致的。
其他
事实上,还有很多例子可以举。
假设我们后端服务器是一主一备,我们将所有的数据都同时存储在两个服务器上。 假如某一天,有一份数据丢失了,我们如何快速找到有问题的服务器。
这其实可以抽象成【Signle Number问题】。 因此很多时候,不是缺乏应用算法的场景, 而是缺乏这种将现实业务进行抽象为纯算法问题的能力。 我们会被各种细枝末节的问题遮蔽双眼,无法洞察隐藏在背后的深层次的规律。
编程最难是抽象能力,前几年我写了一篇文章《为什么我们的代码难以维护》, 其中一个非常重要的原因就是缺乏抽象。
从现在开始,让我们来锻炼抽象能力吧。
关注我
最近我重新整理了下自己的公众号,并且我还给他换了一个名字《脑洞前端》,它是一个帮助你打开大前端新世界大门的钥匙 ,在这里你可以听到新奇的观点,看到一些技术尝新,还会收到系统性总结和思考。
我会尽量通过图的形式来阐述一些概念和逻辑,帮助大家快速理解,图解前端是我的目标。
之后我的文章同步到微信公众号 脑洞前端 ,您可以关注获取最新的文章,或者和我进行交流。

交流群
现在还是初级阶段,需要大家的意见和反馈,为了减少沟通成本,我组建了交流群。大家可以扫码进入
QQ 群

微信群

(由于微信的限制,100 个人以上只能邀请加入, 你可以添加我的机器人回复“大前端”拉你进群)
这篇关于c 数据压缩算法_数据结构与算法在前端领域的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






