本文主要是介绍Vision Transformer(ViT-Base-16)处理CIFAR-100模式识别任务(基于Pytorch框架),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在PyTorch框架内,执行CIFAR-100识别任务使用Vision Transformer(ViT)模型可以分为以下步骤:
- 导入必要的库。
- 加载和预处理CIFAR-100数据集。
- 定义ViT模型架构。
- 设置训练过程(包括损失函数、优化器等)。
- 训练模型。
- 测试模型性能。
示例代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torchvision.models import vit_b_16, ViT_B_16_Weights# 1. 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 2. 加载并预处理CIFAR-100数据集
transform = transforms.Compose([transforms.Resize((224, 224)), # ViT期望的输入尺寸transforms.ToTensor(),transforms.Normalize(0.5, 0.5)
])trainset = torchvision.datasets.CIFAR100(root='./data', train=True,download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,shuffle=True)testset = torchvision.datasets.CIFAR100(root='./data', train=False,download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,shuffle=False)# 3. 定义ViT模型
weights = ViT_B_16_Weights.DEFAULT
model = vit_b_16(weights=weights)
model.heads[0] = nn.Linear(model.heads[0].in_features, 100) # 修改分类头为100类# 如果有可用的GPU,则将模型转到GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)# 4. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 5. 训练模型
for epoch in range(10): # 遍历数据集多次running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = datainputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 200 == 199: # 每200个批次打印一次print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 200:.3f}')running_loss = 0.0print('Finished Training')# 6. 评估模型
correct = 0
total = 0
with torch.no_grad():for data in testloader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')在这个代码示例中,我们使用了ViT_B_16_Weights来自动获取适合ImageNet预训练的权重。然后我们修改了分类头,以适应CIFAR-100数据集的100个类别。请确保安装了最新版本的torchvision,因为早期版本可能不包含Vision Transformer模型。
ViT-B-16模型介绍
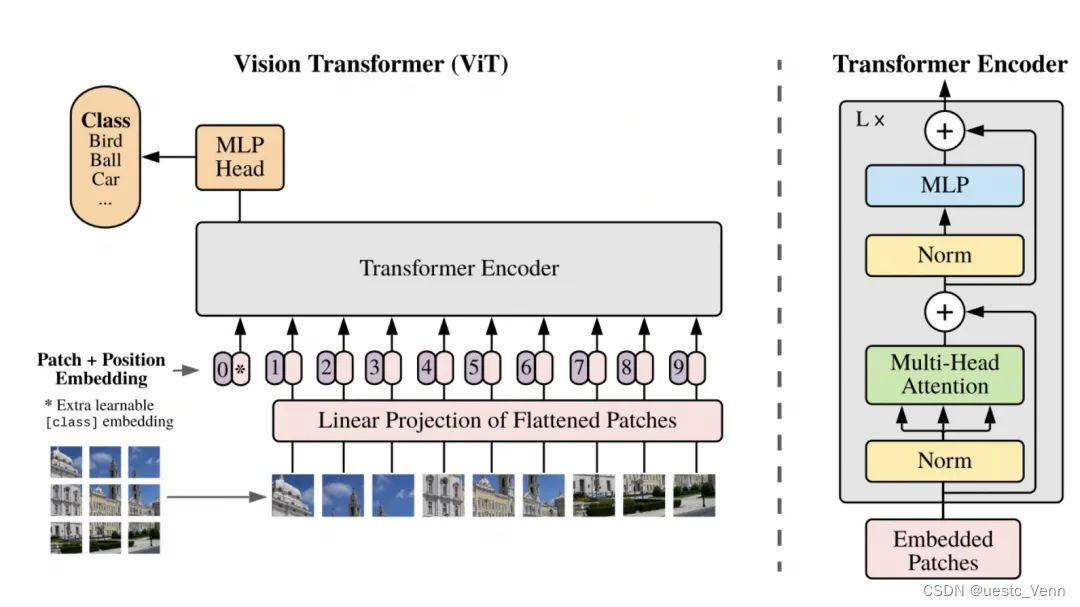
ViT-B-16是Vision Transformer(ViT)模型的一个变体,由Google在2020年提出。ViT模型是一种应用于图像识别任务的Transformer架构,它采用了在自然语言处理(NLP)中非常成功的Transformer模型,并将其调整以处理图像数据。
以下是ViT-B-16模型的一些关键特点:
Transformer 架构
ViT将图像分割为固定大小的patches(例如,16x16像素的小块),将它们线性嵌入为一维向量,并在这些向量前加上位置编码,然后将它们输入到Transformer结构中。
Transformer结构利用自注意力机制,它允许模型关注图像的不同部分以提取特征,而无需任何卷积层(全局特征)。
ViT-B-16的参数
“B”指的是“Base”模型大小,它指定了模型的宽度和深度,即Transformer的层数(encoder blocks)和每层的隐藏单元数目。
“16”指的是将图像分割为16x16像素大小的patches。
训练和数据
ViT模型通常需要大量的数据来进行训练,因为Transformer架构本身不具备卷积神经网络(CNN)的归纳偏置(inductive biases),如平移不变性和局部性。因此,ViT依赖于大量数据来学习这些特性。
ViT在大型数据集(如ImageNet或JFT-300M)上进行预训练,然后可以在较小的数据集上进行微调,例如CIFAR-100。
性能
当训练数据足够多时,ViT的性能可以与当时的最先进CNN模型相匹敌或超过它们,特别是在大规模图像识别任务中。
总的来说,ViT-B-16模型是在图像处理领域引入Transformer架构的突破性尝试,它展示了Transformer结构在处理除了文本以外的数据类型时的潜力。
在PyTorch中实现ViT-B-16模型的代码可能会涉及到使用预训练的模型,或者使用像huggingface/transformers这样的库,这些库提供了Transformer模型的预训练版本和用于微调的工具。
这篇关于Vision Transformer(ViT-Base-16)处理CIFAR-100模式识别任务(基于Pytorch框架)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







