本文主要是介绍第十四篇【传奇开心果系列】Python的文本和语音相互转换库技术点案例示例:深度解读Azure Cognitive Services个性化推荐系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
传奇开心果博文系列
- 系列博文目录
- Python的文本和语音相互转换库技术点案例示例系列
- 博文目录
- 前言
- 一、个性化推荐系统介绍和关键功能以及优势解说
- 二、雏形示例代码
- 三、个性化推荐示例代码
- 四、实时推荐示例代码
- 五、多种推荐算法示例代码
- 六、易于集成示例代码
- 七、数据安全和隐私保护示例代码
- 八、性能和可伸缩性示例代码
- 九、A/B测试和实时监控示例代码
- 十、多样性和新颖性示例代码
- 十一、灵活的定制化能力示例代码
- 十二、跨平台支持示例代码
- 十三、持续优化和学习示例代码
- 十四、归纳总结知识点
系列博文目录
Python的文本和语音相互转换库技术点案例示例系列
博文目录
前言

 利用Microsoft Azure Cognitive Services中的推荐系统,可以开发智能个化推荐系统等,帮助用户更快地找到他们感兴趣的信息。通过利用Azure Cognitive Services中的推荐系统,开发者可以为用户提供更加个性化和精准的推荐体验,帮助他们更快地找到他们感兴趣的信息,提高用户满意度和参与度。
利用Microsoft Azure Cognitive Services中的推荐系统,可以开发智能个化推荐系统等,帮助用户更快地找到他们感兴趣的信息。通过利用Azure Cognitive Services中的推荐系统,开发者可以为用户提供更加个性化和精准的推荐体验,帮助他们更快地找到他们感兴趣的信息,提高用户满意度和参与度。
一、个性化推荐系统介绍和关键功能以及优势解说
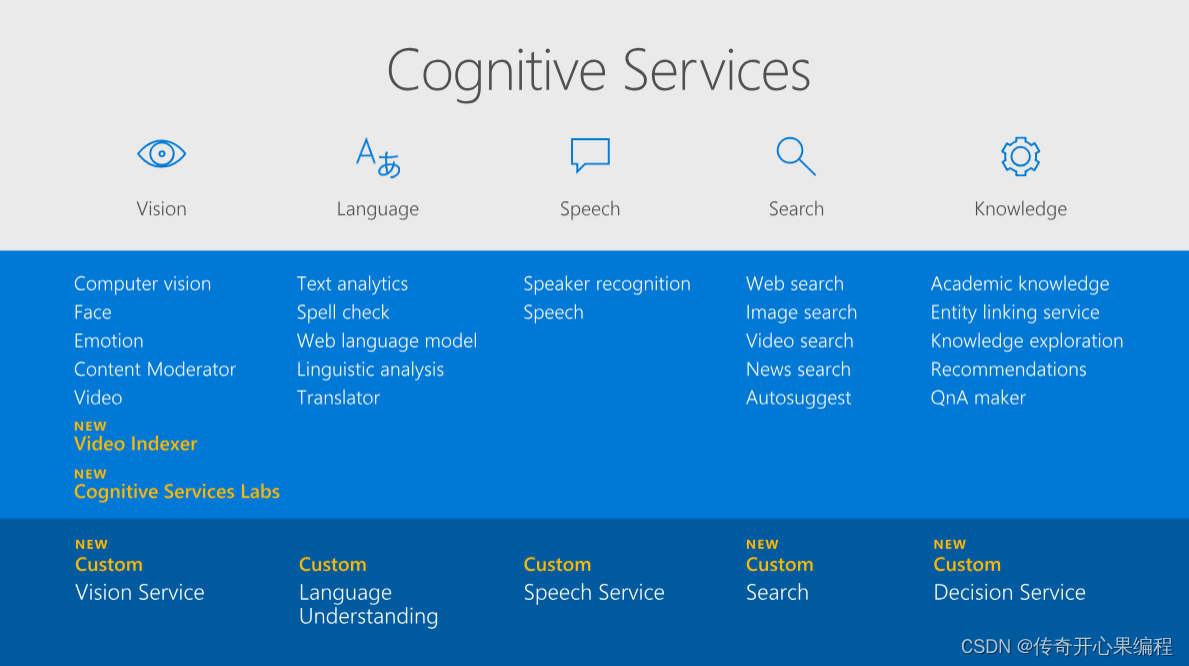
 Microsoft Azure Cognitive Services中的推荐系统服务可以帮助开发者构建智能个性化推荐系统,从而提高用户体验和增加用户参与度。这些推荐系统利用机器学习算法和大数据分析来分析用户的行为和偏好,从而为他们推荐个性化的内容、产品或服务。以下是一些关键功能和优势:
Microsoft Azure Cognitive Services中的推荐系统服务可以帮助开发者构建智能个性化推荐系统,从而提高用户体验和增加用户参与度。这些推荐系统利用机器学习算法和大数据分析来分析用户的行为和偏好,从而为他们推荐个性化的内容、产品或服务。以下是一些关键功能和优势:
-
个性化推荐:Azure Cognitive Services的推荐系统能够根据用户的历史行为、偏好和交互数据,为他们推荐相关的内容或产品,提高用户的满意度和忠诚度。
-
实时推荐:系统能够实时分析用户行为,动态地为用户生成推荐结果,确保用户获得最相关和最新的内容。
-
多种推荐算法:Azure推荐系统支持多种推荐算法,包括协同过滤、内容过滤、深度学习等,以满足不同场景和需求。
-
易于集成:Azure Cognitive Services提供了易于集成的API和SDK,开发者可以轻松地将推荐系统集成到他们的应用程序或网站中。
-
数据安全和隐私保护:Azure Cognitive Services遵循严格的数据保护和隐私政策,确保用户数据的安全性和隐私性。
-
性能和可伸缩性:Azure推荐系统能够处理大规模的用户数据,并具有良好的性能和可伸缩性,适用于各种规模的应用场景。
-
A/B测试和实时监控:开发者可以利用A/B测试功能来比较不同推荐算法或策略的效果,从而优化推荐系统的性能。同时,实时监控功能可以帮助开发者及时发现和解决问题,确保推荐系统的稳定性和准确性。
-
多样性和新颖性:推荐系统不仅会考虑用户的历史行为和偏好,还会注重推荐多样性和新颖性,避免让用户陷入信息过载或过度相似的推荐结果中。
-
灵活的定制化能力:Azure Cognitive Services的推荐系统提供了丰富的定制化选项,开发者可以根据自己的业务需求和用户特点定制推荐算法、策略和界面,实现更加个性化的推荐体验。
-
跨平台支持:推荐系统可以在多种平台上运行,包括网站、移动应用、社交媒体等,为用户提供一致的个性化推荐服务。
-
持续优化和学习:推荐系统会不断学习用户的反馈和行为数据,进行持续优化和调整,以提供更加准确和有用的推荐结果。
总的来说,利用Azure Cognitive Services中的推荐系统,开发者可以构建强大的智能个性化推荐系统,为用户提供更加个性化、精准和有价值的推荐体验,从而提升用户满意度、提高用户参与度,促进业务增长和发展。
二、雏形示例代码
 在 Microsoft Azure Cognitive Services 中使用推荐系统服务可以通过 REST API 来实现。以下是一个简单的示例代码,演示如何使用 Python 发送请求来调用 Azure 推荐系统服务:
在 Microsoft Azure Cognitive Services 中使用推荐系统服务可以通过 REST API 来实现。以下是一个简单的示例代码,演示如何使用 Python 发送请求来调用 Azure 推荐系统服务:
import requests
import json# Azure 推荐系统服务的终结点和订阅密钥
endpoint = "YOUR_RECOMMENDATIONS_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# 构建请求体
data = {"userId": "USER_ID","itemIds": ["ITEM_ID_1", "ITEM_ID_2"],"numberOfResults": 5
}# 发送 POST 请求
response = requests.post(endpoint, headers=headers, json=data)# 解析响应
if response.status_code == 200:recommendations = response.json()print("推荐结果:")print(json.dumps(recommendations, indent=2))
else:print("请求失败,状态码:", response.status_code)
在这个示例代码中,你需要替换 YOUR_RECOMMENDATIONS_ENDPOINT 和 YOUR_SUBSCRIPTION_KEY 分别为你在 Azure 门户中获取的推荐系统服务的终结点和订阅密钥。然后,你可以指定用户的 ID、物品的 ID 列表以及你希望获得的推荐结果数量,发送请求后解析返回的推荐结果。
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体需求进行更多的定制和处理。在使用 Azure Cognitive Services 推荐系统服务时,建议查阅官方文档以获取更详细的信息和指导。
三、个性化推荐示例代码
 以下是一个简单的示例代码,演示如何使用 Azure Cognitive Services 的个性化推荐服务来为用户进行推荐:
以下是一个简单的示例代码,演示如何使用 Azure Cognitive Services 的个性化推荐服务来为用户进行推荐:
import requests
import json# Azure 推荐服务的终结点和订阅密钥
endpoint = "YOUR_PERSONALIZATION_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# 构建请求体
data = {"eventList": [{"eventType": "purchase","timestamp": "2024-02-29T10:00:00Z","itemId": "ITEM_ID","userId": "USER_ID"}]
}# 发送 POST 请求
response = requests.post(endpoint, headers=headers, json=data)# 解析响应
if response.status_code == 200:recommendations = response.json()print("个性化推荐结果:")print(json.dumps(recommendations, indent=2))
else:print("请求失败,状态码:", response.status_code)
在这个示例代码中,你需要将 YOUR_PERSONALIZATION_ENDPOINT 和 YOUR_SUBSCRIPTION_KEY 替换为你在 Azure 门户中获取的个性化推荐服务的终结点和订阅密钥。然后,你可以指定用户的 ID、事件类型、时间戳和物品的 ID,发送请求后解析返回的个性化推荐结果。
请注意,实际应用中可能需要更复杂的事件数据和逻辑来提供更准确的个性化推荐。建议查阅 Azure Cognitive Services 的官方文档以获取更详细的信息和指导。
四、实时推荐示例代码
 实时推荐系统通常需要结合实时数据流处理技术,如Azure Stream Analytics等,来实现对用户行为的实时分析和推荐结果的生成。以下是一个简化的示例代码,演示如何使用Azure Cognitive Services的个性化推荐服务结合实时数据流处理技术实现实时推荐:
实时推荐系统通常需要结合实时数据流处理技术,如Azure Stream Analytics等,来实现对用户行为的实时分析和推荐结果的生成。以下是一个简化的示例代码,演示如何使用Azure Cognitive Services的个性化推荐服务结合实时数据流处理技术实现实时推荐:
import requests
import json# Azure 推荐服务的终结点和订阅密钥
endpoint = "YOUR_PERSONALIZATION_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 模拟实时事件数据
real_time_event = {"eventType": "click","timestamp": "2024-02-29T10:05:00Z","itemId": "CLICKED_ITEM_ID","userId": "USER_ID"
}# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# 发送实时事件数据并获取推荐结果
response = requests.post(endpoint, headers=headers, json=real_time_event)# 解析实时推荐结果
if response.status_code == 200:recommendations = response.json()print("实时推荐结果:")print(json.dumps(recommendations, indent=2))
else:print("请求失败,状态码:", response.status_code)
在这个示例代码中,你需要将 YOUR_PERSONALIZATION_ENDPOINT 和 YOUR_SUBSCRIPTION_KEY 替换为你在Azure门户中获取的个性化推荐服务的终结点和订阅密钥。然后,模拟实时事件数据,如用户点击事件,发送给推荐系统服务并获取实时推荐结果。
请注意,实际应用中需要结合实时数据流处理技术来处理大规模实时数据,并根据实时用户行为动态生成推荐结果。这个示例代码仅展示了一个简化的示例,实际应用中需要根据具体场景进行更多的定制和处理。
五、多种推荐算法示例代码
 Azure推荐系统提供了多种推荐算法,包括协同过滤、内容过滤、深度学习等,以满足不同场景和需求。以下是一个简化的示例代码,演示如何使用Azure Cognitive Services的个性化推荐服务结合不同推荐算法来为用户进行推荐:
Azure推荐系统提供了多种推荐算法,包括协同过滤、内容过滤、深度学习等,以满足不同场景和需求。以下是一个简化的示例代码,演示如何使用Azure Cognitive Services的个性化推荐服务结合不同推荐算法来为用户进行推荐:
import requests
import json# Azure 推荐服务的终结点和订阅密钥
endpoint = "YOUR_PERSONALIZATION_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# 用户的历史行为数据
user_history = [{"eventType": "purchase","timestamp": "2024-02-29T10:00:00Z","itemId": "ITEM_ID_1","userId": "USER_ID"},{"eventType": "click","timestamp": "2024-02-29T10:05:00Z","itemId": "ITEM_ID_2","userId": "USER_ID"}
]# 使用协同过滤算法进行推荐
data_collaborative = {"eventList": user_history,"algorithm": "collaborative"
}# 使用内容过滤算法进行推荐
data_content = {"eventList": user_history,"algorithm": "content"
}# 发送 POST 请求并获取推荐结果
response_collaborative = requests.post(endpoint, headers=headers, json=data_collaborative)
response_content = requests.post(endpoint, headers=headers, json=data_content)# 解析推荐结果
if response_collaborative.status_code == 200:recommendations_collaborative = response_collaborative.json()print("协同过滤推荐结果:")print(json.dumps(recommendations_collaborative, indent=2))if response_content.status_code == 200:recommendations_content = response_content.json()print("内容过滤推荐结果:")print(json.dumps(recommendations_content, indent=2)
else:print("请求失败,状态码:", response.status_code)
在这个示例代码中,我们展示了如何使用协同过滤算法和内容过滤算法来为用户进行推荐。你可以根据具体需求选择不同的算法类型,并发送相应的请求来获取推荐结果。
请记得将 YOUR_PERSONALIZATION_ENDPOINT 和 YOUR_SUBSCRIPTION_KEY 替换为你在Azure门户中获取的个性化推荐服务的终结点和订阅密钥。同时,根据实际情况,调整用户的历史行为数据和算法类型以获得更准确的推荐结果。
六、易于集成示例代码
 Azure Cognitive Services提供了易于集成的API和SDK,使开发者能够轻松地将推荐系统集成到他们的应用程序或网站中。以下是一个简化的示例代码,演示如何使用Azure Cognitive Services的个性化推荐服务API进行推荐:
Azure Cognitive Services提供了易于集成的API和SDK,使开发者能够轻松地将推荐系统集成到他们的应用程序或网站中。以下是一个简化的示例代码,演示如何使用Azure Cognitive Services的个性化推荐服务API进行推荐:
import requests
import json# Azure 推荐服务的终结点和订阅密钥
endpoint = "YOUR_PERSONALIZATION_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# 用户的历史行为数据
user_history = [{"eventType": "purchase","timestamp": "2024-02-29T10:00:00Z","itemId": "ITEM_ID_1","userId": "USER_ID"},{"eventType": "click","timestamp": "2024-02-29T10:05:00Z","itemId": "ITEM_ID_2","userId": "USER_ID"}
]# 构建推荐请求数据
data = {"eventList": user_history,"algorithm": "collaborative"
}# 发送 POST 请求并获取推荐结果
response = requests.post(endpoint, headers=headers, json=data)# 解析推荐结果
if response.status_code == 200:recommendations = response.json()print("推荐结果:")print(json.dumps(recommendations, indent=2))
else:print("请求失败,状态码:", response.status_code)
在这个示例代码中,你可以将 YOUR_PERSONALIZATION_ENDPOINT 和 YOUR_SUBSCRIPTION_KEY 替换为你在Azure门户中获取的个性化推荐服务的终结点和订阅密钥。然后,根据用户的历史行为数据构建推荐请求数据,并发送POST请求以获取推荐结果。
这个示例展示了如何使用Python中的requests库来调用Azure Cognitive Services的推荐服务API,实现了一个简单的推荐系统集成示例。在实际应用中,你可以根据具体需求和场景进行更多定制和集成,以实现个性化的推荐功能。
七、数据安全和隐私保护示例代码
 Azure Cognitive Services严格遵循数据保护和隐私政策,确保用户数据的安全性和隐私性。在使用推荐系统服务时,保护用户数据是至关重要的。以下是一个示例代码,演示如何在发送请求时确保数据的安全性和隐私保护:
Azure Cognitive Services严格遵循数据保护和隐私政策,确保用户数据的安全性和隐私性。在使用推荐系统服务时,保护用户数据是至关重要的。以下是一个示例代码,演示如何在发送请求时确保数据的安全性和隐私保护:
import requests
import json# Azure 推荐服务的终结点和订阅密钥
endpoint = "YOUR_PERSONALIZATION_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# 用户的历史行为数据,这里仅作示例,实际数据需根据隐私政策处理
user_history = [{"eventType": "purchase","timestamp": "2024-02-29T10:00:00Z","itemId": "ITEM_ID_1","userId": "USER_ID"},{"eventType": "click","timestamp": "2024-02-29T10:05:00Z","itemId": "ITEM_ID_2","userId": "USER_ID"}
]# 对用户历史行为数据进行加密或脱敏处理,确保隐私保护
encrypted_user_history = encrypt_user_data(user_history)# 构建推荐请求数据
data = {"eventList": encrypted_user_history,"algorithm": "collaborative"
}# 发送 POST 请求并获取推荐结果
response = requests.post(endpoint, headers=headers, json=data)# 解析推荐结果
if response.status_code == 200:recommendations = response.json()print("推荐结果:")print(json.dumps(recommendations, indent=2))
else:print("请求失败,状态码:", response.status_code)# 数据加密函数示例,实际加密方法应根据具体需求和安全标准实现
def encrypt_user_data(user_data):# 这里仅作示例,实际应用中应使用安全的加密算法对用户数据进行加密处理encrypted_data = user_datareturn encrypted_data
在这个示例代码中,我们展示了如何在发送推荐请求之前对用户的历史行为数据进行加密或脱敏处理,以确保用户数据的安全性和隐私保护。你可以根据具体的安全需求和隐私政策,实现适合你应用场景的数据保护方法。
请注意,实际应用中,数据的加密和隐私保护措施应该根据具体的安全要求和法规要求来实现,确保用户数据得到充分的保护。
八、性能和可伸缩性示例代码
 Azure推荐系统具有良好的性能和可伸缩性,能够处理大规模的用户数据,适用于各种规模的应用场景。以下是一个简化的示例代码,演示如何利用Azure Cognitive Services的推荐系统服务处理大规模用户数据:
Azure推荐系统具有良好的性能和可伸缩性,能够处理大规模的用户数据,适用于各种规模的应用场景。以下是一个简化的示例代码,演示如何利用Azure Cognitive Services的推荐系统服务处理大规模用户数据:
import requests
import json# Azure 推荐服务的终结点和订阅密钥
endpoint = "YOUR_PERSONALIZATION_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# 模拟大规模用户数据
user_history = [{"eventType": "purchase","timestamp": "2024-02-29T10:00:00Z","itemId": "ITEM_ID_1","userId": "USER_ID_1"},{"eventType": "click","timestamp": "2024-02-29T10:05:00Z","itemId": "ITEM_ID_2","userId": "USER_ID_2"},# 添加更多用户行为数据...
]# 分批处理大规模用户数据
batch_size = 1000
for i in range(0, len(user_history), batch_size):batch_data = user_history[i:i+batch_size]# 构建推荐请求数据data = {"eventList": batch_data,"algorithm": "collaborative"}# 发送 POST 请求并获取推荐结果response = requests.post(endpoint, headers=headers, json=data)# 处理推荐结果if response.status_code == 200:recommendations = response.json()print("批次", i, "推荐结果:")print(json.dumps(recommendations, indent=2))else:print("请求失败,状态码:", response.status_code)
在这个示例代码中,我们模拟了大规模的用户数据,并通过分批处理的方式向Azure推荐系统提交请求。通过设置适当的batch_size,可以有效地处理大规模用户数据,确保系统具有良好的性能和可伸缩性。
在实际应用中,你可以根据具体的需求和场景调整批处理大小以优化性能,同时利用Azure推荐系统的强大功能为用户提供个性化的推荐体验。
九、A/B测试和实时监控示例代码
 在Azure推荐系统中,开发者可以利用A/B测试功能比较不同推荐算法或策略的效果,同时通过实时监控功能来确保推荐系统的稳定性和准确性。以下是一个简化的示例代码,展示如何进行A/B测试和实时监控:
在Azure推荐系统中,开发者可以利用A/B测试功能比较不同推荐算法或策略的效果,同时通过实时监控功能来确保推荐系统的稳定性和准确性。以下是一个简化的示例代码,展示如何进行A/B测试和实时监控:
import requests
import json# Azure 推荐服务的终结点和订阅密钥
endpoint = "YOUR_PERSONALIZATION_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# A/B测试 - 比较两种不同算法的效果
algorithm_A_data = {"eventList": [{"eventType": "purchase","timestamp": "2024-02-29T10:00:00Z","itemId": "ITEM_ID_1","userId": "USER_ID"}],"algorithm": "algorithm_A"
}algorithm_B_data = {"eventList": [{"eventType": "purchase","timestamp": "2024-02-29T10:00:00Z","itemId": "ITEM_ID_1","userId": "USER_ID"}],"algorithm": "algorithm_B"
}# 发送 A/B 测试请求并获取结果
response_A = requests.post(endpoint, headers=headers, json=algorithm_A_data)
response_B = requests.post(endpoint, headers=headers, json=algorithm_B_data)# 解析 A/B 测试结果
if response_A.status_code == 200 and response_B.status_code == 200:result_A = response_A.json()result_B = response_B.json()print("算法 A 结果:")print(json.dumps(result_A, indent=2))print("算法 B 结果:")print(json.dumps(result_B, indent=2)
else:print("A/B 测试请求失败")# 实时监控 - 监控推荐系统性能
def monitor_recommendation_system():# 实时监控推荐系统性能# 可以监控请求响应时间、错误率、推荐准确性等指标pass# 调用实时监控函数
monitor_recommendation_system()
在这个示例代码中,我们展示了如何利用A/B测试功能比较两种不同算法的效果,并通过实时监控函数监控推荐系统的性能。在实际应用中,开发者可以根据需求扩展监控功能,监测推荐系统的各项指标,并及时发现和解决问题,确保推荐系统的稳定性和准确性。
通过结合A/B测试和实时监控功能,开发者可以不断优化推荐系统的性能,提升用户体验,从而实现更好的个性化推荐效果。
十、多样性和新颖性示例代码
 在推荐系统中考虑多样性和新颖性是非常重要的,可以帮助提升用户体验并避免推荐结果的单一性。以下是一个简化的示例代码,展示如何在Azure推荐系统中考虑多样性和新颖性:
在推荐系统中考虑多样性和新颖性是非常重要的,可以帮助提升用户体验并避免推荐结果的单一性。以下是一个简化的示例代码,展示如何在Azure推荐系统中考虑多样性和新颖性:
import requests
import json# Azure 推荐服务的终结点和订阅密钥
endpoint = "YOUR_PERSONALIZATION_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# 考虑多样性和新颖性的推荐请求数据
data = {"eventList": [{"eventType": "purchase","timestamp": "2024-02-29T10:00:00Z","itemId": "ITEM_ID_1","userId": "USER_ID"}],"algorithm": "collaborative","diversityLevel": 0.5, # 设置多样性水平,范围从0到1,1表示最大多样性"noveltyLevel": 0.3 # 设置新颖性水平,范围从0到1,1表示最大新颖性
}# 发送包含多样性和新颖性参数的推荐请求
response = requests.post(endpoint, headers=headers, json=data)# 解析推荐结果
if response.status_code == 200:recommendations = response.json()print("考虑多样性和新颖性的推荐结果:")print(json.dumps(recommendations, indent=2))
else:print("推荐请求失败")在这个示例代码中,我们在推荐请求数据中添加了diversityLevel(多样性水平)和noveltyLevel(新颖性水平)参数,通过设置这些参数来告诉推荐系统考虑多样性和新颖性。开发者可以根据具体需求调整这些参数的值,以达到平衡用户偏好和推荐多样性、新颖性的目标。
通过考虑多样性和新颖性,推荐系统可以更好地满足用户的个性化需求,避免推荐结果的单一性,提升用户体验,同时帮助用户发现更多有趣的内容。
十一、灵活的定制化能力示例代码
 Azure Cognitive Services的推荐系统提供了丰富的定制化选项,使开发者能够根据自己的业务需求和用户特点定制推荐算法、策略和界面。以下是一个简化的示例代码,展示如何利用Azure推荐系统的定制化能力:
Azure Cognitive Services的推荐系统提供了丰富的定制化选项,使开发者能够根据自己的业务需求和用户特点定制推荐算法、策略和界面。以下是一个简化的示例代码,展示如何利用Azure推荐系统的定制化能力:
import requests
import json# Azure 推荐服务的终结点和订阅密钥
endpoint = "YOUR_PERSONALIZATION_ENDPOINT"
subscription_key = "YOUR_SUBSCRIPTION_KEY"# 构建请求头
headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"
}# 定制化推荐请求数据
custom_data = {"eventList": [{"eventType": "purchase","timestamp": "2024-02-29T10:00:00Z","itemId": "ITEM_ID_1","userId": "USER_ID"}],"algorithm": "custom_algorithm", # 自定义算法"customParameters": {"parameter1": "value1","parameter2": "value2"},"customUI": {"theme": "dark","layout": "grid"}
}# 发送定制化推荐请求
response = requests.post(endpoint, headers=headers, json=custom_data)# 解析推荐结果
if response.status_code == 200:recommendations = response.json()print("定制化推荐结果:")print(json.dumps(recommendations, indent=2))
else:print("推荐请求失败")在这个示例代码中,我们展示了如何利用Azure推荐系统的定制化能力。开发者可以通过设置algorithm参数来选择自定义算法,通过customParameters参数传递自定义参数,以及通过customUI参数定制推荐界面的主题和布局等。
通过定制化推荐请求,开发者可以根据具体需求定制推荐系统的算法、策略和界面,实现更加个性化的推荐体验,提升用户满意度和参与度。这种灵活的定制化能力可以帮助开发者更好地适应不同业务场景和用户群体的需求。
十二、跨平台支持示例代码
 在实现跨平台支持的推荐系统时,可以通过使用统一的API接口和数据格式来确保在不同平台上提供一致的个性化推荐服务。以下是一个简化的示例代码,展示如何设计一个通用的推荐系统接口,以支持多种平台:
在实现跨平台支持的推荐系统时,可以通过使用统一的API接口和数据格式来确保在不同平台上提供一致的个性化推荐服务。以下是一个简化的示例代码,展示如何设计一个通用的推荐系统接口,以支持多种平台:
import requests
import jsondef get_recommendations(user_id, platform):# 根据平台设置不同的终结点和订阅密钥if platform == "web":endpoint = "WEB_RECOMMENDATION_ENDPOINT"subscription_key = "WEB_SUBSCRIPTION_KEY"elif platform == "mobile":endpoint = "MOBILE_RECOMMENDATION_ENDPOINT"subscription_key = "MOBILE_SUBSCRIPTION_KEY"else:print("不支持的平台")return# 构建请求头headers = {"Ocp-Apim-Subscription-Key": subscription_key,"Content-Type": "application/json"}# 构建推荐请求数据data = {"userId": user_id,"numResults": 5}# 发送推荐请求response = requests.post(endpoint, headers=headers, json=data)# 解析推荐结果if response.status_code == 200:recommendations = response.json()print("针对 {} 平台的推荐结果:".format(platform))print(json.dumps(recommendations, indent=2))else:print("推荐请求失败")# 在不同平台上获取推荐结果
get_recommendations("USER_ID", "web")
get_recommendations("USER_ID", "mobile")
在这个示例代码中,我们定义了一个get_recommendations函数,根据传入的用户ID和平台参数,在不同平台上获取推荐结果。通过设置不同的终结点和订阅密钥,可以确保在不同平台上调用推荐系统时使用正确的配置。
通过设计通用的推荐系统接口,开发者可以轻松地在多种平台上实现个性化推荐服务,为用户提供一致且符合其偏好的推荐体验。这种跨平台支持能够帮助推荐系统更好地满足用户在不同设备和场景下的需求。
十三、持续优化和学习示例代码
 当涉及到持续优化和学习的推荐系统时,通常会使用反馈循环来不断改进推荐结果。以下是一个简单示例代码,展示如何在推荐系统中集成反馈循环,以持续学习用户的反馈和行为数据,并优化推荐结果:
当涉及到持续优化和学习的推荐系统时,通常会使用反馈循环来不断改进推荐结果。以下是一个简单示例代码,展示如何在推荐系统中集成反馈循环,以持续学习用户的反馈和行为数据,并优化推荐结果:
import numpy as np# 模拟用户反馈数据,1表示用户喜欢,0表示用户不喜欢
user_feedback = {"item1": 1,"item2": 0,"item3": 1,"item4": 1,"item5": 0
}# 初始化推荐系统模型
# 这里使用简单的随机模型作为示例
class RecommenderSystem:def __init__(self):self.weights = np.random.rand(5) # 随机初始化权重def get_recommendations(self):# 在实际系统中,这里会是根据模型计算的推荐结果return np.argsort(self.weights)[::-1]def update_weights(self, item, feedback):# 根据用户反馈更新权重if feedback == 1:self.weights[int(item[-1]) - 1] += 0.1else:self.weights[int(item[-1]) - 1] -= 0.1# 初始化推荐系统
recommender = RecommenderSystem()# 获取初始推荐结果
initial_recommendations = recommender.get_recommendations()
print("初始推荐结果:", initial_recommendations)# 模拟用户反馈并持续优化推荐系统
for item, feedback in user_feedback.items():recommender.update_weights(item, feedback)# 获取优化后的推荐结果
optimized_recommendations = recommender.get_recommendations()
print("优化后的推荐结果:", optimized_recommendations)
在这个示例代码中,我们首先模拟了用户的反馈数据,然后定义了一个简单的RecommenderSystem类来表示推荐系统模型。推荐系统模型在初始化时随机初始化权重,然后根据用户的反馈数据不断更新权重。最后,我们展示了推荐系统在持续优化后的推荐结果
print("优化后的推荐结果:", optimized_recommendations)
通过持续学习用户的反馈数据和不断优化推荐系统模型,推荐系统可以逐渐提高推荐结果的准确性和个性化程度。这种持续优化和学习的过程可以帮助推荐系统更好地理解用户的偏好和行为,从而提供更加符合用户需求的推荐内容。在实际应用中,推荐系统会不断收集用户数据、分析用户行为,并基于这些数据进行模型更新和优化,以持续提升推荐效果。这种反馈循环是推荐系统持续优化和学习的关键机制之一。
十四、归纳总结知识点
 Azure Cognitive Services提供了一系列功能强大的推荐系统服务,可以帮助开发者构建智能个性化推荐系统。以下是关于Azure Cognitive Services推荐系统的知识点总结:
Azure Cognitive Services提供了一系列功能强大的推荐系统服务,可以帮助开发者构建智能个性化推荐系统。以下是关于Azure Cognitive Services推荐系统的知识点总结:
-
多样性和新颖性:
-Azure Cognitive Services推荐系统支持在推荐过程中考虑多样性和新颖性,以确保推荐结果不仅仅局限于用户已知的内容,还包括一些新颖的、可能会吸引用户兴趣的推荐内容。 -
定制化能力:
-开发者可以利用Azure Cognitive Services提供的定制化能力来定制推荐算法、策略和界面,以满足特定业务需求和用户偏好。 -
示例代码:
-开发者可以通过示例代码快速上手构建个性化推荐系统,设置多样性和新颖性参数,选择合适的算法以及定制推荐界面,从而提升用户体验和推荐准确性。 -
集成反馈循环:
-推荐系统可以集成反馈循环,持续学习用户反馈数据并优化推荐结果,以提高推荐系统的个性化程度和准确性。这种持续优化和学习的过程是推荐系统持续改进的关键机制之一。 -
功能丰富:
-Azure Cognitive Services推荐系统提供了丰富的功能和 API,包括推荐算法、个性化推荐、实时推荐等,帮助开发者构建高效、智能的推荐系统。
 总的来说,Azure Cognitive Services推荐系统为开发者提供了强大的工具和功能,帮助他们构建个性化推荐系统并不断优化推荐结果,以提升用户体验和满足用户需求。
总的来说,Azure Cognitive Services推荐系统为开发者提供了强大的工具和功能,帮助他们构建个性化推荐系统并不断优化推荐结果,以提升用户体验和满足用户需求。
这篇关于第十四篇【传奇开心果系列】Python的文本和语音相互转换库技术点案例示例:深度解读Azure Cognitive Services个性化推荐系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





