本文主要是介绍高速DRAM的training,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
随着每一代接口(Interface)和存储(memory)的频率和速率的提高,信号采样以及传输变得越来越困难,因为数据眼(data eyes)越来越小。
为了帮助高速 I/O 握手,接口和存储支持越来越多的Training Modes,系统设计人员必须将这些Training Modes作为系统bring up和正常操作的一部分,以使系统能够按预期工作。
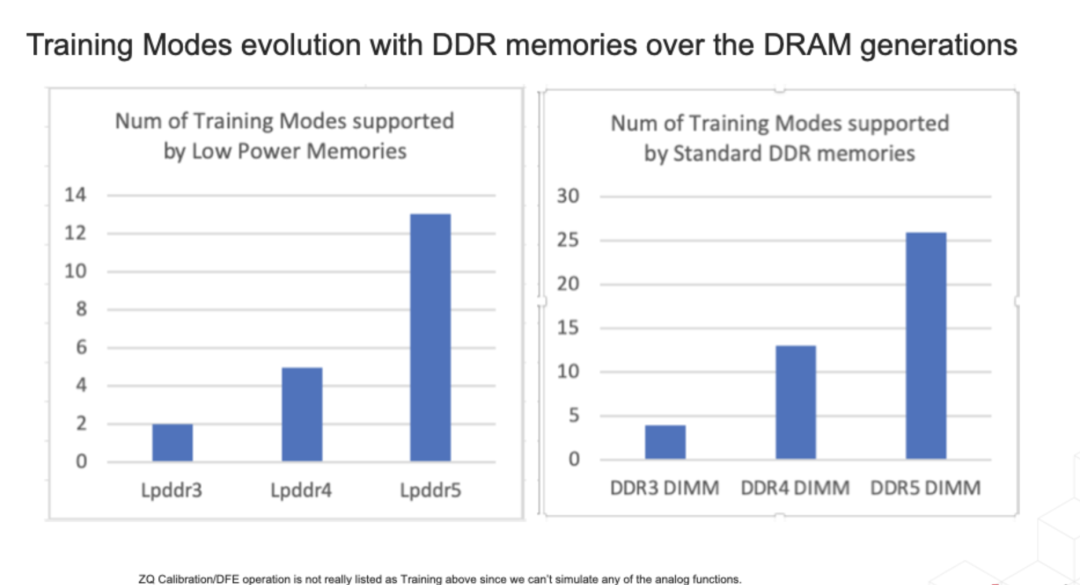
尤其是对于数据中心业务,这些training mode非常重要。
以下是 LPDDR5/DDR5 DIMM 等最新 DRAM 支持的最重要的training mode:
1. Vref Training
这是内存子系统初始bring up的部分。Host通常会设置 DRAM 模式寄存器,该寄存器将用作command、chip select和 DQ 等信号的参考电压。由于DRAM 可能无法在完成 Vref training之前对 Host 命令进行采样,因此 Host 会分多个周期发送该命令,以确保 DRAM 能够接收该命令。
2. Command Training
这通常是Host必须执行的第一个功能Training,以确保 DRAM 设备能够理解它发送的命令。它涉及Host驱动 DRAM 的command总线, 然后DRAM对 DQ 信号进行采样并反馈回去。Host可以检查反馈并与它驱动 的内容进行比较。 如果反馈与驱动的内容不匹配,Host可以调整输入。
3. Clock to Strobe leveling
由于布线差异等其他因素,DRAM 使用的strobe信号通常不会与它接收的输入时钟对齐。Host必须通过Clock to Strobe leveling来调整此相位差。此training称为 DDR5 的 Write leveling。
4. Strobe to DQ Training
完成 Clock to Strobe training后, 下一步是确保 Host 和 DRAM 能够正确发送/采样写入和读取数据。这一步的目的是让 Host 知道strobe和data信号的时序关系,称为Strobe to DQ training。它通常涉及写入 DRAM 已知数据,然后从同一位置读取并比较两者以检查它们是否匹配。然后,Host将其调整strobe和data的相位关系,并再次执行相同的步骤,直到它能够正确地向 DRAM 写入/读取数据。
5. Other Trainings
通常在DIMM中还支持其他几项trainings,以帮助实现设备的特定调整。对于 DDR5 DIMM 等设备,trainings不仅涉及单个组件(RCD、DRAM、DB),还涉及信号如何从一个组件传播到另一个组件。Host需要training单个组件以及整个模块,例如一些 DDR5 LRDIMM 模块级trainings的示例(如 MRE、MRD、DWL、MWD 等)。
总之,trainings是接口和存储系统启动和正常功能的重要组成部分。它也日益成为一个重要的设计和验证挑战,需要作为 SOC 规划的一部分加以考虑。
这篇关于高速DRAM的training的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[论文解读]Genre Separation Network with Adversarial Training for Cross-genre Relation Extraction](https://i-blog.csdnimg.cn/blog_migrate/a81ef8f36f1400d5367d93036bc14ef7.png)



