本文主要是介绍智能边缘小站 CloudPond(低延迟、高带宽和更好的数据隐私保护),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
智能边缘小站 CloudPond(低延迟、高带宽和更好的数据隐私保护)
边缘小站的主要功能是管理用户在线下部署的整机柜设施,一个边缘小站关联一个华为云指定的区域和一个用户指定的场地,相关的资源运行状况监控等。
边缘计算
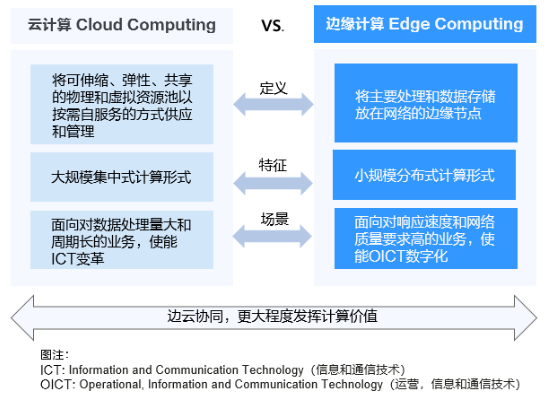
迈入5G和AI时代,新型业务如增强现实AR、虚拟现实VR、互动直播、自动驾驶、智能制造等应运而生。以上这些业务场景对时延和网络带宽有着强烈诉求,而在传统的集中式云计算场景中,所有数据都集中存储在大型数据中心。由于地理位置和网络传输的限制,无法满足新型业务的低时延、高带宽等要求。
- 网络高时延:传统云计算无法即时处理和分析新型业务产生的数据,导致应用终端获得的响应慢,体验差。
- 带宽高成本:新型业务的应用终端产生的数据传回云端将消耗更高的网络带宽,导致服务厂商需要支付高昂的网络成本。
- 数据合规性:新型业务数据存储在云端,无法满足企业对敏感数据本地化存储的要求,直接影响企业数据上云的策略。
面对传统集中式云计算的固有局限性,边缘计算成为应对新型业务和数据合规业务的较好选择。边缘计算通过在靠近终端应用的位置建立站点,最大限度的将集中式云计算的能力延伸到边缘侧,有效解决以上的时延和带宽问题。
产品优势
边云同构,体验一致
一张分布式网络:边云分布式网络,无缝连接企业和中心云的内网。
CloudPond所在的边缘可用区和中心云的通用可用区通过边缘网关进行连接,共享同一虚拟私有云VPC。
丰富的云服务按需开通
借助CloudPond,您可以按需、在线、快速开通或同步中心云最新的云服务,如CVR、MRS、DWS等,“零”时差满足企业核心业务对云服务创新能力的要求。
数据本地安全存储和处理
CloudPond向用户交付定制化整机柜,为用户在本地提供华为云各类服务。借助CloudPond,您可以安全地存储和处理需要在本地保留的数据,满足监管需求。同时,CloudPond可与用户本地其他资源进行内网连接,数据互联互通更便利。
完全托管的基础设施
CloudPond完全由华为云管理和支持,包括交付、安装、维护和升级等。使用CloudPond,您可以减少管理IT基础设施所需的时间、资源、运营风险和维护停机时间。
应用场景
本地低时延
- 提供多种标准化的公有云服务,可支持多类型业务创新。
- 用户业务数据在本地运行,可与其他本地设备/应用进行内网交互。
- 华为云代维基础设施,方便用户专注上层业务。
数据本地留存
- 华为云服务本地化部署,用户业务数据保留在本地。
- 整机柜标准化部署,云服务按需部署、开通、付费。
- 本地网关直连用户现有内网IT的设备或系统,提供多种迁移方式,支持传统业务逐步迁移上云。
集团分支管理
- 用户总部IT团队统一管控多个分支机构的云资源,分支IT团队运维本地机房环境,华为云负责运维边缘基础设施和相关云服务。
- 分支机构云服务的功能和性能规格与总部保持一致,各个分支机构的云服务部署方式和使用体验相同。
- 中心云和CloudPond多维度协同,VPC内网互通,使得用户业务数据能够在总部和分支之间快速流转。
SaaS应用分发
- CloudPond支持的云服务形态与中心云保持一致,功能和性能指标标准化,SaaS应用供应商可在云端测试完成后在边缘直接部署。
- 中心云和CloudPond多维度协同,VPC内网互通,SaaS应用可以将应用管理能力部署在云端,用户业务数据存放在本地CloudPond上,并统一管理多个地域的SaaS应用。
,SaaS应用可以将应用管理能力部署在云端,用户业务数据存放在本地CloudPond上,并统一管理多个地域的SaaS应用。 - 华为云代维基础设施,并支持其规模无缝扩展。
这篇关于智能边缘小站 CloudPond(低延迟、高带宽和更好的数据隐私保护)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







