本文主要是介绍StarRocks实战——多维分析场景与落地实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、OLAP 系统历史背景
1.1 历史背景与痛点
1.2 组件诉求
二、StarRocks 的特点和优势
2.1 极致的查询性能
2.2 丰富的导入方式
2.3 StarRocks 的优势特点
三、多维分析的运用场景
3.1 实时计算场景 / 家长监控中心
3.2 实时更新模型选择
3.2.1 更新模型UNIQUE
3.2.2 主键模型PRIMARY
3.3 主键模型不能使用Delete方式删除数据
3.4 报表实时指标计算
3.5 数据关系模型转变
3.7 精确一次性保证
3.8 指标存储转变
3.9 常用数据导入方式
3.9.1 实时数据
3.9.2 离线数据
3.10 分区分桶选择
3.11 慢查询分析
四、未来规划
原文大佬的这篇StarRocks多维分析场景与落地实践的文章整体写的很深入,这里直接摘抄下来用作学习和知识沉淀。
一、OLAP 系统历史背景
1.1 历史背景与痛点

先阐述下之前做实时和离线指标计算所使用的一些组件:
- 分钟级别调度的指标计算:用 Presto 或者是 Clickhouse。
- kafka数据流的计算:用SparkStreaming或者Flink去读取并计算
- 标签表的计算:会导入一些标签表到 HBase 里面,然后通过 Data API 的方式去提供给其他的系统使用(比如我们公司是做游戏的,会有一些玩家的标签表在对接客服之类的系统,他们会实时去查看每一个玩家的信息,进行一些问题的解答,我们会提供这样的数据)。
- 报表展示:报表的实时指标的结果会落到Mysql库中,报表系统会直接读取MySQL作为指标的展示。
这些组件其实各有优势:比如 Presto 直联 Hive,不需要做其他的操作,就可以做一些自主分析;ClickHouse单表查询性能好。但是随着架构演变,数仓集成了特别多组件,带来了以下痛点:
- 组件太多,维护多套组件的运维成本是比较高。
- 各组件的 SQL 语法存在差异,特别是 ClickHouse不支持标准 SQL,所以开发维护任务的成本也会比较高。
- 同一指标数据因为在多套系统都存在,需要确保计算的结果和口径的一致性,数据对齐成本也是比较高。
- 指标结果数据是落在Mysql中的,有一些维度比较多的数据,其结果数据量是比较大的,需要对 MySQL 通过分表去支持数据的存储和查询。但当数据量达到一定量级,即使分表,查询性能也比较差,导致报表系统时间上响应会比较慢。
1.2 组件诉求
为了解决以上痛点,需要选择统一的OLAP引擎,该引擎至少要满足以下要求:
-
数据秒级写入,低延迟毫秒级响应
-
复杂场景多表关联查询性能好
-
运维简单,方便扩展
-
支持高并发点查
-
易用性强,开发简单方便
对比调研了市面上一些组件,希望用一款存算一体的组件去优化我们的整个架构。首先,ClickHouse 的使用和运维比较困难,并且多表关联的性能比较差,所以我们没有选择 ClickHouse。我们又对比了 StarRocks 和 Doris,因为StarRocks在性能上会更好,所以我们最终选择了 StarRocks 作为统一的 OLAP引擎。
二、StarRocks 的特点和优势
2.1 极致的查询性能
StarRocks 是有着极致的查询性能的,主要得益于以下的这几点:
-
分布式执行 MPP:一条数据/一条查询请求会被拆分成多个物理的执行单元,可以充分利用所有节点的资源,这样对于查询性能是一个很好的提升。
-
列式存储引擎:对于大多数的 OLAP 引擎来说的话,基本会选择列式存储,因为很多的 OLAP 场景当中,计算基本上只会涉及到部分列的一些提取,所以相对于“行存”来说,列存只读取部分列的数据,可以极大的降低磁盘 IO。
-
全面向量化引擎:StarRocks所有算子都实现了向量化,向量化简单理解就是它可以消除程序循环的优化,是实现了 Smid 的一个特性,也就是当对一列数据进行相同的操作的时候,可以使用单条指令去操作多条数据,这是一个在 CPU 寄存器层面实行的对数据并行操作的优化。
-
CBO 优化器:在多表查询或者一些复杂查询的情况下,同一条sql会有不同的执行计划,不同计划之间的执行性能的差异可能会差几个量级,需要一款更好的优化器,才能够选择出相对更优的一个执行计划,从而提升查询效率。
2.2 丰富的导入方式

StarRocks 有丰富的导入方式,对接一些外部组件时,可以通过这些导入方式去直接完成数据的导入,极大节省开发时间。
2.3 StarRocks 的优势特点

-
运维简单:右侧这个图是 StarRocks 一个简单的架构图,只有FE和 BE 两种组件,不依赖于外部组件,运维简单,并且也方便扩缩容。
-
丰富的数据模型:StarRocks 支持明细、聚合、更新、主键4种数据模型,同时它还支持物化视图,方便我们针对不同的场景去选择合适的数据模型。
-
简单易用:StarRocks 兼容 MySQL 协议,支持标准的 SQL 语法,不需要太多的学习成本就可以去直接使用它。
-
支持多种外部表:StarRocks 支持多种外部表,比如 MySQL、ElasticSearch、Hive、StarRocks(这里指另一个集群的 StarRocks)等,跨集群、跨组件的关联查询也无需数据的导入,可以直接建立外部表,基于多个数据源去做关联查询。
三、多维分析的运用场景
3.1 实时计算场景 / 家长监控中心

例如上图的需求: 提供有各个未成年账号的一些实时的在线数据,或者是充值数据。右侧图是这一需求的数据流转图:读取Kafka数据,通过Flink清洗、转换后实时写入StarRocks,再通过 Data API 的方式去提供给小程序使用。因为跨部门协作,所以用Data API 的方式去提供数据比较安全。
同时也有一条离线覆盖的线路,Flink 计算难免会有一些上报的数据存在网络延迟,部分数据的计算可能会有一些差异,所以我们最终要用离线数据去覆盖实时数据,确保离线实时两条链路的数据一致性。
3.2 实时更新模型选择

StarRocks中提供了两种模型可以用于数据的更新,这两种组件的内部机制是有所区别的,所以使用场景也不太一样。
3.2.1 更新模型UNIQUE
内部是使用 Merge on Read 的方式去实现数据的更新的,也就是说 StarRocks 在底层操作的时候不会去更新数据,但是会在查询的时候实时去合并版本,所以同一主键的数据会存储多个版本;这样的好处是在写入的时候会非常流畅,但是也有坏处,在频繁导入数据的时候,主键会存在多个版本的数据,这对于查询性能会有所影响。
3.2.2 主键模型PRIMARY
内部使用的是Delete and Insert(删除并更新)的方式,StarRocks 会将主键存于内存中,在数据写入的时候,会去内存中找到这条数据,然后执行一个标记删除的操作,之后会把新的数据插入进去,最后合并时只需要过滤掉那些标记删除的数据就可以了,它的查询性能会比更新模型更高。
上文提到的需求,对实时性要求是比较高,数据更新特别频繁,因此我们会优先考虑查询性能,最终选择主键模型去作为表的数据模型。
3.3 主键模型不能使用Delete方式删除数据
前文 【3.1】提到离线覆盖实时的一个操作,使用场景是当我们在数据有一些差异的时候,需要用离线数据覆盖实时数据。使用 StarRocks 的主键模型进行数据删除时,只能够通过 Stream Load、Broker Load、Routine Load 等这三种导入的方式去删除数据,这是非常不方便的,导入时需要先提供一个标志位(如下图),去标明这是 Upsert 还是 Delete。对于直接写 SQL 语句去删除数据是非常不友好的。
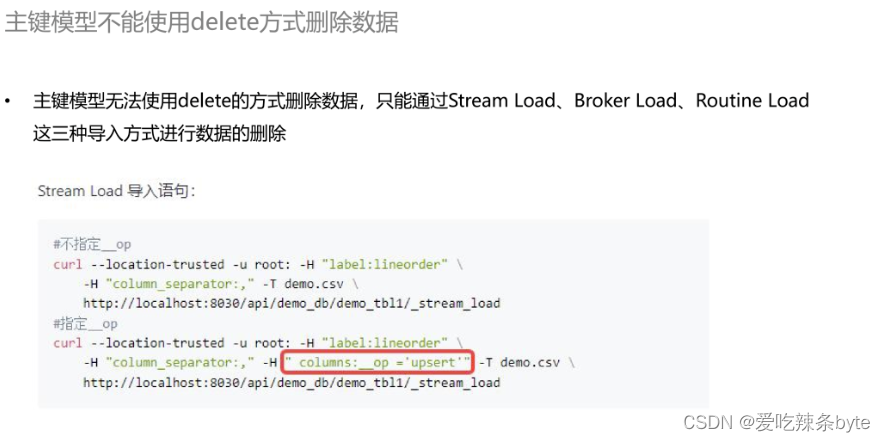
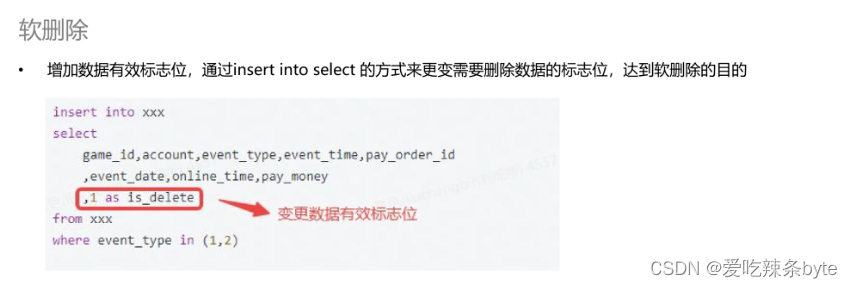
基于StarRocks主键模型能够更新数据的特性,可以选择使用软删除的方式去标记删除。先把这些需要删除的数据查询出来,再变更它的一个删除标志位。
StarRocks的更新模型也是支持删除操作的,我们为什么选择主键模型,而不是选择更新模型呢?主要考虑到以下三点情况:
(1)上文提到的需求,对实时性要求是比较高,数据更新特别频繁,所以用更新模型的查询性势必会有所下降。
(2)更新模型的删除也是有一些限制的,在删除条件比较复杂的情况下也是无法删除的。
比如:只能根据“排序列”去删除,或者是删除条件只能用与 AND 不能用或 OR。
(3)我们会用离线数据去覆盖实时数据,这两份数据其实是非常相近的,只会有很少的不一致,所以我们删除的冗余也是很少的。
3.4 报表实时指标计算
接下来介绍报表的一些实时指标的计算,首先报表是固定维度的,我们会有各种时效性的指标,在引进 StarRocks 之后,数仓架构做了重构。

- 首先,Flink读取Kafka的数据,只做一些简单的ETL操作;
-
其次,关联HBase数据,实时生成账号首次登录表;
-
接着数据写入到下级Kafka,再双写到Hive 和StarRocks。
-
最后在StarRocks中做逻辑分层,基于分钟级别的调度去产出各种场景下的指标结果。
重构后,报表系统直接读取StarRocks的指标数据进行展示分析(之前需要落到mysql库再对外展示),此外还通过Data API 的方式将数据提供给小程序使用。
3.5 数据关系模型转变
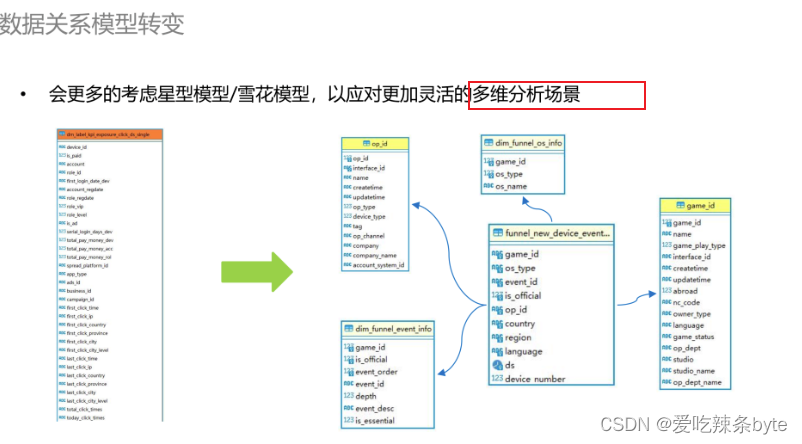
在数据建模方面,我们也做了一些重构。以前在使用 ClickHouse 时,鉴于其多表Join的能力不理想,我们的数据模型基本会使用一些大宽表,尽量使用单表查询以保证查询性能。但宽表模型的问题较为显著,即一旦维度有所变化,其回溯的成本是很高的。
在引入 StarRocks之后,它具备优异的多表 Join能力,所以我们建模时更多的是考虑采用星型模型或者雪花模型,将之前宽表中的复杂逻辑进行解耦,沉淀成一张张事实表和维度表。当维度不变化时不存在回溯成本,且能应对更多的灵活分析、多维分析的场景。
3.7 精确一次性保证
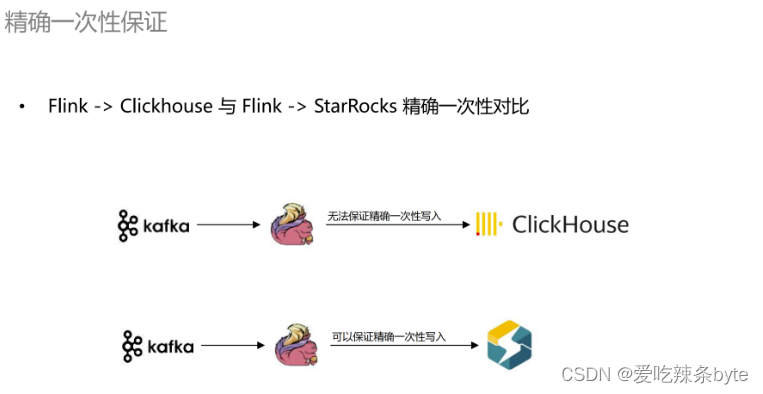
在精准一次性保证方面,以前使用Flink写入ClickHouse时是无法保证数据的精确一致性的,下游做计算时需要做各种去重操作,比如账号的去重,订单的去重等等。在引入 StarRocks 之后,使用官方的插件 Flink-Connector 去写入是可以保证数据的精确一次性的。
3.8 指标存储转变
以前实时计算的结果都会写入Mysql,需要借助其他工具,比如Sqoop,DataX等。
在引入StarRocks之后,实现了算存一体,查询分析统一。查询分析需要关联其他组件时候,可以根据其他数据源建立外表,采用联邦查询的方式快速得到结果。
3.9 常用数据导入方式

3.9.1 实时数据
使用官方的 Flink-Connector 插件导入数据,基本原理是在内存中积攒小批数据,再通过 Stream Load一次性导入 StarRocks,Stream Load 是通过 HTTP 协议提交和传输数据。
3.9.2 离线数据
采用Hive外表方式将Hive的一些结果数据迁移到StarRocks,导入过程中需要注意的点: Hive 的源数据信息,包括分区信息以及分区下的一些文件信息,都是存储在 StarRocks FE 中的,所以在更新Hive数据的时候,需要及时更新FE的缓存。
StarRocks提供了三种缓存的更新方式,一是自动刷新缓存,默认是两个小时会自动刷新一次;二是手动刷新缓存,导入离线数据的任务更倾向于采用此方式,能保证下一个导入任务执行的时候,缓存就已经更新了;三是自动增量更新。
3.10 分区分桶选择
我们在 StarRocks 建表的时候涉及到的一些分区分桶策略如下:
①先分区后分桶:如果不分区,StarRocks 会把整张表作为一个分区;分区是使用 Range 方式,分桶是使用 Hash 方式。
②分区选择:逻辑概念,表中数据可以根据分区列(通常是时间和日期)分成一个个更小的数据管理单元。查询时,通过分区裁剪,可以减少扫描的数据量,显著优化查询性能。
③分桶选择:StarRocks一般采用Hash算法作为分桶算法,在同一分区内,分桶键哈希值相同的数据会划分到同一个Tablet(数据分片),Tablet 以多副本冗余的形式存储,是数据均衡和恢复的最⼩单位。选择高基数的列为分桶键,保证数据在各个分桶中尽量均衡,提高集群资源利用率。
- 分桶列多,适用于高吞吐量(低吞吐)场景,是因为数据分布在多个桶中,并发查询多个桶,单个查询速度快。
- 分桶列少,适用于高并发场景,是因为一个查询可能只命中一个桶,多个查询之间查询不同的桶,磁盘的IO影响小,所以并发就高。
3.11 慢查询分析

StarRocks 也提供了一些慢查询分析工具,比如可以到日志里面去查看慢查询的信息,或者是到页面上去看它的 Profile(如上图)。Profile 是BE 执行后的一个结果,包含了每一步的耗时和处理量的结果。当遇到慢查询时,可以去具体分析这个 SQL 的执行情况,通过相应的措施去调优。
ps:StarRocks查询分析见文章:
第7.1章:StarRocks性能调优——查询分析-CSDN博客
四、未来规划
最后分享一下游族对于 StarRocks使用的一些未来规划:
①将剩余的实时场景全部迁入到 StarRocks,建立以StarRocks 为核心的统一查询分析平台。
③完善 StarRocks 的一些监控告警模块,比如慢查询的监控、ETL调度任务的监控、集群性能的监控等。
参考文章:
使用 Stream Load 事务接口导入 | StarRocks
Apache InLong 实时同步数据到 StarRocks 原理与实践
StarRocks 在游族的多维分析场景与落地实践
这篇关于StarRocks实战——多维分析场景与落地实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







