本文主要是介绍PTS 3.0:开启智能化的压测瓶颈分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:拂衣
PTS 简介
性能测试 PTS(Performance Testing Service)是阿里云上一款简单易用,具备强大的分布式压测能力的 SaaS 压测平台。PTS 可以模拟复杂的业务场景,并快速精准地调度不同规模的流量,同时提供压测过程中多维度的监控指标和日志记录。用户无需准备资源,即可按需发起压测任务,监控压测指标,获取压测报告,进而能够高效率、全方位地验证业务站点的性能、容量和稳定性。
阿里云压测平台演进之路
阿里云压测平台 PTS,由阿里云可观测团队倾心打造,应双十一稳定性和容量规划的需求背景而诞生,随高可用、中间件上云而对外输出产品能力。整体演进分以下 5 个阶段:

2010 年-阿里巴巴容量规划平台
在此之前,阿里巴巴大促活动的容量规划主要通过人工估算的方式来完成的。各个系统的负责同学聚在一起开个会,将信息汇总到一起,按专家经验就把容量规划的机器预算给定下来了。而且,各个系统通常都留了比较大的机器冗余,即使估算的不准也不会造成大的业务影响。
此时,容量计算的公式被第一次提了出来,通过目标容量/单机容量上限,得到各应用需要的机器资源数,再加上一定比例的冗余量,就是大促时需要的总资源数。
在阿里容量规划平台的 1.0 版本当中,通过对各业务系统线下环境单机压测,来获取各服务的单机容量上限,完成了从人工容量规划到系统化容量规划的过度。
2013 年-阿里巴巴全链路压测-流量平台
随着双十一业务规模快速拉升,分布式系统架构的技术组件越来越多,应用的上下游依赖关系也越来越复杂。双十一当天 0 点到来的时候,从 CDN 到接入层、前端应用、后端服务、缓存、存储、中间件整个链路上都面临着巨大流量,这个时候应用的服务状态除了受自身影响,还会受到依赖环境影响,并且影响面会继续传递到上游,哪怕一个环节出现一点误差,误差在上下游经过几层累积后会造成什么影响谁都无法确定。由于各层依赖的不确定性,无法再基于单业务容量上限规划全局容量。
所以我们建立了全链路压测机制,通过全面仿真双十一业务流量,我们的系统能够提前经历几次“双十一”,让容量的不确定性问题提前暴露并解决。
流量平台是全链路压测的 CPU,能够模拟出双十一上亿用户的仿真流量,制造每秒数十万次用户行为的超大规模流量。主要由两大部件构成:1)全链路压测操控中心,进行压测的配置和操控、数据的监控以及对压测引擎集群的管控;2)压测引擎,由控制台统一管控,部署在外网 cdn 集群,进行登陆、session 同步,发送各种协议的压测请求、状态统计。
2013 年之后,全链路压测成为双十一、双十二等大促备战最重要的稳定性验证工具,随着业务的发展不断进化,持续发挥着不可替代的作用。
2018 年-阿里云 PTS 1.0:阿里云压测产品发布
在云计算的浪潮下,越来越多的用户开始基于阿里云上的基础产品设计自己的架构。在 2018 年,我们正式发布了阿里云压测产品:PTS,将阿里巴巴集团压测平台的技术架构迁移至阿里云,对外部用户提供 SaaS 化的压测产品。PTS 1.0 核心能力包括:
- 无限接近真实的流量:业务场景中无论是高并发要求还是发起端的分散度,覆盖三四线城市主要运营商的节点广度都能做到真正模拟用户行为,客户端到服务端间复杂的网络瓶颈也能暴露无遗,压测结果更加全面和真实可信。
- 操作简单易上手:不需要专门的性能测试团队或者测试背景的积累,完全面向开发的交互设计,开发自测试,投入产出比高。
- 多维度施压:支持并发和 RPS 双维度。
- 压力动态调整:支持压测能力动态修改。
2020 年-阿里云 PTS 2.0:施压能力、产品体验再升级
随着 PTS 1.0 用户规模的不断扩大,越来越多的用户在不同的业务场景对 PTS 提出了支持超高并发的压测需求,甚至超过了集团双十一的并发量级,典型场景如:春晚红包压测、保险开门红压测、考试报名压测等。PTS 2.0 通过优化资源调度和施压引擎性能,提供了百万并发、千万 QPS 的压测能力,连续支撑了多次春晚红包活动等顶级流量压测。
同时,PTS 2.0 升级了流量录制和多协议场景化功能,提升了产品体验:
- 流量录制功能:允许录制实际用户操作,以便创建真实的用户行为模拟。
- 多协议支持:对流媒体、MQTT、RocketMQ、Kafka、JDBC、Redis、Dubbo 等协议支持白屏化压测配置,扩宽测试场景。
2024 年-阿里云 PTS 3.0:可观测、智能化、开源加持的下一代压测平台
在 PTS 1.0 和 2.0 的持续演进中,PTS 在产品体验、施压能力都得到了大幅提升。要做一轮完整的容量规划,用户还需要解决以下问题:
- 评估压测的影响范围,确定压测流量会经过哪些服务端应用,如何准确地掌控压测的爆炸半径。
- 洞察压测和业务系统的全局监控指标,分析当前系统容量水位。
- 如果压测结果不满足预期,需要出分析整个系统的性能瓶颈点。
这些问题是每个测试团队都需要面对的,在云原生和可观测技术的发展下,如何更好的解决这些问题?
针对以上挑战,我们提出性能压测可观测化能力,分别针对以上问题提出压测链路可观测:
首先,在实施压测前,先执行一次拨测,通过拨测发起一次请求来构建整个压测链路拓扑,通过链路拓扑全局来看整个压测的影响范围。
其次,性能指标可观测,获取压测链路所涉及的监控指标,自动生成压测及各业务各实例水位大盘,边压边观测。
再次,聚合压测请求各指标和调用链,通过 调用链分析和智能化分析,实现性能瓶颈可观测。
最后,通过前面提到的压测指标和各服务实例资源水位,进行梯度压测评估验证系统服务容量。构建性能压测可观测,实现从压测到数据分析。在此之上,我们构建了可观测加持下的下一代阿里云压测平台 PTS 3.0 ,通过打通阿里云全栈可观测生态,并集成云原生大模型和多模型智能归因算法,给用户提供更专业、结论更清晰、更有洞察力的压测报告,辅助用户在 PTS 实现压测瓶颈定位和根因分析。
同时 PTS 3.0 全面兼容开源 JMeter 压测工具,只需 JMeter 脚本上传到 PTS,即可自动补全依赖插件,一键发起压测。
PTS 3.0 核心功能
自动感知压测应用拓扑
PTS 与阿里云可观测链路 OpenTelemetry 打通,在发起压测之前,会通过拨测能力进行压测脚本测试和链路探测,能自动准确识别请求链路所经过的组件,根据拨测请求建立链路拓扑图,不会涉及正常请求所经过的链路,这样我们就可以很直观的感知压测所经过的链路,明确压测涉及的应用范围和架构拓扑。
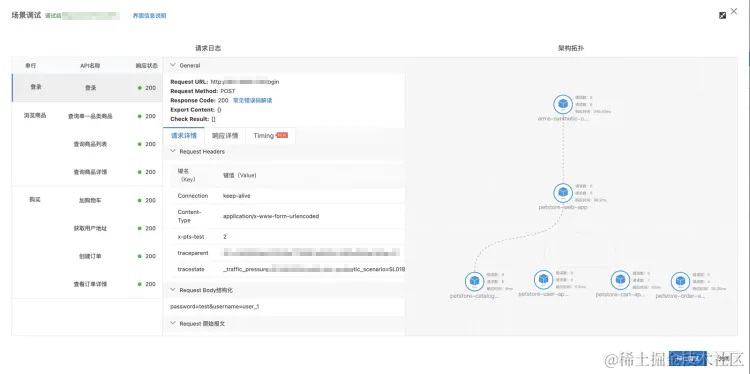
应用瓶颈分析
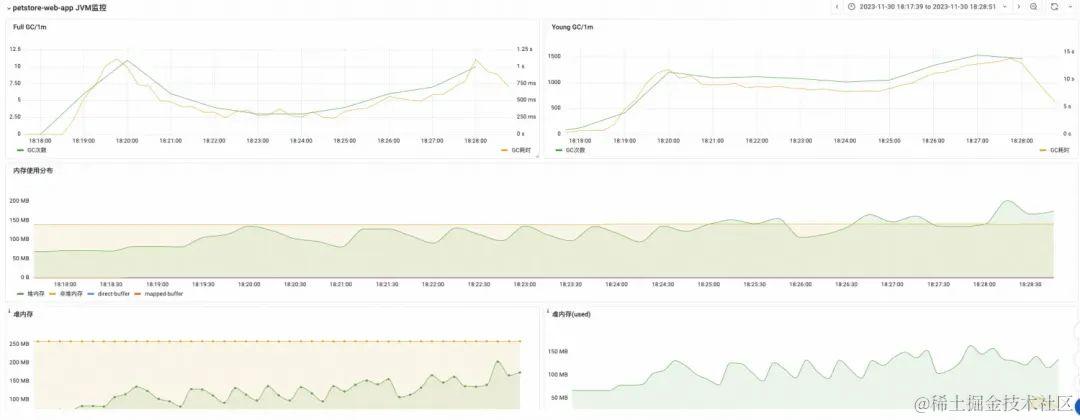
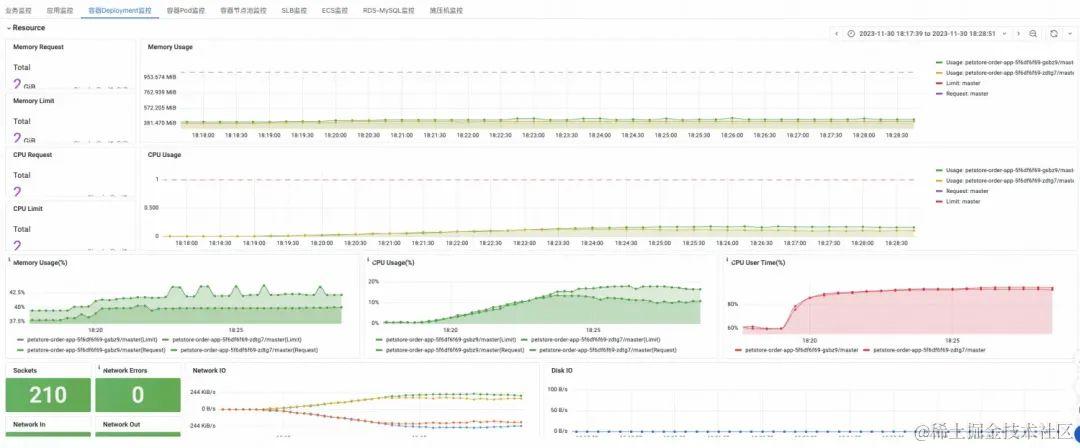
压测性能瓶颈往往出现在服务端应用层,最通过压测报告-全局监控-应用监控,可以观测到压测时段各服务端应用的副本数,以及 CPU、内存、磁盘等资源水位。配合错误请求数、数据库错慢调用次数、FullGC 次数等指标,可以判断出哪些应用负载较高,需要优化性能或扩容。

对 JVM 内存泄漏等场景,可以通过 JVM 监控判断出问题现象,并配合 Profiling 分析根因。
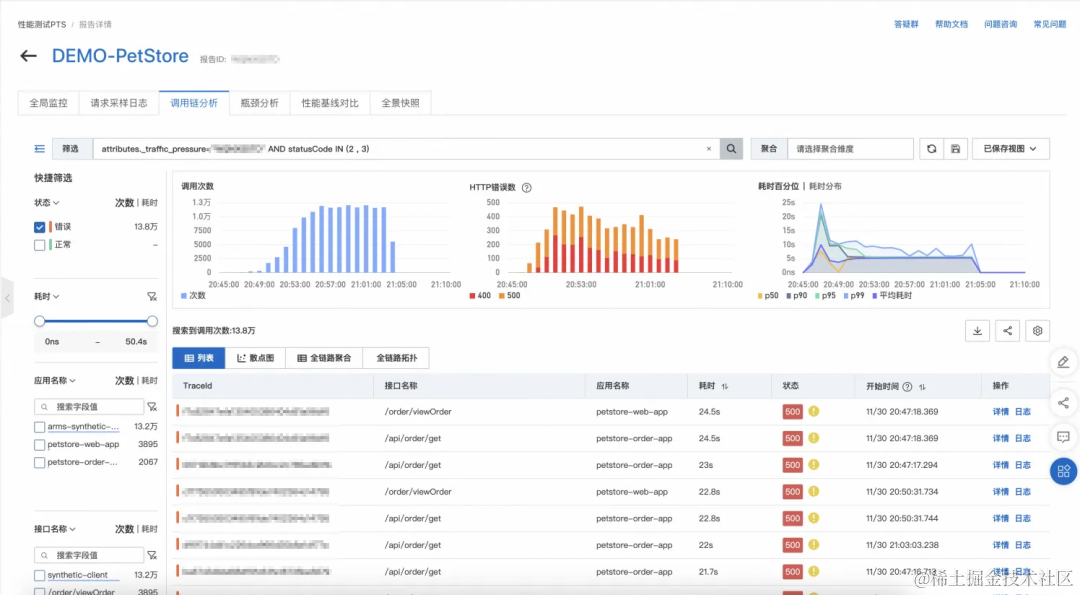
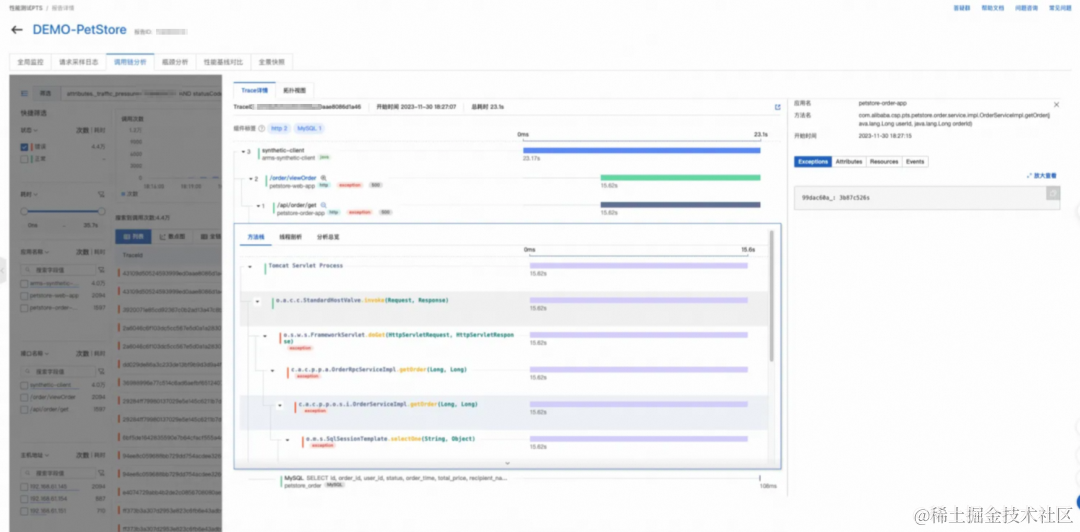
错慢请求根因分析
定界瓶颈点在应用层,需要进一步分析根因时,PTS 可以打通可观测链路 OpenTelemetry,获取到本次压测的错慢调用链,包含从施压端到数据库层的完整链路。通过下钻分析,可以定位到请求在调用链的哪里出现了错慢现象,并可以通过堆栈分析,判断出错慢的原因。
云资源瓶颈分析
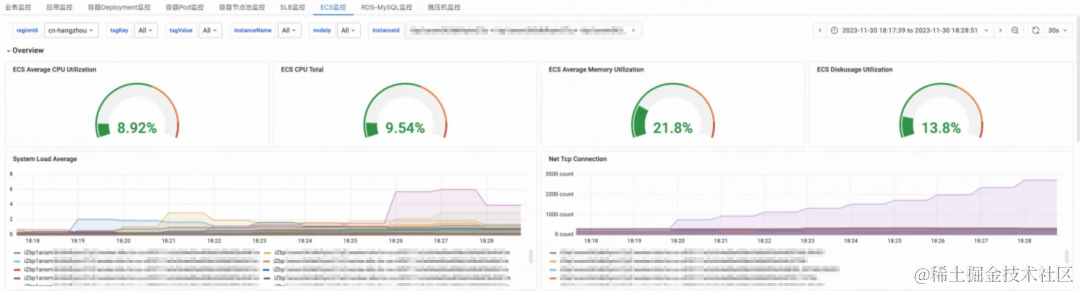
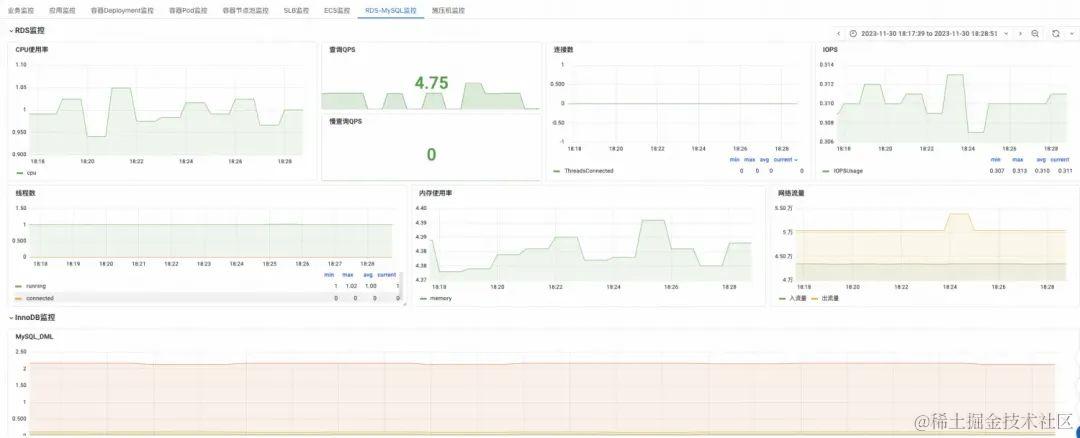
在云原生的架构体系中,系统接入层、数据库、中间件、容器等基础资源都天然在云上,通过打通阿里云可观测监控 Prometheus,可以获取到负载均衡 SLB、RDS 数据库、ECS、容器等基础云资源的监控指标和大盘,辅助用户分析云资源是否存在瓶颈。
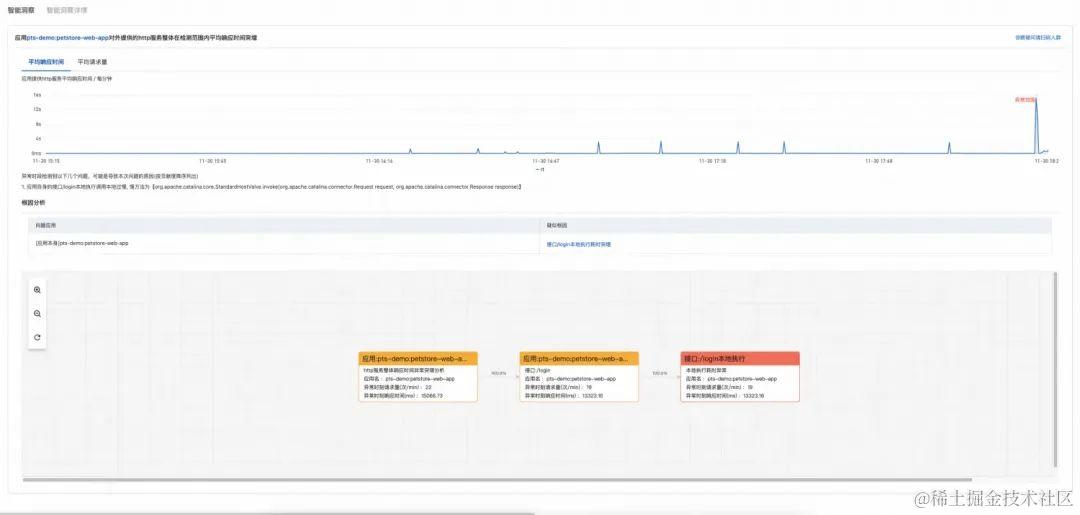
智能洞察
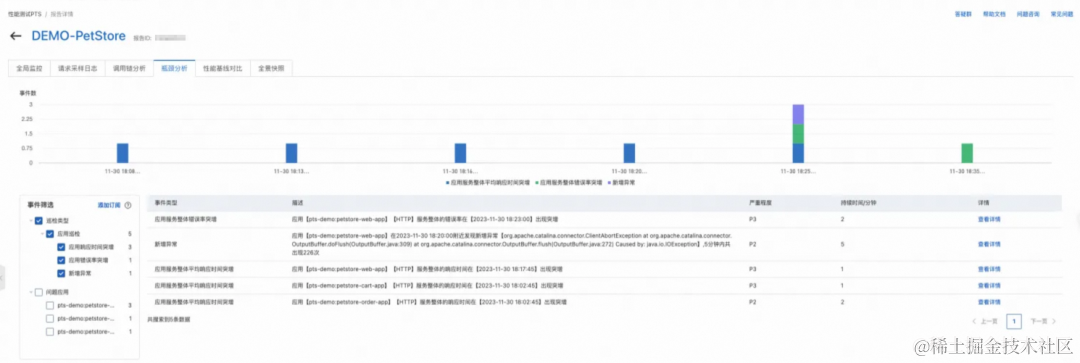
性能测试 PTS 3.0 通过异常区间检测算法,自动发现应用层监控指标的异动,并通过多模型的智能归因算法,推理出异常现象的根因。
总结
PTS 3.0 以瓶颈分析为核心场景,构建出可观测、智能化、开源加持的下一代压测平台。目前 PTS 3.0 已全面上线,新版控制台地址:https://ptsnext.console.aliyun.com/
PTS 2.0 用户可以通过概览页右上角的“体验 PTS 3.0”按钮,一键跳转新版,新版 PTS 和 JMeter 的场景与报告和 PTS 2.0 完全兼容。

为了更好的满足中小企业上云验证、容量规划等性能测试需求,目前性能测试 PTS 推出 59.9 元基础版特惠资源包。
3 万 VUM 额度,最高 5 万虚拟用户规模并发量,让性能测试更具性价比。

点击此处,立即查看详情!
这篇关于PTS 3.0:开启智能化的压测瓶颈分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





