本文主要是介绍Python性能测试框架Locust实战教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01、认识Locust
Locust是一个比较容易上手的分布式用户负载测试工具。它旨在对网站(或其他系统)进行负载测试,并确定系统可以处理多少个并发用户,Locust 在英文中是 蝗虫 的意思:作者的想法是在测试期间,放一大群 蝗虫 攻击您的网站。当然事先是可以用 Locust 定义每个蝗虫(或测试用户)的行为,并且通过 Web UI 实时监视围攻过程。
locust运行原理
Locust 的运行原理是完全基于事件运行的,因此可以在一台计算机上支持数千个并发用户。与许多其他基于事件的应用程序相比,它不使用回调(比如 Nodejs 就是属于回调,Locust 不使用这种的逻辑)。相反,它通过 gevent 使用轻量级进程。测试您站点的每个蝗虫实际上都在其自己的进程中运行
Locust的特点
1、用Python编写测试方案 不需要在UI界面上点击,只需要正常编写代码即可,灵活性比较强
2、分布式&可扩展 Locust 支持分布在多台计算机上的运行负载测试(可以多台机器并行开搞)。
3、统计结果基于Web界面 Locust 有一个简单的用户界面,可实时显示相关的测试详细信息,并且统计结果界面是基于网页的,而网页是天生跨平台的,所以 Locust 是跨平台且易于扩展的
4、可以测试任何网页/应用/系统 只需用 python 编写想要测试的方案,然后放”蝗虫”去怼需要测试的项目就可以了,非常简单!
02、测试工具哪个好
LoadRunner
是非常有名的商业性能测试工具,功能非常强大。使用也比较复杂,但收费贼贵
Jmeter
同样是非常有名的开源性能测试工具,功能也很完善。可以当做接口测试工具来测试接口,但同时它也是一个标准的性能测试工具
Locust
功能上虽然不如LoadRunner及Jmeter丰富,但其也有不少优点。Locust 完全基本 Python 编程语言并且 HTTP 请求完全基于 Requests 库。
LoadRunner 和 Jmeter 这类采用进程和线程的测试工具,都很难在单机上模拟出较高的并发压力。Locust 的并发机制摒弃了进程和线程,采用协程(gevent)的机制。协程避免了系统级资源调度,由此可以大幅提高单机的并发能力。
03、环境安装
Python环境配置
(1)首先去Python官网下载Python3.6+版本解释器
(2)安装解释器并配置环境变量(将python的根目录以及Scripts路径配置到环境变量Path下面)
(3)打开cmd窗口,分别输入python、pip命令并回车,如果没有报错,则说明Python环境配置成功
Locust环境配置
(1)打开cmd窗口,输入pip install locustio==0.14.6 并回车,此时系统会自动下载locust库以及部分依赖库
PS:locust 目前有2个大版本,0和1的版本,两个版本之间语法差异比较大,安装1*版本,直接pip install locust 即可
(2)安装成功后验证:在cmd窗口中,输入python,进入python开发环境,然后输入import locust,如果没有报错,则说明locust安装成功
04、如何使用

Locust类
- HttpLocust类 继承了Locust类,表示将要生成的每一个虚拟的HTTP用户,用来发送请求到进行负载测试的系统。
- task_set属性 该 task_set 属性指向定义的用户行为的类
- host属性 host属性是要加载的域名(URL 前缀,例如http://xxxxxx)
- wait_time属性 用于发送Http请求时,虚拟用户需要等待的时间,等待时间是一个区间范围。单位为毫秒,等待时间在min_wait和max_wait之间随机选择
TaskSequence 类
- TaskSequence 类
TaskSequence 类是 TaskSet,但其任务将按顺序执行。 - @task装饰器
用于标识测试任务,并且可以通过task装饰器设置权重用于执行任务的执行率 - @seq_task装饰器
用于指定接口的执行顺序。可以把@task装饰器和@seq_task装饰器一起组合使用
初始化方法
1、setup 和 teardown方法 setup 和 teardown 都是只能运行一次的方法。在任务开始运行之前运行setup,而在所有任务完成并且蝗虫退出后运行 teardown;这使您能够在任务开始运行之前做一些准备工作(比如创建数据库,或者打印日志 等等),并在蝗虫退出之前进行清理。
2、on_start 和 on_stop 方法 每个虚拟用户执行操作时运行on_start方法,退出时执行on_stop方法
3、初始化方法的执行顺序 setup > on_start > on_stop > teardown
常用3种启动方式
直接启动
locust -f stock_center.py
(stock_center.py为执行脚本,可在编译器中直接运行该脚本)无web页面启动
locust -f stock_center.py --no-web -c 200 -r 20 -t 1m
(–no-web 代表不需要启动UI页面
-c 代表需要并发的用户数
-r 代表每秒并发的用户数-t 代表需要运行的时间)分布式启动
locust -f stock_center.py --master # 指定当前机器为master主机
locust -f stock_center.py --slave --master-host=10.xxx.xxx.xxx # 指定当前机器为从机并指向对应master主机启动页面
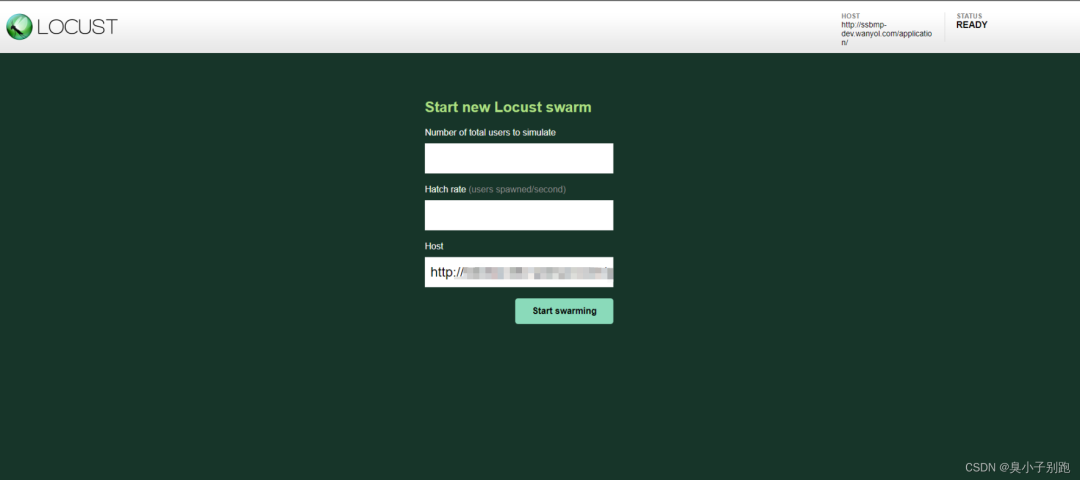
Number of total users simulate: 设置需要并发的总人数
Hatch rate(users spawned/second): 每秒启动的虚拟用户数
Start swarming: 执行locust脚本
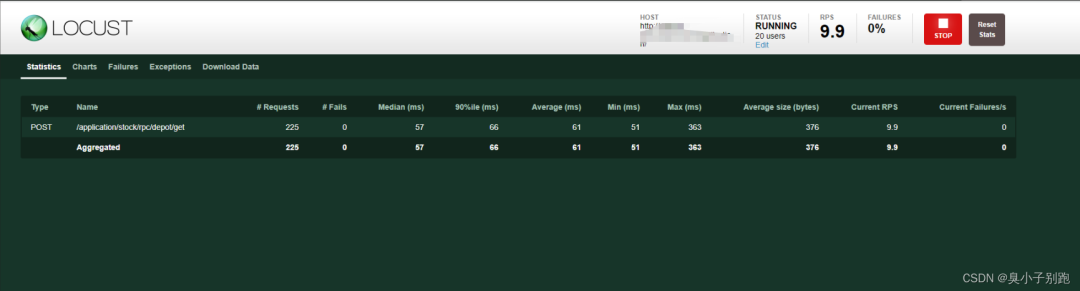
Type: 请求类型,即接口的请求方法
Name: 接口请求路径
Requests: 当前已完成的请求数量
Fails: 当前失败的数量
Median: 响应时间的中间值,即50%的响应时间在这个数值范围内,单位为毫秒
Average: 平均响应时间,单位为毫秒
Min: 最小响应时间,单位为毫秒
Max: 最大响应时间,单位为毫秒
Average Size: 平均请求的数据量, 单位为字节
Current RPS: 每秒能处理的请求数目
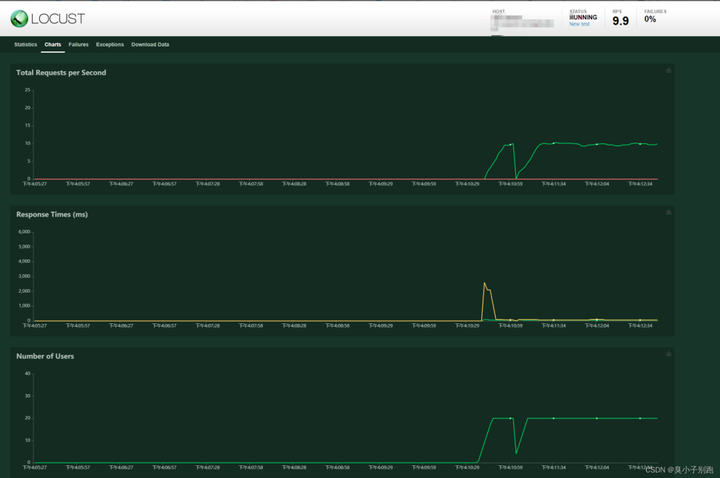
各模块说明
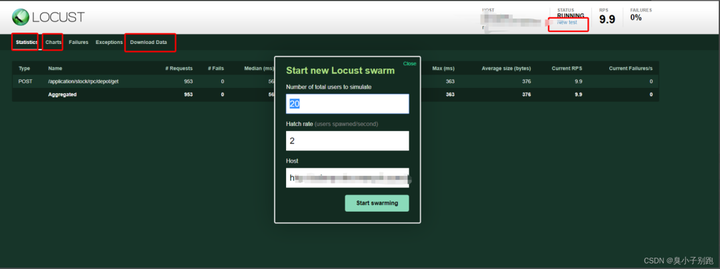
- New test:点击该按钮可对模拟的总虚拟用户数和每秒启动的虚拟用户数进行编辑;
- Statistics:类似于jmeter中Listen的聚合报告;
- Charts:测试结果变化趋势的曲线展示图,分别为每秒完成的请求数(RPS)、响应时间、 不同时间的虚拟用户数;
- Failures:失败请求的展示界面;
- Exceptions:异常请求的展示界面;
- Download Data:测试数据下载模块, 提供四种类型的CSV格式的下载, 分别是:Statistics、responsetime、failures、exceptions;
05、Locust的总结
局限:
locust的局限性在于:目前其本身对测试过程的监控和测试结果展示,不如jmeter全面和详细,需要进行二次开发才能满足需求越来越复杂的性能测试需要。
优势:
纯脚本形式,并且HTTP请求完全基于Requests库。用过Requests的都知道,这个库非常简洁易用,但功能十分强
另外一点就是并发机制了。Locust的并发机制摒弃了进程和线程,采用协程(gevent)的机制。避免了系统级资源调度,由此大幅提高了性能。正常情况下,单台普通配置的测试机可以生产数千并发压力,这是LoadRunner和Jmeter都无法实现的。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!

这篇关于Python性能测试框架Locust实战教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







