本文主要是介绍现代信号处理学习笔记(二)参数估计理论,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参数估计理论为我们提供了一套系统性的工具和方法,使我们能够从样本数据中推断总体参数,并评估估计的准确性和可靠性。这些概念在统计学和数据分析中起着关键的作用。
目录
前言
一、估计子的性能
1、无偏估计与渐近无偏估计
2、估计子的有效性
两个无偏估计子的比较
无偏与渐近无偏估计子之间的比较
二、Fisher信息与Cramer-Rao不等式
1、Fisher信息
2、Cramér-Rao下界
三、Bayes估计
1、风险函数的定义
2、Bayes估计
二次型风险函数
均匀风险函数
四、最大似然估计
五、线性均方估计
六、最小二乘估计
1、最小二乘估计及其性能
2、加权最小二乘估计
总结
前言
参数估计理论是统计学中的一个重要概念,它涉及到从样本数据中推断总体参数的方法和原理。在统计学中,我们通常面对的是从总体中抽取的有限样本,而参数估计的目标就是利用这些样本数据来估计总体的未知参数。以下是一些关键的参数估计理论概念:
-
点估计(Point Estimation): 点估计是指通过样本数据得到一个特定的数值,用来估计总体参数。这个估计值通常用符号(例如,
)表示。
-
估计量(Estimator): 估计量是指用于估计总体参数的统计量,它是一个随机变量。样本均值和样本方差是常见的估计量。
-
无偏性(Unbiasedness): 一个估计量是无偏的,如果它的期望值等于被估计的参数真值。
-
有效性(Efficiency): 在无偏估计中,效率指的是方差的大小。一个估计量的效率越高,其方差越小,估计结果越精确。
-
一致性(Consistency): 一个估计量是一致的,如果当样本容量增大时,估计值趋近于真值。
-
最大似然估计(Maximum Likelihood Estimation, MLE): MLE是一种常用的估计方法,通过选择使得观察到的数据在给定模型下出现的概率最大的参数值作为估计值。
-
贝叶斯估计(Bayesian Estimation): 贝叶斯估计使用贝叶斯统计方法,考虑先验概率和似然函数,得到后验概率分布,从而进行参数估计。
-
置信区间(Confidence Interval): 置信区间是一个包含真实参数值的区间估计,它给出了对估计的不确定性的一种度量。
-
假设检验(Hypothesis Testing): 假设检验是统计推断的另一个重要方面,它涉及对总体参数的某些假设进行检验,以了解样本数据是否支持这些假设。
一、估计子的性能
参数估计理论的两个核心内容:
- 对估计子与真实参数的接近度进行量化定义;
- 研究不同的估计方法以及它们的性能比较。
1、无偏估计与渐近无偏估计
估计子的定义
估计子的数学模型通常通过一个统计量或一个统计规则来表示。以下是两种常见的估计子的数学模型:
点估计子: 点估计子是一个函数,它映射样本数据到一个具体的数值,即对总体参数的点估计。数学上,如果总体参数为θ,样本为X,点估计子可以表示为:
=T(X)
其中,是对参数θ的估计值,T是估计子。
区间估计子: 区间估计子提供了一个范围,该范围包含真实参数值的可能区间。通常使用一个区间来表示估计,形式为(L(X),U(X)),其中L和U是样本数据的函数,表示估计的下限和上限。数学上,区间估计子可以表示为:
估计区间=(L(X),U(X))
在这个区间内,我们有一定的置信度(例如95%置信度)认为真实参数值可能存在。

非无偏的估计统称有偏估计。
无偏估计是对估计子期望具有的一个重要性能,但这并不意味着有偏的估计子就一定不好。事实上,如果一个有偏估计是渐近无偏的,那么它仍然有可能是一个“好”的估计,甚至可能比另一无偏估计子还好。

偏差是误差的期望值,但是偏差为零并不保证估计子误差取低值的概率就高。评价估计子的小误差概率的指标称为一致性。

估计子的好坏通常通过其性质来衡量,其中一些重要的性质包括:
-
无偏性(Unbiasedness): 估计子的期望值等于真实参数值。即E(T(X)) = θ,其中E表示期望。
-
有效性(Efficiency): 在所有无偏估计中,方差最小的被认为是最有效的。有效估计子具有较小的方差,相对于其他无偏估计来说更稳定。
-
一致性(Consistency): 随着样本量的增加,估计子的值趋近于真实参数值。即对于任意ε > 0,当样本量趋近无穷时,P(|T(X) - θ| > ε) → 0,其中P表示概率。
-
渐近正态性(Asymptotic Normality): 在大样本情况下,估计子的分布趋近于正态分布。这是基于中心极限定理的结果。
不同的估计子可能在这些性质上有不同的表现,选择合适的估计子取决于具体问题和样本特性。在实际应用中,经常需要权衡不同性质,选择满足问题需求的估计子。
2、估计子的有效性
无偏性、渐近无偏性与一致性是我们希望一个估计子具有的统计性能,它们描述的是当样本趋于无穷大时估计子的性能,统称为大样本性能。
两个无偏估计子的比较
-
方差: 估计子的方差是衡量其在不同样本中变异性的指标。一个无偏估计子的方差越小,表示它在不同样本下的变化越小,更为稳定。
-
均方误差(MSE): 均方误差综合考虑了估计子的无偏性和方差,其定义为估计子的方差与偏差平方的和。MSE越小,说明估计子在估计总体参数方面的表现越好。

-
相对效率: 相对效率是用于比较两个估计子的MSE的相对大小。如果估计子 A 相对于估计子 B 的MSE较小,那么估计子 A 相对于 B 更有效。相对效率 RE 定义为:
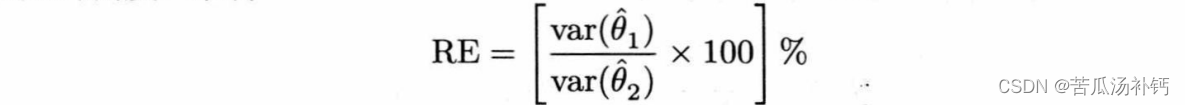
如果 RE>1,表示估计子 A 相对于 B 更有效。
无偏与渐近无偏估计子之间的比较
无偏估计:
- 定义: 无偏估计是指估计总体参数的期望值等于真实参数值的估计方法。即,如果对于所有可能的样本,估计值的期望等于真实参数值,那么这个估计是无偏的。
- 特点: 无偏估计追求在任何样本量下都有小的偏差,即估计值的期望与真实参数值一致。无偏性是一个重要的性质,因为它确保估计值在平均意义下不会系统性地偏离真实值。
渐近无偏估计:
- 定义: 渐近无偏估计是指在样本量趋于无穷大的情况下,估计值的偏差趋近于零。在大样本条件下,一些估计量可能表现出更好的性质,比如渐近无偏性。
- 特点: 渐近无偏估计通常利用大数定律和中心极限定理等概率论和数理统计的理论结果来进行推导。在大样本情况下,渐近无偏估计具有较好的性质,但在有限样本条件下仍然可能存在偏差。

综上所述,作为估计子误差的损失函数(或称代价函数),使用均方误差比只使用方差或偏差更合理。根据均方误差的大小,可以对θ的几种不同的估计子进行排队,比较它们之间的优劣。
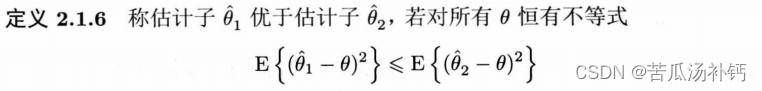
二、Fisher信息与Cramer-Rao不等式
Fisher信息(Fisher information)和Cramér-Rao不等式(Cramér-Rao inequality)都是与统计推断和估计理论相关的重要概念。它们通常用于评估估计量的性能和限制。
1、Fisher信息
Fisher信息是一个测量参数估计量精度的概念,它表示在给定概率分布下观察到的数据包含有关待估计参数的信息量。对于一个参数θ,Fisher信息I(θ)定义为对数似然函数(log-likelihood function)关于θ的负二阶导数的期望值。数学表达式如下:

其中,f(X;θ) 是观测数据的概率密度函数。


2、Cramér-Rao下界
Cramér-Rao不等式是一个基本的极限,它规定了任何无偏估计的方差的下界。具体而言,对于一个无偏估计器 ,Cramér-Rao不等式可以表达为:

其中,Var表示方差,I(θ) 是Fisher信息。
Cramér-Rao不等式的直观解释是,任何无偏估计器的方差至少是Fisher信息的倒数。当估计器达到这个下界时,称为Cramér-Rao下界是被达到的。
需要注意的是,Cramér-Rao不等式仅对无偏估计器成立。如果估计器有偏(即期望值与真实参数不相等),则方差的下界可能会更高。
总体而言,Fisher信息和Cramér-Rao不等式为我们提供了一种在统计估计中评估精度和效率的工具。
Fisher信息的意义可以用下面的定理来描述。
Cramer-Rao下界是所有无偏估计子所能够达到的最低方差,利用它可以定义最有效的估计子,常简称为优效估计子。

三、Bayes估计
1、风险函数的定义
当使用作为参数θ的估计时,估计误差θ-
通常不为零。因此,估计值
的质量决定于估计误差究竟有多小。除了前面介绍的偏差、方差和均方误差等测度外,也可以利用误差的范围作为估计误差的测度。这种测度称为代价函数或损失函数,用符号C(
,θ)表示。

注意,损失函数是随机变量x的函数,因而损失函数本身也是随机的。由于使用随机函数评价参数估计子并不方便,所以有必要把它变成固定函数。为此,通常取损失函数的数学期望值
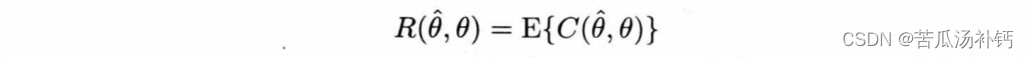
作为评价参数估计子性能的测度,并称之为风险函数。使风险函数R(,θ)最小的参数估计叫做 Bayes估计。
2、Bayes估计
二次型风险函数

均匀风险函数

四、最大似然估计
最大似然估计是最常用和最有效的估计方法之一。最大似然估计的基本思想是:在对被估计的未知量(或参数)没有任何先验知识的情况下,利用已知的若干观测值估计该参数。因此,在使用最大似然估计方法时,被估计的参数假定是常数,但未知;而已知的观测数据则是随机变量。
最大似然估计(Maximum Likelihood Estimation,简称MLE)是一种统计估计方法,用于估计模型参数。它的基本思想是选择使得观测数据出现的可能性最大的参数值,即选择参数值使得观测数据的似然函数最大。
设 X=(X1,X2,…,Xn) 是一个随机样本,服从某个分布 P(X;θ),其中 θ 是待估计的参数。似然函数 L(θ;X) 表示在给定参数 θ 的条件下,观测到样本 X 的概率密度(或概率质量)函数的乘积。对数似然函数(log-likelihood function)通常更方便处理,即取似然函数的自然对数:
ℓ(θ;X)=logL(θ;X)
最大似然估计的目标是找到使得对数似然函数最大的参数值:

为了求解这个最优化问题,可以使用数值优化方法或者解析方法,具体取决于模型和问题的特性。
最大似然估计有着良好的统计性质,尤其是在大样本的情况下,估计值通常具有渐近正态性。最大似然估计在统计学中得到广泛应用,涉及从正态分布的均值到逻辑回归的参数等各种参数估计问题。

五、线性均方估计
Bayes估计需要已知后验分布函数f(θ|X1,… , Xn),而最大似然估计则需要已知似然函数f(X1,……,Xn|θ)。但是,在很多实际情况下,它们是未知的。另外,最大似然估计有时会
导致非线性估计问题,不容易求解。内此,m女社就具这样两类参数估计方法。本节介绍就显得十分有吸引力。线性均方估计和最小二乘估计就是这样两类参数估计方法。
线性均方估计(Linear Mean Squared Estimation,简称LMSE)是一种用于估计线性模型参数的方法,其目标是通过最小化均方误差来找到最优的估计值。
考虑一个线性模型:
Y=Xβ+ε
其中,Y 是观测到的响应变量,X 是设计矩阵,β 是待估计的参数向量,ε 是误差项。
线性均方估计的目标是最小化均方误差,即最小化观测到的响应变量 Y 与模型预测 Xβ 之间的差异。这可以通过求解以下最小二乘问题来实现:

其中,∥⋅∥∥⋅∥ 表示欧几里得范数,即向量的二范数。
解上述问题得到的估计值 β^LMSE 具有最小的均方误差,因此是线性模型参数的最优估计,使得观测数据与模型预测的残差平方和最小。
六、最小二乘估计
除了线性均方估计外,最小二乘估计是另一种不需要任何先验知识的参数估计方法。
1、最小二乘估计及其性能


最小二乘估计(Least Squares Estimation)是一种用于估计模型参数的方法,其目标是通过最小化观测数据与模型预测之间的残差平方和来找到最优的参数估计。在线性回归问题中,最小二乘估计是一种特殊的线性均方估计。
考虑一个简单线性回归模型:

其中,Y 是观测到的响应变量,X 是预测变量,β0 和 β1 是待估计的模型参数,ε 是误差项。
最小二乘估计的目标是找到参数 β0 和 β1,使得残差平方和最小。残差指的是观测值与模型预测值之间的差异,数学表达式为:
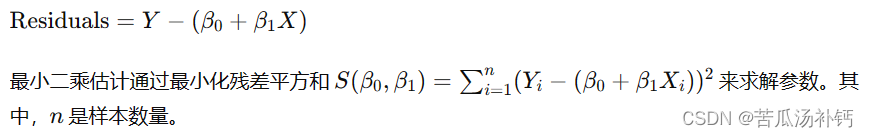
性能评估:
-
无偏性(Unbiasedness): 在一些条件下,最小二乘估计是无偏的,即估计值的期望等于真实参数值。这使得在样本容量足够大的情况下,估计值渐近地接近真实参数。
-
最小方差性(Minimum Variance): 在满足一些假设条件下,最小二乘估计是最有效的,即具有最小的方差。这意味着在给定样本大小的情况下,最小二乘估计是具有最小方差的线性无偏估计。
-
正态性假设: 最小二乘估计的渐近性质建立在误差项满足正态分布的假设上。在实际应用中,当样本容量足够大时,中心极限定理通常保证了估计的正态性。
总体而言,最小二乘估计在统计学中被广泛应用,尤其是在线性回归分析中。然而,对模型假设的敏感性以及对异常值的鲁棒性是需要考虑的问题。
2、加权最小二乘估计
最小二乘估计是一种用于估计模型参数的方法,其目标是通过最小化观测数据与模型预测之间的残差平方和来找到最优的估计值。这种方法广泛应用于回归分析和其他线性模型的参数估计。
在简单线性回归中,最小二乘估计就是通过最小化观测数据与模型预测之间的残差平方和来估计回归方程中的截距和斜率。对于多元线性回归,最小二乘估计则通过最小化残差平方和来估计模型中的系数。
最小二乘估计的性能优点包括:
-
闭式解:对于线性模型,最小二乘估计通常有闭式解,可以直接通过矩阵运算求解,使得估计值相对容易计算。
-
最优性质:在满足一些假设条件的情况下,最小二乘估计是参数估计的最优线性无偏估计,具有最小的方差。这使得最小二乘估计在统计推断中具有良好的性质。
-
高效性:对于满足线性关系的模型,最小二乘估计通常是一个有效的估计方法,特别是在大样本情况下。
然而,最小二乘估计也对一些假设条件敏感,比如对误差项的正态性和同方差性的假设。在存在异方差性(heteroscedasticity)或自相关性(autocorrelation)等问题时,最小二乘估计可能不再是最优的,此时可能需要考虑其他估计方法,如加权最小二乘估计。
加权最小二乘估计是最小二乘估计的一种推广,通过引入权重来处理异方差性。具体而言,对于每个观测值,引入一个权重,将每个残差乘以相应的权重,然后最小化加权残差的平方和。这样可以使得在估计中更关注具有较小方差的观测值,从而提高估计的效率。加权最小二乘估计的权重通常需要通过一些方法来选择,比如基于残差的方差的估计。
总结
估计理论的主要任务是在某种信号假设下,估算该信号中某个参数(比如幅度、相位、达到时间)的具体取值。参数估计:先假定研究的问题具有某种数学模型,如正态分布,二项分布,再用已知类别的学习样本估计里面的参数。非参数估计:不假定数学模型,用已知类别的学习样本的先验知识直接估计数学模型。
本章的内容是现代信号处理的理论基础。掌握了这些基础知识之后将会给后面学习现代信号处理的具体理论、方法与应用带来诸多的方便。
这篇关于现代信号处理学习笔记(二)参数估计理论的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









