本文主要是介绍2.6.3 hadoop体系之离线计算-Azkaban工作流调度系统-Azkaban多例实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.Command 类型单一 Job 示例
1.1 创建job文件
1.2 将job资源文件打包成zip文件
1.3 在web上创建项目并且上传压缩包
1.4 启动执行job
2.Command 类型多 Job 示例(有依赖关系)
2.1 创建有依赖关系的多个job描述
2.2 将所有job文件,打包到一个zip包中
2.3 在azkaban的web管理界面创建工程并且上传zip包
2.4 启动工作流flow
3.HDFS 操作任务
3.1 创建job描述文件fs.job
3.2 将job资源文件打包成zip文件
3.3 通过azkaban的web管理平台创建project并上传job压缩包,并且启动执行该job
4.MapReduce 任务
4.1 创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的example jar)
4.2 将所有job资源文件打到一个zip包中
4.3 在azkaban中web管理界面中创建工程并且上传zip包,并且启动job
5.Hive脚本任务
5.1 创建job描述文件和hive脚本
5.2 Job描述文件:hive.job
5.3 将所有job资源文件打包到一个zip中
5.4 在azkaban的web管理界面创建工程并上传zip包,并且启动job任务
6.Azkaban 的定时任务
Azkaba内置的任务类型支持command、java
1.Command 类型单一 Job 示例
1.1 创建job文件
创建文本文件,更改名称为mycommand.job 注意后缀.txt一定不要带上,保存为格式为UFT-8 without bom 内容如下:
type=command
command=echo 'hello world'1.2 将job资源文件打包成zip文件

1.3 在web上创建项目并且上传压缩包
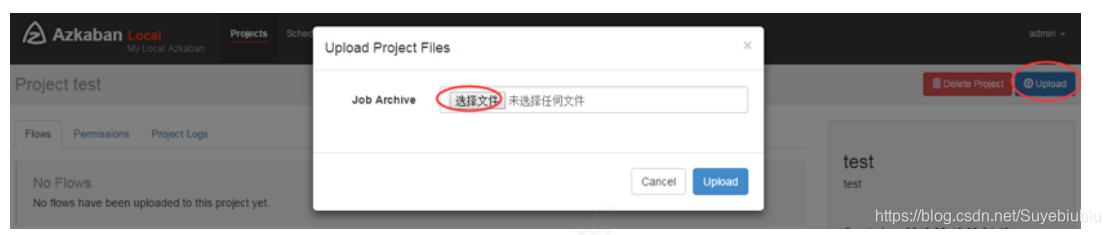
通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
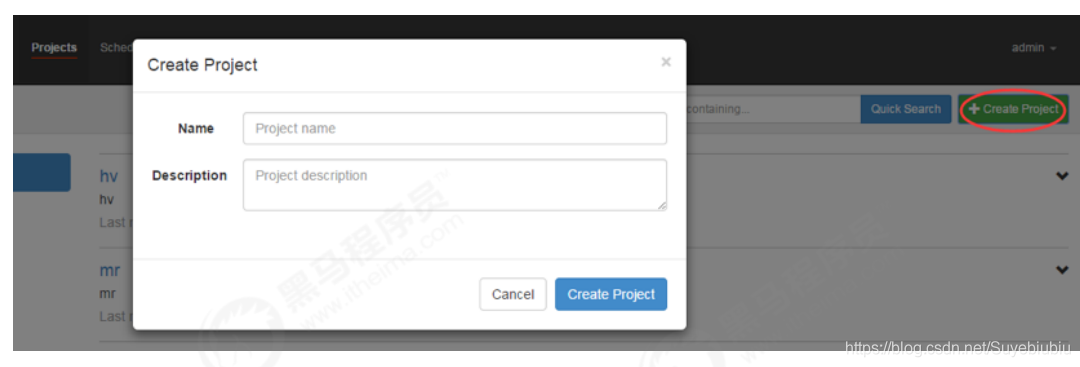
上传zip包
1.4 启动执行job

2.Command 类型多 Job 示例(有依赖关系)
2.1 创建有依赖关系的多个job描述

2.2 将所有job文件,打包到一个zip包中
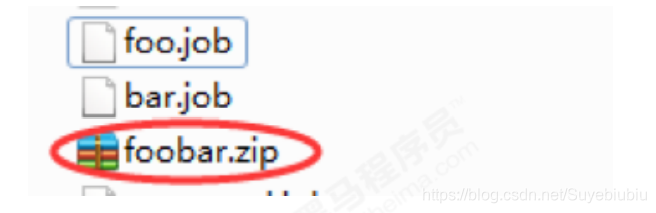
2.3 在azkaban的web管理界面创建工程并且上传zip包
2.4 启动工作流flow
3.HDFS 操作任务
3.1 创建job描述文件fs.job
type=command
command=/export/servers/hadoop‐3.1.1/bin/hdfs dfs ‐mkdir /azkaban3.2 将job资源文件打包成zip文件
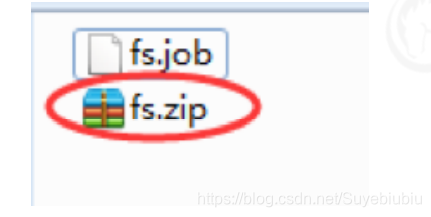
3.3 通过azkaban的web管理平台创建project并上传job压缩包,并且启动执行该job
4.MapReduce 任务
MR 任务依然可以使用command的job类型来执行
4.1 创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的example jar)
type=command
command=/export/servers/hadoop‐3.1.1/bin/hadoop jar hadoop‐mapreduce‐examples‐3.1.1.jar pi 3 5
4.2 将所有job资源文件打到一个zip包中

4.3 在azkaban中web管理界面中创建工程并且上传zip包,并且启动job
5.Hive脚本任务
5.1 创建job描述文件和hive脚本
Hive脚本: hive.sql
create database if not exists azhive;
use azhive;
create table if not exists aztest(id string,name string) row format
delimited fields terminated by '\t';5.2 Job描述文件:hive.job
type=command
command=/export/servers/apache‐hive‐3.1.1‐bin ‐f 'hive.sql'5.3 将所有job资源文件打包到一个zip中

5.4 在azkaban的web管理界面创建工程并上传zip包,并且启动job任务
6.Azkaban 的定时任务
使用azkaban的scheduler功能可以实现对我们的作业任务进行定时调度功能

这篇关于2.6.3 hadoop体系之离线计算-Azkaban工作流调度系统-Azkaban多例实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




