本文主要是介绍【办公类-21-05】20240227单个word按“段落数”拆分多个Word(成果汇编 只有段落文字 1拆5),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作品展示
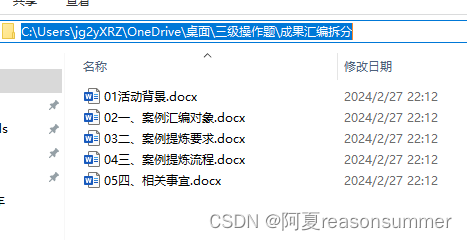
背景需求
前文对一套带有段落文字和表格的word进行13份拆分
【办公类-21-04】20240227单个word按“段落数”拆分多个Word(三级育婴师操作参考题目1拆13份)-CSDN博客文章浏览阅读293次,点赞8次,收藏3次。【办公类-21-04】20240227单个word按“段落数”拆分多个Word(三级育婴师操作参考题目1拆13份)https://blog.csdn.net/reasonsummer/article/details/136331041现在我随便找一份docx文件(全部都是段落文字,没有表格),
试试没表格干扰,是否直接读取段落就可以将加粗部分的文字另存多份
素材准备:
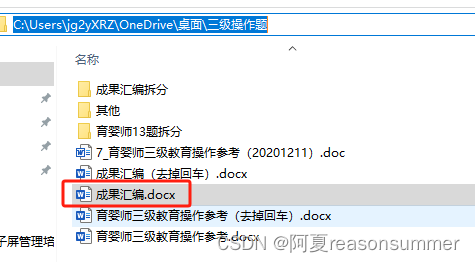
有几个加粗标题(不能是一级标题这种,一定清除格式,加粗)

错误的
# https://blog.csdn.net/lau_jw/article/details/114383781'''成果汇编word题目拆分成多个表格(根据标题(加粗)所在行数拆分-没有表格,只有段落文字)
作者:阿夏
时间:2024年2月27日
'''from docx import Document
from openpyxl import load_workbook
import glob
import re,osprint('----1、word数据清洗------')
a='成果汇编'path = r"C:\Users\jg2yXRZ\OneDrive\桌面\三级操作题"
file=path + r'\{}.docx'.format(a) # 必须是docx
print(file)
# C:\Users\jg2yXRZ\OneDrive\桌面\三级操作题\电子屏安全管理制度(样本)2.docx# 提取四个加粗标题所在的行数 # 参考https://www.shouxicto.com/article/96876.html
doc= Document(file)# 遍历每个段落并判断是否为空白行,如果有空白行,就删除
for paragraph in doc.paragraphs:if not paragraph.text.strip():# 如果是空白行则将其从文档中移除p = paragraph._elementp.getparent().remove(p) doc.save(path + r'\{}(去掉回车).docx'.format(a))print('----2、读取word里面标题加粗段落的行数------')filename=path + r'\{}(去掉回车).docx'.format(a)# 打开Word文档
doc = Document(filename)d=len(doc.paragraphs)
print(d)
# docx没有去掉空行前,一共有258段文字
# docx去掉空行后,一共有244段文字h=[]
s=[]
# 遍历文档中的段落
for i, paragraph in enumerate(doc.paragraphs):if paragraph.runs:# 检查段落中的所有运行对象for run in paragraph.runs:if run.bold:# 如果运行对象的文字为加粗,则打印段落索引# print("段落", i, "的文字被加粗了")h.append(i)# 提取每一份的加粗标题t=doc.paragraphs[i].text # print(t)s.append(t)
s=list(set(s))
s.sort()
# print(s)
# ['3.1.1 运用发育诊断法对2岁婴儿的以不同步子行走能力进行测试', '3.1.2 为2岁婴儿编制规范、适宜的个别化游戏活动计划(5分钟)', '3.1.3 设计生活中婴儿动手自理的活动(5分钟)', '3.1.4 六个月以内
# 的婴儿的精细动作的日常练习活动设计(5分钟)', '3.1.5 列举两种感统练习器械,并简述其活动功能(5分钟)', '3.2.1 请阐述对婴儿语言发展水平的观察与记录方法(5分钟)', '3.2.2 如何制定婴幼儿个别化
# 语言培养计划(5分钟)', '3.2.3 设计一份记录表格,观察一个6个月左右的宝宝寻找不同声源的感知练习过程(5分钟)', '3.2.4 设计一个观察表,观察并调整婴儿在视动协调方面的练习(5分钟)', '3.2.5 设
# 计一个观察表,记录孩子可能发生的行为(5分钟)', '3.3.1 如何对待任性的孩子(5分钟)', '3.3.2 如何对待爱哭的孩子(5
# print(len(s))
# 13h=list(set(h))
h.sort()
j=h[1:]
j.append(d)print(h)
print(len(h))
print(j)
print(len(j))
# # 去掉空行前
# # [1, 25, 48, 64, 77, 95, 117, 136, 158, 179, 200, 218, 238]
# # 13
# # [25, 48, 64, 77, 95, 117, 136, 158, 179, 200, 218, 238, 258]
# # 13
# # 去掉空行后
# # [1, 23, 45, 60, 72, 89, 110, 127, 148, 168, 188, 205, 224]
# # 13
# # [23, 45, 60, 72, 89, 110, 127, 148, 168, 188, 205, 224, 244]print('----3、读取word里面标题加粗段落的行数+表格占的段落数------')
# 拆分docx(读取加粗的行,这些行还要加上表格的行数)
# 13张表格里面分别有几个表格# bg=[2,1,0,1,1,1,1,1,1,1,0,0,0]# # 第一张表是原来的段落数,所以就是0
# bg.insert(0,0)
# # print(bg)# # 数字累加
# o = []
# sum = 0
# for num in bg:
# sum += num
# o.append(sum)
# print(o)
# # [0, 2, 3, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10]
# # # # 没有空行的内容print('----3、读取word里面标题加粗段落的行数+表格占的段落数------')
# 拆分docx(读取加粗的行,这些行还要加上表格的行数)
# 13张表格里面分别有几个表格imagePath1=path+r'\{}拆分'.format(a)
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在os.makedirs(imagePath1) # 若图片文件夹不存在就创建# for x in range(len(s)):# 获取第一页的段落和表格
# a=int(j[x]+o[x])
for x in range(len(s)):doc = Document(filename)first_page_paragraphs = []first_page_tables = []for element in doc.element.body:if element.tag.endswith(('}p', '}tbl')):if element.getparent().index(element) >int(j[x]) :# if element.getparent().index(element) >int(j[x]+o[x]) :if element.tag.endswith('p'):first_page_paragraphs.append(element)else:first_page_tables.append(element)if element.getparent().index(element)<int(h[x]):# if element.getparent().index(element)<int(h[x]+o[x]):if element.tag.endswith('p'):first_page_paragraphs.append(element)else:first_page_tables.append(element)# print(int(j[x]+o[x]))# print(int(h[x]+o[x]))# 删除第一页的段落和表格for paragraph in first_page_paragraphs:p = paragraph.getparent()p.remove(paragraph)for table in first_page_tables:t = table.getparent()t.remove(table)# # 保存修改后的文档为新文件# doc.save(path+r'01.docx')doc.save(imagePath1+r'\{} {}.docx'.format('%02d'%x,s[x]))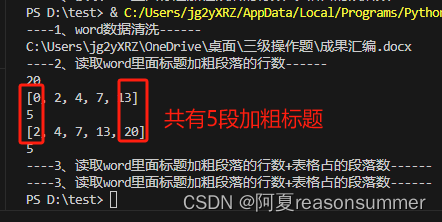

结果显示及调整

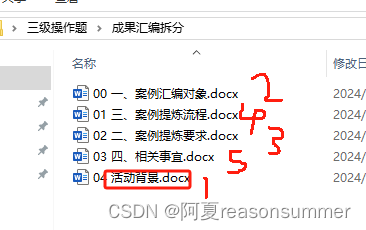
1、结果显示题目与数字顺序不符合
1、解决思路


2、内容多一行

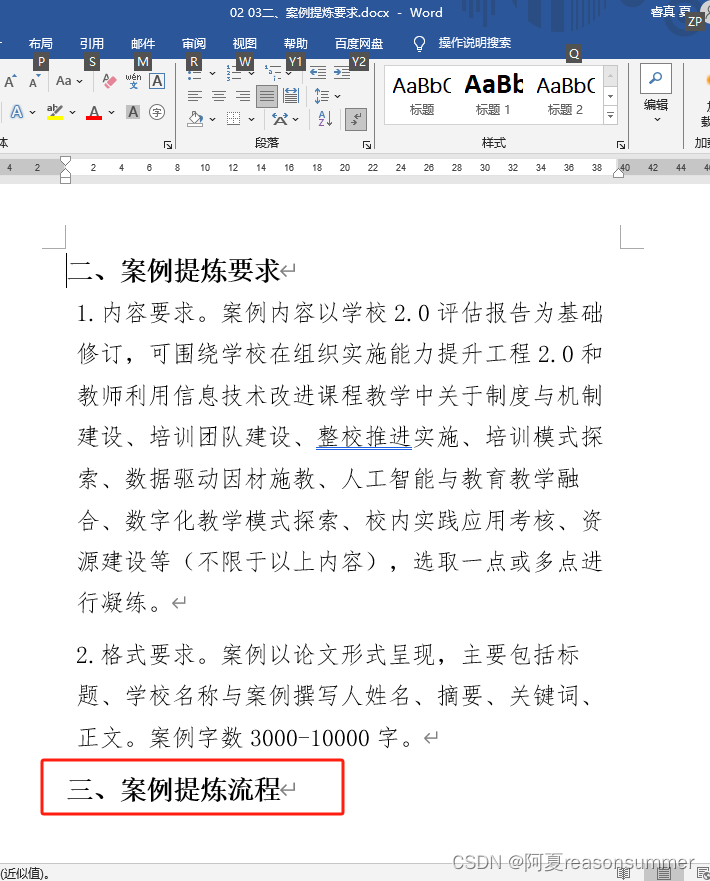 2、解决思路
2、解决思路
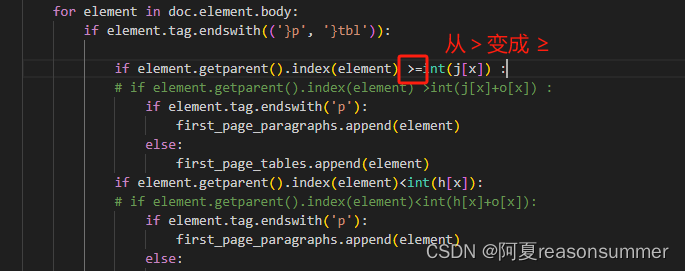

正确代码全部
# https://blog.csdn.net/lau_jw/article/details/114383781'''成果汇编word题目拆分成多个表格(根据标题(加粗)所在行数拆分-没有表格,只有段落文字)
作者:阿夏
时间:2024年2月27日
'''from docx import Document
from openpyxl import load_workbook
import glob
import re,osprint('----1、word数据清洗------')
a='成果汇编'path = r"C:\Users\jg2yXRZ\OneDrive\桌面\三级操作题"
file=path + r'\{}.docx'.format(a) # 必须是docx
print(file)
# C:\Users\jg2yXRZ\OneDrive\桌面\三级操作题\电子屏安全管理制度(样本)2.docx# 提取四个加粗标题所在的行数 # 参考https://www.shouxicto.com/article/96876.html
doc= Document(file)# 遍历每个段落并判断是否为空白行,如果有空白行,就删除
for paragraph in doc.paragraphs:if not paragraph.text.strip():# 如果是空白行则将其从文档中移除p = paragraph._elementp.getparent().remove(p) doc.save(path + r'\{}(去掉回车).docx'.format(a))print('----2、读取word里面标题加粗段落的行数------')filename=path + r'\{}(去掉回车).docx'.format(a)# 打开Word文档
doc = Document(filename)d=len(doc.paragraphs)
print(d)
# docx没有去掉空行前,一共有258段文字
# docx去掉空行后,一共有244段文字h=[]
s=[]
n=1
# 遍历文档中的段落
for i, paragraph in enumerate(doc.paragraphs):if paragraph.runs:# 检查段落中的所有运行对象for run in paragraph.runs:if run.bold:# 如果运行对象的文字为加粗,则打印段落索引# print("段落", i, "的文字被加粗了")h.append(i)# 提取每一份的加粗标题t=doc.paragraphs[i].text print(t)b=str('%02d'%n)+ts.append(b)# 没有按照顺序排列# ['一、案例汇编对象', '三、案例提炼流程', '二、案例提炼要求', '四、相关事宜', '活动背景']# 所以加了一个数字序号# ['01活动背景', '02一、案例汇编对象', '03二、案例提炼要求', '04三、案例提炼流程', '05四、相关事宜']n+=1
s=list(set(s))
s.sort()
print(s)
# ['3.1.1 运用发育诊断法对2岁婴儿的以不同步子行走能力进行测试', '3.1.2 为2岁婴儿编制规范、适宜的个别化游戏活动计划(5分钟)', '3.1.3 设计生活中婴儿动手自理的活动(5分钟)', '3.1.4 六个月以内
# 的婴儿的精细动作的日常练习活动设计(5分钟)', '3.1.5 列举两种感统练习器械,并简述其活动功能(5分钟)', '3.2.1 请阐述对婴儿语言发展水平的观察与记录方法(5分钟)', '3.2.2 如何制定婴幼儿个别化
# 语言培养计划(5分钟)', '3.2.3 设计一份记录表格,观察一个6个月左右的宝宝寻找不同声源的感知练习过程(5分钟)', '3.2.4 设计一个观察表,观察并调整婴儿在视动协调方面的练习(5分钟)', '3.2.5 设
# 计一个观察表,记录孩子可能发生的行为(5分钟)', '3.3.1 如何对待任性的孩子(5分钟)', '3.3.2 如何对待爱哭的孩子(5
# print(len(s))
# 13h=list(set(h))
h.sort()
j=h[1:]
j.append(d)print(h)
print(len(h))
print(j)
print(len(j))
# # 去掉空行前
# # [1, 25, 48, 64, 77, 95, 117, 136, 158, 179, 200, 218, 238]
# # 13
# # [25, 48, 64, 77, 95, 117, 136, 158, 179, 200, 218, 238, 258]
# # 13
# # 去掉空行后
# # [1, 23, 45, 60, 72, 89, 110, 127, 148, 168, 188, 205, 224]
# # 13
# # [23, 45, 60, 72, 89, 110, 127, 148, 168, 188, 205, 224, 244]print('----3、读取word里面标题加粗段落的行数+表格占的段落数------')
# 拆分docx(读取加粗的行,这些行还要加上表格的行数)
# 13张表格里面分别有几个表格# bg=[2,1,0,1,1,1,1,1,1,1,0,0,0]# # 第一张表是原来的段落数,所以就是0
# bg.insert(0,0)
# # print(bg)# # 数字累加
# o = []
# sum = 0
# for num in bg:
# sum += num
# o.append(sum)
# print(o)
# # [0, 2, 3, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10]
# # # # 没有空行的内容print('----3、读取word里面标题加粗段落的行数+表格占的段落数------')
# 拆分docx(读取加粗的行,这些行还要加上表格的行数)
# 13张表格里面分别有几个表格imagePath1=path+r'\{}拆分'.format(a)
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在os.makedirs(imagePath1) # 若图片文件夹不存在就创建# for x in range(len(s)):# 获取第一页的段落和表格
# a=int(j[x]+o[x])
for x in range(len(s)):doc = Document(filename)first_page_paragraphs = []first_page_tables = []for element in doc.element.body:if element.tag.endswith(('}p', '}tbl')):if element.getparent().index(element) >=int(j[x]) :# if element.getparent().index(element) >int(j[x]+o[x]) :if element.tag.endswith('p'):first_page_paragraphs.append(element)else:first_page_tables.append(element)if element.getparent().index(element)<int(h[x]):# if element.getparent().index(element)<int(h[x]+o[x]):if element.tag.endswith('p'):first_page_paragraphs.append(element)else:first_page_tables.append(element)# print(int(j[x]+o[x]))# print(int(h[x]+o[x]))# 删除第一页的段落和表格for paragraph in first_page_paragraphs:p = paragraph.getparent()p.remove(paragraph)for table in first_page_tables:t = table.getparent()t.remove(table)# # 保存修改后的文档为新文件# doc.save(path+r'01.docx')doc.save(imagePath1+r'\{}.docx'.format(s[x]))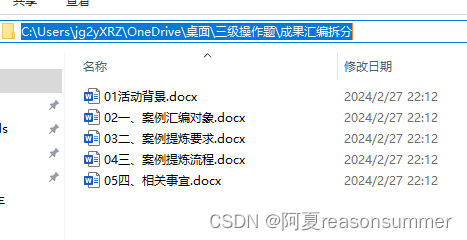
这篇关于【办公类-21-05】20240227单个word按“段落数”拆分多个Word(成果汇编 只有段落文字 1拆5)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





