本文主要是介绍19、论文解读:Intensity Scan Context: Coding Intensity and Geometry Relations for Loop Closure Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Intensity Scan Context: Coding Intensity and Geometry Relations for Loop Closure Detection
文章链接:ISC-LOAM
文章代码:代码
编译&运行:建议参考:ubuntu16.04运行ISC-LOAM
我在编译运行遇到的问题以及解决办法:
1 、 编译无法通过:需要将cmakelist中设置C++11的那句改成set(CMAKE_CXX_FLAGS “-std=c++14”)
2、 libtbb.so.2: 无法添加符号:DSO missing from command line类问题的彻底解决
3、当出现版本不兼容的时候去ceres中的cmakelist中改eigen版本即可。
本文在SC描述子的基础上提出了一种新的基于距离和密度的全局描述子。通过二层搜索提升了搜索速度。
III. METHODOLOGY
A. Intensity Calibration and Pre-processing (强度校准和预处理)
之所以能够使用强度值作为回环检测是因为不同的物体反射的强度是完全不一样的,而同一物体的反射强度是一样的,这和物体表面材质有关,因而不同的场景构建的强度图也是不一样的,因此,点云强度信息可以用于回环检测。汽车、路牌、建筑物的反射强度如下图所示:

强度值受目标表面特征、采集形式、仪器精度等等因素影响,使用以下公式校准距离对强度的影响:
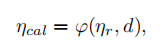
此外,为了方便将采集到的强度值(是一个8字节的整数)转换为0-1的范围中。
为了处理掉过于丰富的点云信息(比如噪声点)采取设置一个最大的有效范围作为第一步的过滤,还过滤掉了地面这类不重要的因素。
B.Intensity Scan Context
在笛卡尔坐标中的每一帧存N个点,每个点存x、y、z、η(强度信息)。转换成极坐标系下为:
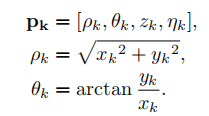
然后每帧像SC那样分割为Ns × Nr个栅格,每个栅格中存放最大的强度值,没有就存0.
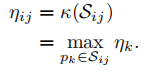
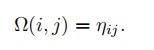
kitti数据集实例:

C.Place Re-identifification
通过辨识目标来和之前的访问过的存入数据库的数据匹配。为了降低和之前访问存入的数据库信息匹配的计算复杂度。提出了一种两阶段分层强度扫描上下文检索策略,利用快速二进制操作来加快位置加速识别的过程。
1)Fast Geometry Re-identifification: 如果有强度信息才进行几何匹配:
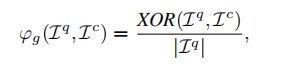
其中|x| 是x中元素的总数,XOR(x, y) 指矩阵x和y之间的元素排他OR运算。激光扫描的旋转变成了强度扫描上下文中的列位移,因此视角的变化可以解释为Ω的列偏移,最后的计分:
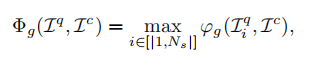
2)Intensity Structure Matching:
第二阶段主要通过列式比较来识别两种强度扫描上下文Ωq和Ωc之间的强度相似性。设viq和vic是Ωq和Ωc的第i列,则可以通过以下的余弦距离公式得到分数:
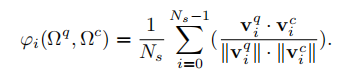
考虑到平移,最终的公式应该是:
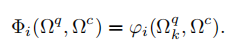
D.Consistency Verifification (一致性验证)
1)Temporal consistency check: 由于传感器的反馈在时间上是连续的,因此出现单回路闭合通常意味着相邻激光雷达扫描的高度相似性:
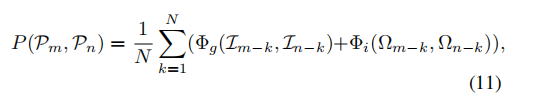
N是包含的用于时间一致性验证的帧数,这样即使是反方向的情况下也可以识别。
2) Geometrical consistency: ICP
这篇关于19、论文解读:Intensity Scan Context: Coding Intensity and Geometry Relations for Loop Closure Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





