本文主要是介绍深入浅出-高性能低延迟消息传递框架-Disruptor,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

第1章:引言
大家好,我是小黑,咱们今天来聊一聊Disruptor框架,这是一个高性能的、低延迟的消息传递框架,特别适合用在日志记录、网关,异步事件处理这样的场景。Disruptor之所以强大,关键在于它的设计哲学和底层实现。对于Java程序员来说,了解Disruptor不仅能帮助咱们构建更高效的系统,还能深化对并发和系统设计的理解。
说到高性能,咱们就不得不提一提并发编程。传统的并发队列,比如BlockingQueue,确实简单好用。但是,它在处理大量并发数据时,性能就显得有点捉襟见肘了。这时候,Disruptor就闪亮登场了。它通过一种称为"Ring Buffer"的数据结构,加上独特的消费者和生产者模式,大幅度提高了并发处理的效率。
再来看看具体场景。想象一下,小黑正在开发一个高频交易系统,这里面的每一个毫秒都至关重要。如果使用传统的队列,系统的响应时间和吞吐量可能就成了瓶颈。但是,如果用Disruptor来处理交易事件,就能显著减少延迟,提升处理速度。这就是Disruptor的魅力所在。
第2章:Disruptor框架概述
说到Disruptor,咱们首先要了解它的核心组件:Ring Buffer。这不是一般的队列,而是一种环形的数据结构,能高效地在生产者和消费者之间传递数据。它的特点是预先分配固定数量的元素空间,这就减少了动态内存分配带来的性能损耗。
来看一段简单的代码示例,咱们用Java来创建一个基本的Ring Buffer:
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;public class SimpleDisruptorExample {public static void main(String[] args) {// 定义事件工厂EventFactory<LongEvent> eventFactory = new LongEventFactory();// 指定Ring Buffer的大小,必须是2的幂次方int bufferSize = 1024;// 构建DisruptorDisruptor<LongEvent> disruptor = new Disruptor<>(eventFactory, bufferSize, Executors.defaultThreadFactory(),ProducerType.SINGLE, new BlockingWaitStrategy());// 这里可以添加事件处理器disruptor.handleEventsWith(new LongEventHandler());// 启动Disruptordisruptor.start();// 获取Ring BufferRingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();// 下面可以向Ring Buffer发布事件// ...}
}
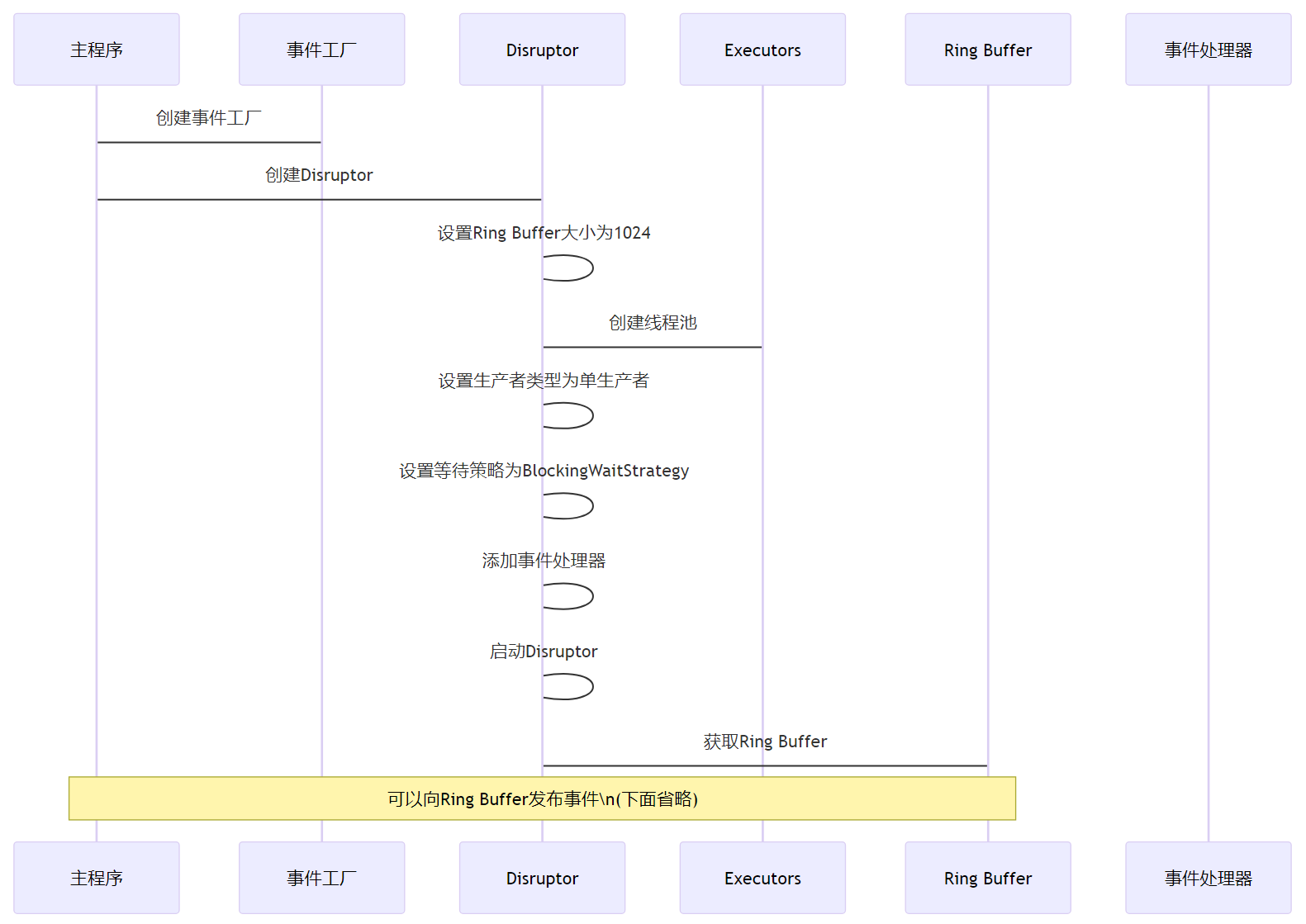
在这个代码中,“LongEvent”是一个简单的事件类,用来存放数据。Disruptor的构造函数里,咱们需要指定几个关键的参数,比如事件工厂、缓冲区大小、线程工厂、生产者类型和等待策略。这些都是Disruptor高效运作的关键要素。
接下来,咱们再看看Disruptor的另一个重要概念:消费者和生产者模式。在Disruptor中,生产者负责生成事件,将它们放入Ring Buffer;消费者则从Ring Buffer中取出这些事件进行处理。这种模式使得生产者和消费者之间的数据交换更加高效,极大地减少了线程间的竞争。
第3章:核心组件解析
Ring Buffer
咱们先从Ring Buffer开始。在Disruptor中,Ring Buffer是最核心的数据结构,它实际上是一个环形的数组。不同于普通队列,Ring Buffer预先分配固定大小的空间,这就避免了在运行时动态分配内存,极大提高了效率。
// 创建一个RingBuffer
RingBuffer<LongEvent> ringBuffer = RingBuffer.createSingleProducer(new LongEventFactory(), 1024);// 生产者发布事件
long sequence = ringBuffer.next(); // 获取下一个可用的序列号
try {LongEvent event = ringBuffer.get(sequence); // 获取对应序列号的元素event.set(12345L); // 设置事件数据
} finally {ringBuffer.publish(sequence); // 发布事件
}
在这段代码中,createSingleProducer 方法创建了一个单生产者的Ring Buffer。生产者通过调用 next() 方法来获取一个序列号,然后获取对应位置的事件,并设置事件数据。最后,调用 publish() 方法发布事件,使其对消费者可见。
Sequencer
接下来谈谈Sequencer。这是Disruptor中用于控制Ring Buffer序列号的组件。它负责处理如何分配序列号以及确保序列号的正确发布。
Disruptor提供了两种Sequencer:单生产者(SingleProducerSequencer)和多生产者(MultiProducerSequencer)。选择哪一种取决于你的应用场景。
Wait Strategy
等待策略(Wait Strategy)是另一个重要组件。它定义了消费者如何等待新事件的到来。Disruptor提供了多种等待策略,比如BlockingWaitStrategy、SleepingWaitStrategy等。每种策略在性能和CPU使用率之间有不同的权衡。
// 使用BlockingWaitStrategy
WaitStrategy waitStrategy = new BlockingWaitStrategy();// 创建Disruptor
Disruptor<LongEvent> disruptor = new Disruptor<>(new LongEventFactory(), 1024, Executors.defaultThreadFactory(), ProducerType.SINGLE, waitStrategy);
在这个例子中,BlockingWaitStrategy 是一种阻塞式的等待策略,当没有事件可处理时,消费者线程会阻塞。这种策略在低延迟的应用中很有用,因为它减少了CPU的使用,但同时会增加事件处理的延迟。
Event Processor
最后,咱们来看看Event Processor。这是Disruptor中的事件处理器,负责处理Ring Buffer中的事件。Disruptor通过不同类型的Event Processor来支持不同的处理模式,比如单线程处理、多线程处理等。
// 创建一个EventHandler
EventHandler<LongEvent> eventHandler = (event, sequence, endOfBatch) -> System.out.println("Event: " + event);// 将EventHandler添加到Disruptor
disruptor.handleEventsWith(eventHandler);// 启动Disruptor
disruptor.start();
在这段代码中,小黑定义了一个简单的事件处理器,它只是打印出事件的内容。handleEventsWith 方法用来将事件处理器与Disruptor关联起来。
Disruptor的高性能部分归功于这些紧密协作的核心组件。通过理解这些组件的工作原理和相互关系,咱们可以更好地利用Disruptor构建高效的并发应用。
第4章:Disruptor的并发模型
谈到并发编程,咱们总会想到线程安全、数据竞争、锁机制等一系列复杂的问题。Disruptor框架在这些方面做了很多优化,为咱们提供了一个既高效又简单的解决方案。
Disruptor并发的关键:无锁设计
Disruptor的一个核心特点是“无锁”。在传统的并发模型中,锁是保证多线程安全的常用手段,但它往往会成为性能的瓶颈。Disruptor通过避免使用锁,从而显著提升性能,尤其是在高并发场景下。
如何实现无锁?
Disruptor通过使用序列号的方式来管理对Ring Buffer的访问,这个机制确保了生产者和消费者之间的同步,而无需任何锁。每个生产者或消费者都有一个序列号,它代表了在Ring Buffer中的位置。通过对这些序列号的管理,Disruptor保证了数据在生产者和消费者之间正确且高效地传递。
让我们看一下这部分的代码:
// 生产者发布事件
long sequence = ringBuffer.next(); // 获取下一个可用的序列号
try {LongEvent event = ringBuffer.get(sequence); // 获取序列号对应的事件event.set(12345L); // 设置事件的值
} finally {ringBuffer.publish(sequence); // 发布事件
}
在这段代码中,生产者通过调用 next() 方法获取一个序列号,并在对应位置上放置事件。通过 publish() 方法将这个事件发布出去,使其对消费者可见。
消费者如何跟上生产者?
在Disruptor中,消费者使用一个称为“序列屏障”的机制来追踪当前读取到哪里。序列屏障会等待直到Ring Buffer中有可处理的事件。这种方式确保了消费者总是在正确的时机读取事件,避免了不必要的等待或竞争。
// 消费者处理事件
EventHandler<LongEvent> eventHandler = (event, sequence, endOfBatch) -> System.out.println("Event: " + event);disruptor.handleEventsWith(eventHandler);
在这里,消费者定义了一个 EventHandler 来处理事件。Disruptor确保每个事件只被一个消费者处理,而不会出现多个消费者处理同一个事件的情况。
第5章:实战案例分析
日志处理系统的需求
小黑正在为一家大型网站构建一个日志系统。这个系统需要实时处理成千上万条日志信息,每条日志都需要被解析、格式化,然后存储到数据库中。这里的挑战在于处理大量并发日志信息,同时保持系统的响应性和稳定性。
使用Disruptor构建日志系统
为了应对这个挑战,小黑决定使用Disruptor框架来构建日志系统。Disruptor的高性能和低延迟特性正适合这个场景。
首先,定义一个用于存储日志数据的事件类:
public class LogEvent {private String log;public void setLog(String log) {this.log = log;}public String getLog() {return log;}
}
接下来,创建一个Disruptor实例,并定义一个EventHandler来处理日志事件:
// 创建Disruptor
Disruptor<LogEvent> disruptor = new Disruptor<>(LogEvent::new, 1024, Executors.defaultThreadFactory());// 定义事件处理器
EventHandler<LogEvent> logEventHandler = (event, sequence, endOfBatch) -> {// 这里是处理日志的逻辑,比如解析和存储日志processLog(event.getLog());
};// 将事件处理器添加到Disruptor
disruptor.handleEventsWith(logEventHandler);// 启动Disruptor
disruptor.start();
最后,创建一个模拟日志生成的生产者,不断向Disruptor中发布事件:
// 获取Ring Buffer
RingBuffer<LogEvent> ringBuffer = disruptor.getRingBuffer();// 模拟日志生成
for (int i = 0; i < 10000; i++) {long sequence = ringBuffer.next();try {LogEvent event = ringBuffer.get(sequence);event.setLog("Log Message " + i); // 模拟日志消息} finally {ringBuffer.publish(sequence);}
}

在这个示例中,LogEvent 类用于存储日志信息。日志处理逻辑被封装在 logEventHandler 中。生产者通过向Ring Buffer发布事件来模拟日志消息的生成。
第6章:性能优化与最佳实践
1. 选择合适的等待策略
Disruptor提供了多种等待策略,每种策略在性能和CPU资源消耗之间有不同的权衡。例如,BlockingWaitStrategy 是CPU使用率最低的策略,但在高吞吐量时可能会增加延迟。而 BusySpinWaitStrategy 虽然延迟最低,但会大量占用CPU。因此,根据应用的性能需求和资源限制,选择最合适的等待策略非常关键。
// 选择合适的等待策略
WaitStrategy waitStrategy = new YieldingWaitStrategy();
2. 确保足够的缓冲区大小
Ring Buffer的大小是性能调优的另一个关键点。大小必须是2的幂次方,这是为了优化索引计算的性能。缓冲区太小可能导致频繁的缓冲区溢出,影响性能;太大则可能增加内存消耗和单个事件的处理时间。通常,选择一个能够容纳预期最高负载的大小是个不错的开始。
// 设置合适的Ring Buffer大小
int bufferSize = 1024; // 例如选择1024作为缓冲区大小
3. 避免不必要的垃圾回收
在高性能应用中,频繁的垃圾回收是性能杀手。在设计事件对象时,尽可能重用已有的对象,避免在事件处理中创建新对象。这样可以减少垃圾回收的频率和影响。
4. 利用多线程优势
Disruptor天生支持并发,通过合理的多线程策略,可以进一步提升性能。比如,你可以设置多个消费者并行处理事件,这样可以更高效地利用多核处理器的优势。
// 设置多个消费者
disruptor.handleEventsWith(new Consumer1(), new Consumer2(), new Consumer3());
5. 监控和调试
在生产环境中监控Disruptor的性能至关重要。通过监控Ring Buffer的剩余容量、事件处理速度等指标,可以及时发现潜在的性能瓶颈。
第7章:与其他技术的结合
Disruptor虽然强大,但在现实的应用中往往需要和其他技术协同工作。这一章,小黑来探讨一下Disruptor如何与其他流行的Java技术结合使用,以及在不同场景下的最佳实践。
结合Spring框架
Spring是Java开发中非常流行的框架,它提供了强大的依赖注入和AOP功能。将Disruptor与Spring结合,可以使得Disruptor的配置和管理更加方便。
@Configuration
public class DisruptorConfig {@Beanpublic Disruptor<LongEvent> disruptor() {// 配置DisruptorDisruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new, 1024, Executors.defaultThreadFactory());disruptor.handleEventsWith((event, sequence, endOfBatch) -> System.out.println("Event: " + event));return disruptor;}
}
在这个例子中,使用Spring的@Configuration和@Bean注解来配置Disruptor。这样一来,Disruptor的实例就可以被Spring容器管理,便于在应用中注入和使用。
集成Kafka
Kafka是一个分布式流处理平台,常用于处理大规模的消息流。将Disruptor与Kafka结合,可以实现高效的消息生产和消费。
// Kafka消费者将消息发布到Disruptor
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("topic"));
while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {ringBuffer.publishEvent((event, sequence) -> event.setValue(record.value()));}
}
在这个例子中,Kafka消费者从主题中获取消息,并将其发布到Disruptor的Ring Buffer中。这种方式可以将Kafka的高吞吐量和Disruptor的低延迟处理能力结合起来,适用于需要快速处理大量消息的场景。
与数据库交互
在很多业务场景中,需要将数据快速写入数据库。使用Disruptor可以有效地缓冲和批量处理数据,减少数据库的压力。
// Disruptor的事件处理器中写入数据库
disruptor.handleEventsWith((event, sequence, endOfBatch) -> {// 执行数据库写入操作database.insert(event.getData());
});
在这个例子中,Disruptor的事件处理器负责将事件数据写入数据库。通过批量处理和缓冲,可以减少数据库操作的次数,提高整体性能。
Disruptor的灵活性和高性能使其成为许多高并发应用的理想选择。通过与Spring、Kafka以及数据库等技术的结合,Disruptor可以更好地发挥其优势,解决复杂的业务挑战。无论是在消息队列、数据处理还是其他需要高性能处理的场景,Disruptor都能提供可靠的支持。
第8章:总结
Disruptor的核心优势
回顾一下,Disruptor的核心优势在于其独特的设计,使其在处理高并发数据时有着极高的效率。无锁的设计、高效的缓冲策略、灵活的事件处理模型,这些都是Disruptor能够提供极低延迟和高吞吐量的关键。
Disruptor的应用场景
Disruptor非常适合用在需要高性能并发处理的场景,比如金融交易系统、日志处理、事件驱动架构等。在这些应用中,Disruptor能够帮助系统稳定、快速地处理大量数据。
理解并合理应用Disruptor,都能为你的技术栈带来新的可能。希望这些章节能够启发大家,帮助大家在实际项目中有效利用Disruptor,打造更加强大、高效的系统。未来的道路上,还有很多值得探索和学习的地方!
更多推荐
详解SpringCloud之远程方法调用神器Fegin
掌握Java Future模式及其灵活应用
小黑的超超超级视頻会园站
使用Apache Commons Chain实现命令模式
这篇关于深入浅出-高性能低延迟消息传递框架-Disruptor的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





