本文主要是介绍分布式存储 ZBS 的 RoCE 技术支持与大数据应用场景性能评测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:深耕行业的 SmartX 金融团队 闫海涛
在《解决 SAN 交换机“卡脖子”并升级存储架构?一文解析 RoCE 与相关存储方案趋势》文章中,我们分析了如何利用支持 RoCE 技术的分布式存储,同步实现 IT 基础架构的信创转型与架构升级,并简单介绍了 SmartX 分布式存储 ZBS 对 RoCE 的支持能力。
本文,我们将进一步解读 ZBS 如何支持 RoCE,同时为读者提供启用 NVMe over RDMA(RoCE)接入协议的 ZBS 在实验室环境和业务场景下的真实性能数据,并与 iSCSI、NVMe over TCP 协议场景进行对比,帮助读者直观了解 RoCE 技术的成熟性与生产环境可应用性。
ZBS 如何支持 RoCE
SmartX 分布式存储 ZBS 提供 2 种存算分离架构下的数据接入协议,分别是 iSCSI 和 NVMe-oF。其中,为了满足不同应用对于性能和时延的不同需求,ZBS 在 NVMe-oF 的实现上选择支持 NVMe over RDMA(RoCEv2)和 NVMe over TCP。这两个形态区别仅体现在外部客户端使用哪种协议接入 Access,在元数据管理上并没有区别。
NVMe-oF 协议本身与 iSCSI 协议有很多相似的地方,例如客户端标识为 initiator 端,服务端为 Target 端,NVMe-oF 协议中使用与 iSCSI IQN 近似的 NQN 来作为协议通讯双方的标识等。同时,NVMe-oF 定义了 Subsystem(子系统,相当于 SCSI 体系下的 Target)和 Namespace(命名空间,类似于 SCSI 体系下的 LUN)专有标准。
相比于 iSCSI 通过 initiator + Target 的数据链路控制,NVMe-oF 可以支持 initiator + Namespace 这样更小的链路控制粒度。NVMe-oF 在路径策略选择上(协议原生支持 Multipath)是通过 ANA(Asymmetric Namespace Access)机制指定 Target 链路优先级,再由客户端结合优先级与自身的链路状态探测结果选择 I/O 具体路径。
ZBS 会将所有的可用链路设置为 OP(最优链路)和 Non-OP(次优链路)两种状态,其他状态为发生异常或变化时由 Driver 自动标记。对于每个 initiator + Namespace 的组合,仅返回 1 个最优接入点和 2 个次优接入点。在最优接入点可用时,客户端将仅通过最优接入点访问数据,在异常时选择 2 个次优接入点中的一个进行访问(出于简化安全性处理的考虑,部署时会要求客户端配置为 AB 模式,即使 2 个次优接入点是等价的,也不会进入 AA 模式,同时从两个接入点中下发 I/O)。这样既可保持各个接入点的负载基本均衡,同时又尽可能发挥多个接入点的处理能力。

NVMe-oF 接入架构
欲深入了解 ZBS 中 iSCSI 和 NVMe-oF 的支持设计,请阅读:分布式块存储 ZBS 的自主研发之旅|接入协议之 NVMe-oF。
另外,由于 NVMe-oF 需要工作在无损网络环境中以保证最佳性能,这要求以太网交换机需支持网络拥塞控制功能 ECN,目前 ZBS 支持 L3 DSCP 的 PFC 流控和 Global Pause 流控两种主流模式。我们也基于 ZBS 进行了信创交换机 RDMA 打流测试,测试详情可阅读往期文章《一文了解 SmartX 产品信创硬件选配最佳实践》了解。

NVMe over RoCE vs. NVMe over TCP vs. iSCSI:启用不同存储协议的 ZBS 性能表现
实验室性能测试
我们在相同的测试环境和测试方法下,分别使用不同的接入协议(iSCSI、NVMe over TCP 和 NVMe over RDMA)进行 ZBS 性能测试。结果显示,使用 NVMe over RDMA 作为接入协议,可以取得更高的 I/O 性能输出,其表现为更高的随机 IOPS 和顺序带宽,以及更低的延时表现。欲了解详细测试过程,请阅读:分布式块存储 ZBS 的自主研发之旅|接入协议之 NVMe-oF。

集群性能测试结果
业务场景性能测试
测试背景
某金融客户基于服务器和本地硬盘的方式组建大数据平台,伴随业务的增长,I/O 性能逐渐显现不足。客户过往虽然通过扩容服务器节点的方式来分摊 I/O 负载,以达到提升性能的目的,但该种方式也引起了额外的资源(扩容节点连带的计算资源)投入。借着机房更换的契机,客户希望通过存算分离的架构方案(ZBS),同时实现存储性能提升和大数据平台搬迁至新机房的两个目标。
对于存算分离架构,客户针对 iSCSI 和 NVMe over RDMA(RoCE)两种协议进行了业务场景下的性能测试,并与生产环境进行对比。
测试架构
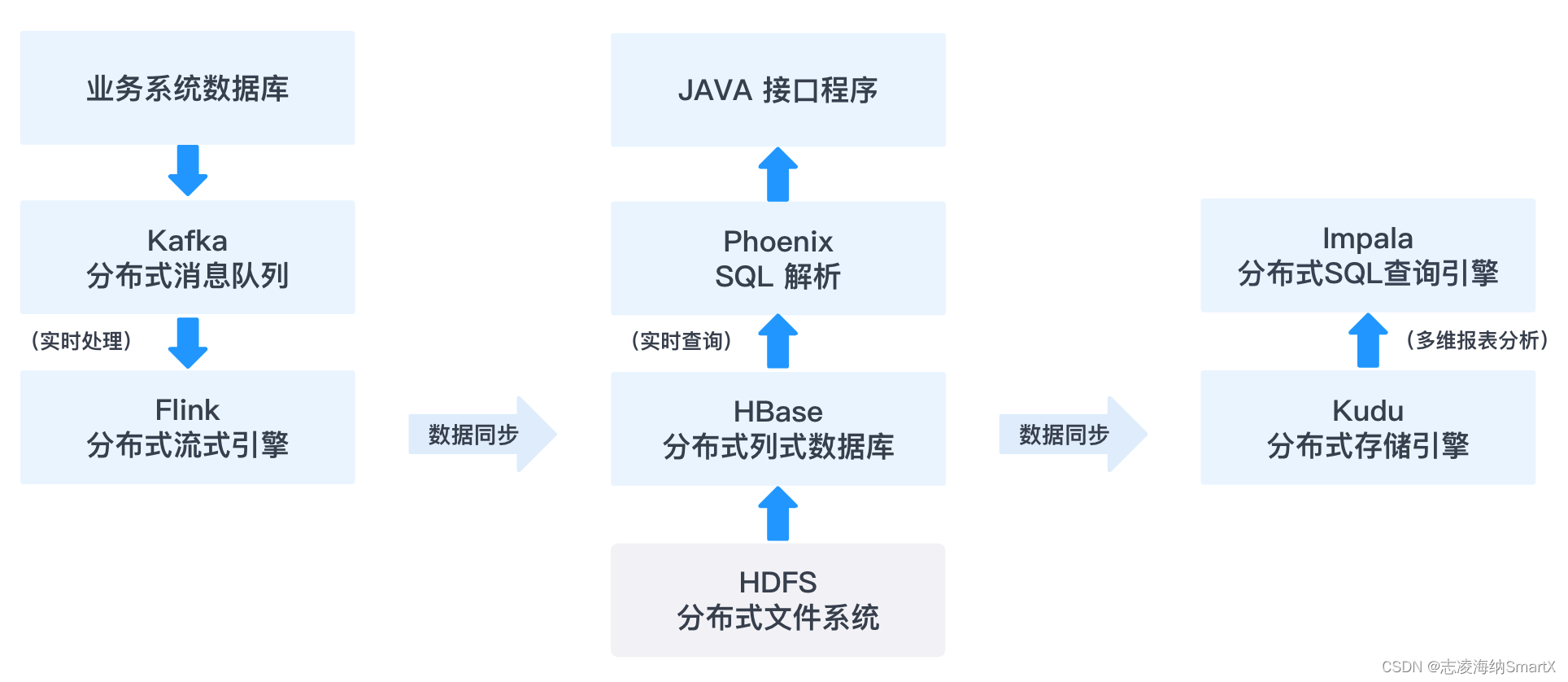
如上图所示,SmartX 分布式存储通过对接裸金属计算服务器承载大数据的 HDFS 和 HBase 等相关服务,测试主要定位在如下两个场景:
- HBase 数据表导出至 HDFS ,观察数据表导出时间。
- 通过 Phoenix 程序直接查询 HBase 数据库,观察接口数据响应时间(响应延迟)。
环境与配置
生产环境
生产环境有配置 1 和配置 2 两种服务器配置,具体如下:
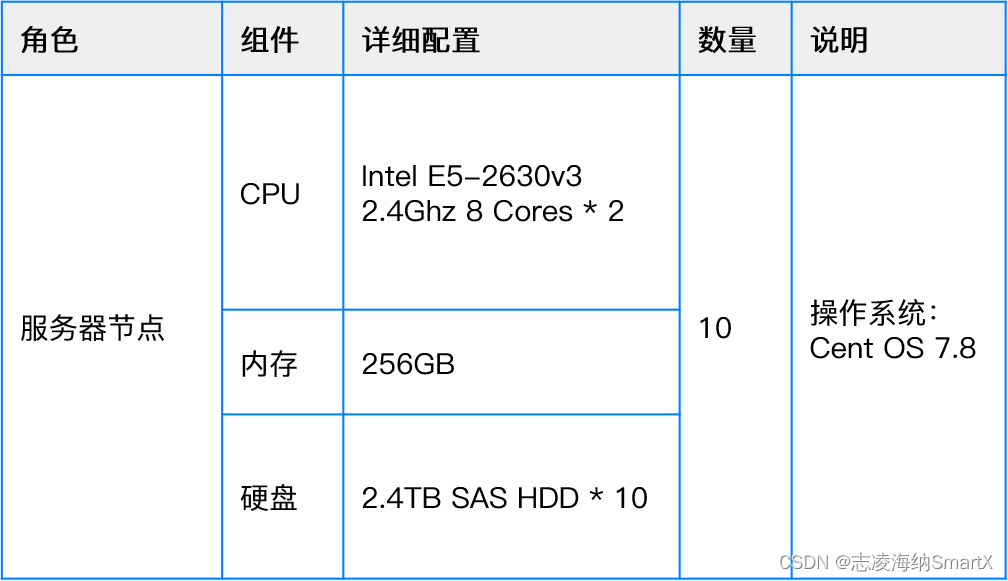
配置 1

配置 2
测试环境

说明:因为 NVMe over RDMA 技术对计算平台操作系统版本存在兼容性要求,故 Anolis OS 用于 NVMe Over RDMA 协议的测试。
测试结果
HBase 表导出

从 HBase 3 个表导出的用时对比来看,基于 NVMe over RDMA 接入协议的 SmartX 分布式存储相比生产物理机环境,导表时间缩短 72%;相比 iSCSI 接入协议,导表时间缩短约 60%。
SQL 单表查询
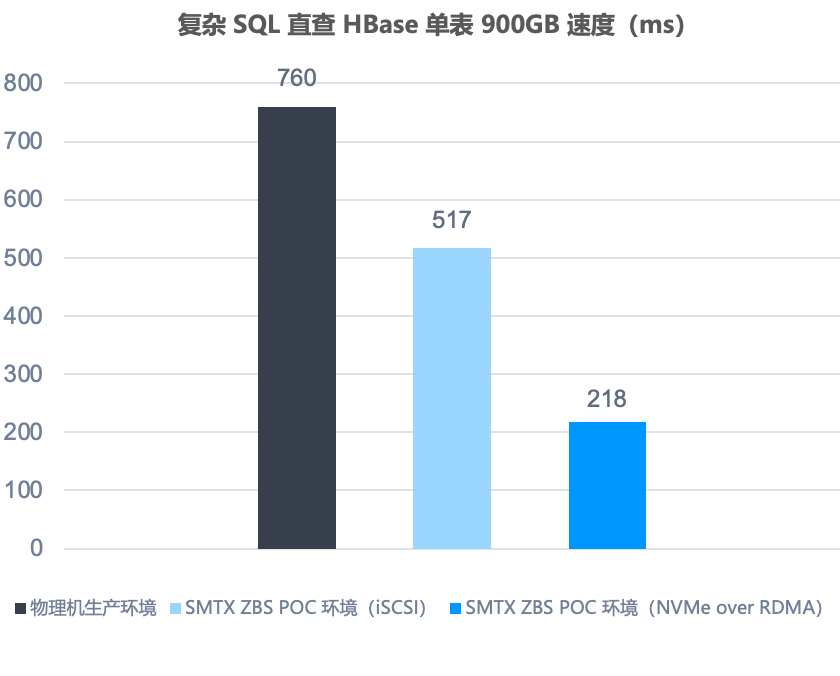
为了更真实反映出存储性能差异对于该场景的性能影响,通过使用 Phoenix 本地直接查询 HBase 方式进行测试(消除接口服务器自身影响和网络环境差异)。结果显示,SmartX 分布式存储(使用 NVMe over RDMA 接入协议)相比生产物理机环境,查询时间缩短 71%,相比 SmartX 分布式存储(使用 iSCSI 接入协议),查询时间缩短约 60%。
总体而言,在大数据应用场景下,基于不同存储架构与存储接入协议的存储系统,其性能表现有较大差异,其中开启 NVMe over RDMA(RoCE)的 ZBS 可大幅提升应用运行效率,满足大数据应用对高性能与低时延的需求。此外,如上测试结果仅是单表差异,如果是多表混合查询场景,分布式存储架构和 NVMe-oF 的优势在多任务的累积下会显现出更明显的差异。
某金融机构也对比测试了 SmartX 分布式存储(开启 RDMA)与全闪集中式存储执行数仓跑批任务的性能。结果显示,相比生产环境,SmartX 分布式存储执行全部存储过程集,3 个月平均跑批时间缩短 45%;其中,某耗时最长存储过程,3 个月平均跑批时间缩短 55%,其他存储过程集 3 个月平均跑批时间缩短 31%。
欲深入了解测试细节,请阅读:金融用户实践|分布式存储支持数据仓库业务系统性能验证。
总结
通过以上技术解读与性能评测可以看出,ZBS 对新一代网络技术具备卓越的支持能力,开启 NVMe over RDMA(RoCE)的 ZBS 不仅可提供更高的性能和更低的时延,还可充分支持大数据、数据仓库等性能敏感应用,满足生产环境业务需求。
结合《一文解析 RoCE 与相关存储方案趋势》中提到的 SAN 交换机“卡脖子”现状,ZBS 不仅能够支持高性能应用场景,还可帮助用户降低 SAN 交换机使用需求,以以太网交换机进行国产化替代。欲了解更多 SmartX 超融合信创云基础设施解决方案与相关用户实践,欢迎阅读电子书《信创云转型合集:技术路线、厂商评估与用践》。
这篇关于分布式存储 ZBS 的 RoCE 技术支持与大数据应用场景性能评测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




