本文主要是介绍[linux][异常检测] hung task, soft lockup, hard lockup, workqueue stall,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
hung task,soft lockup,hard lockup,workqueue stall 是 linux 内核中的异常检测机制,这 4 个检测均是通过时间维度上的检测来判断异常。
在时间维度上的检测机制,有两个核心的点:
(1)一个表示被检测对象最新状态的变量
这个变量可以用时间戳表示,也可以是一个计数器。
(2)一个定时器
这个定时器内部做检测工作,检测的依据就是状态变量。如果状态变量是时间戳,那么直接将时间戳和当前时间比较看看是不是超时;如果状态变量是计数器,那么就直接将新旧两个计数进行比较来判断任务是不是出于活跃状态。
本文分别介绍每种检测机制的检测对象,检测原理,异常打印信息,配置参数。
1 hung task
1.1 检测对象
hung task 检测对象是处于 D 状态的线程。处于 D 状态的线程不能被信号唤醒,不能响应任何信号,kill -9 也杀不死。一般在访问磁盘,等待内核 mutex,或者内核出现异常的时候会将线程设置成 D 状态。正常情况下,一个线程处于 D 状态的时间不应该太长,如果太长,那么有可能是出现了异常。
1.2 检测原理
hung task 源码在 kernel/hung_task.c。
内核中使用一个线程来检测 hung task,线程名为 khungtaskd,在系统中也能查看到这个线程,如下图所示。

线程的入口函数是 watchdog(),可以看到这个函数中是一个死循环, 死循环中每检测一次,都通过 schedule_timeout_interruptible() 睡一定的时间。这个时间可以配置,配置参数如下,默认是 0,这个配置大于 0 的话才会生效,默认 0 的话就会使用内核默认的时间,内核默认配置一般是 10s。

static int watchdog(void *dummy)
{unsigned long hung_last_checked = jiffies;set_user_nice(current, 0);for ( ; ; ) {unsigned long timeout = sysctl_hung_task_timeout_secs;unsigned long interval = sysctl_hung_task_check_interval_secs;long t;if (interval == 0)interval = timeout;interval = min_t(unsigned long, interval, timeout);t = hung_timeout_jiffies(hung_last_checked, interval);if (t <= 0) {if (!atomic_xchg(&reset_hung_task, 0) &&!hung_detector_suspended)check_hung_uninterruptible_tasks(timeout);hung_last_checked = jiffies;continue;}schedule_timeout_interruptible(t);}return 0;
}真正做检测的函数是 check_hung_uninterruptible_tasks()。在实际检测中,会遍历系统中所有的线程,如果线程当前的状态是 TASK_UNINTERRUPTIBLE,那么就会确认线程在 D 状态下的时间,如果时间超过配置的门限值,那么就会报异常,内核 panic 或者打印异常信息。
判断是否超时的逻辑在函数 check_hung_task() 中,判断如果超时时间在当前时间之后,那么就是还没有超时,直接返回;否则,就会根据配置来决定 panic 还是打印异常信息。
static void check_hung_uninterruptible_tasks(unsigned long timeout)
{...for_each_process_thread(g, t) {...if (t->state == TASK_UNINTERRUPTIBLE)check_hung_task(t, timeout);}
}static void check_hung_task(struct task_struct *t, unsigned long timeout)
{...if (time_is_after_jiffies(t->last_switch_time + timeout * HZ))return;...
}1.3 异常打印信息
linux 中的 TASK_UNINTERRUPTIBLE 和 TASK_KILLABLE 均会显示为 D 状态。
从上边的代码也可以看出来,虽然 TASK_UNINTERRUPTIBLE 和 TASK_KILLABLE 都显示为 D 状态,但是 hung task 检测中只关心 TASK_UNINTERRUPTIBLE 状态的线程,不关心 TASK_KILLABLE 的线程。
为了构造出处于 D 状态的线程,我们使用内核模块来实现。在内核模块中创建两个线程,一个线程设置为 TASK_UNINTERRUPTIBLE,一个线程设置为 TASK_KILLABLE。当超过配置时间之后,通过 dmesg 便能看到打印信息。
内核模块代码:
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/kthread.h>
#include <linux/sched.h>
#include <linux/module.h>static struct task_struct *thread_uninterruptible = NULL;
static struct task_struct *thread_killable = NULL;static int thread_uninterruptible_func(void *data) {printk("thread uninterruptibe tid: %d\n", current->pid);while (!kthread_should_stop()) {set_current_state(TASK_UNINTERRUPTIBLE);schedule();printk("thread uninterruptibe is waken up\n");break;}printk("thread uninterruptible exit\n");return 0;
}static int thread_killable_func(void *data) {printk("thread killable tid: %d\n", current->pid);while (!kthread_should_stop()) {set_current_state(TASK_KILLABLE);schedule();printk("thread killable is waken up\n");break;}printk("thread killable exit\n");return 0;
}static int __init hungtask_mod_init(void)
{printk("hung task init\n");thread_uninterruptible = kthread_create(thread_uninterruptible_func, NULL, "thread_uninterruptible");if (IS_ERR(thread_uninterruptible)) {printk("failed to create thread uninterruptible\n");return -1;}thread_killable = kthread_create(thread_killable_func, NULL, "thread_killable");if (IS_ERR(thread_killable)) {printk("failed to create thread killable\n");return -1;}wake_up_process(thread_uninterruptible);wake_up_process(thread_killable);return 0;
}static void __exit hungtask_mod_exit(void)
{printk("hung task exit\n");wake_up_process(thread_uninterruptible);wake_up_process(thread_killable);kthread_stop(thread_uninterruptible);kthread_stop(thread_killable);
}module_init(hungtask_mod_init);
module_exit(hungtask_mod_exit);MODULE_LICENSE("GPL");
MODULE_AUTHOR("w2x");
MODULE_DESCRIPTION("watch hung task");
MODULE_VERSION("1.0");
Makefile:
obj-m += hungtask.o
KDIR =/lib/modules/$(shell uname -r)/build
all:make -C $(KDIR) M=$(shell pwd) modules
clean:make -C $(KDIR) M=$(shell pwd) clean
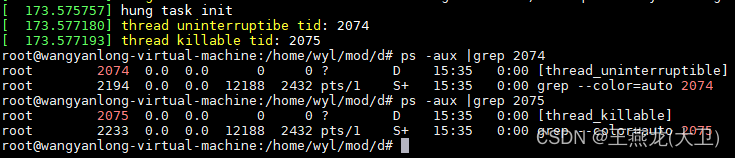
安装模块之后,通过 dmesg 能够看到两个线程的 id,通过 ps 命令可以查看到两个线程均是 D 状态。
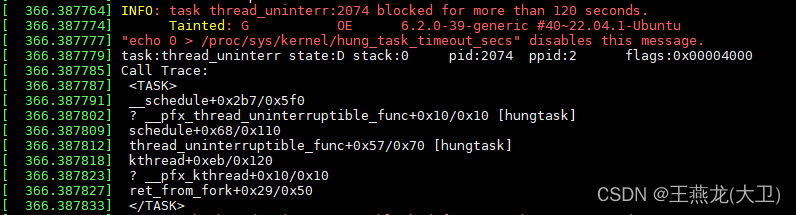
默认情况下,hung task 是打印日志,不是内核直接 panic。日志信息如下:
1.4 配置参数
| 参数 | 含义 |
| kernel.hung_task_timeout_secs = 120 | 线程处在 TASK_UNINTERRUPTIBLE 的超时时间,超时之后打印线程栈或者内核 panic |
| kernel.hung_task_panic = 0 | 如果设置为 1,那么超时之后内核 panic, 否则超时之后只打印线程栈,可以在 dmesg 中看到 |
| kernel.hung_task_check_interval_secs = 0 | 检查周期 |
| kernel.hung_task_warnings = 10 | 打印告警日志的次数 |
| kernel.hung_task_check_count = 4194304 | hung task 功能一次检测的线程的个数,放置检查的线程太多,一直占用着 cpu。 |
| kernel.hung_task_all_cpu_backtrace = 0 | 打印每个核的调用栈 |
2 soft lockup
2.1 检测对象
如果在一个 cpu 核上,一个线程运行了很长时间,在这段时间内,其它线程都得不到调度,那么可能引起问题。 soft lockup 就是检测这种情况,判断一个 cpu 核上是不是很长时间没有发生过调度。
2.2 检测原理
soft lockup 检测的代码在 kernel/watchdog.c 中。
内核中维护了一个 per cpu 的变量 watchdog_touch_ts,这个变量表示一个时间戳,只要发生了线程调度,那么这个变量就会更新为最新的时间戳。
另外在一个定时器中检测 watchdog_touch_ts,如果当前时间减去 watchdog_touch_ts 超过了 soft lockup 设置的时间门限,那么就会 panic 或者打印告警信息。
watchdog_timer_fn():
这个函数是 watchdog() 定时器的回调函数, soft lockup 检测的很多工作都是定时器驱动的。
定时器的周期由下边代码的 sample_period 来表示,单位是 ns,watchdog_thresh 可以从 /proc/sys/kernel/watchdog_thresh 中获取。所以计算出来,定时器周期是 4s。

static int get_softlockup_thresh(void)
{return watchdog_thresh * 2;
}static void set_sample_period(void)
{sample_period = get_softlockup_thresh() * ((u64)NSEC_PER_SEC / 5);watchdog_update_hrtimer_threshold(sample_period);
}更新 watchdog_touch_ts 的时候,并不是说系统中的任意一个线程发生调度都会更新这个时间戳。而是特定的线程,在函数 watchdog_timer_fn() 中会向 softlockup stop work 中提交一个任务,这个任务的入口函数是 softlockup_fn() 在这个函数中对 watchdog_touch_ts 进行的更新。
static enum hrtimer_restart watchdog_timer_fn(struct hrtimer *hrtimer)
{...stop_one_cpu_nowait(smp_processor_id(),softlockup_fn, NULL,this_cpu_ptr(&softlockup_stop_work));...
}怎么保证这个任务一定会被调用到呢 ?
这个任务是被内核中的 migration 线程处理,这个线程的调度策略是 stop 调度策略,stop 调度策略是内核中优先级最高的调度策略。所以说,只要发生了调度,migration 一定会第一个得到调度,时间戳也一定会更新。

判断 soft lockup 是否成立的函数是 is_softlockup()。从代码中可以看到,默认情况下,softlock up 的超时时间是 20s。
static int is_softlockup(unsigned long touch_ts)
{unsigned long now = get_timestamp();if ((watchdog_enabled & SOFT_WATCHDOG_ENABLED) && watchdog_thresh){/* Warn about unreasonable delays. */if (time_after(now, touch_ts + get_softlockup_thresh()))return now - touch_ts;}return 0;
}2.3 异常打印信息
要复现 soft lockup 的现象,我们仍然使用一个内核模块来实现。
复现 soft lockup 的时候要注意,看看当前内核是不是抢占式内核,在抢占式内核和非抢占式内核上,复现的方式是不一样的。
抢占式内核:
抢占式内核是可抢占的,即使在内核中线程中是 while(1) 死循环,那么这个线程也是可以被抢占的,也就是会发生调度,上边讲的时间戳会更新。这个时候需要关掉抢占,关掉抢占的方式可以使用 preempt_disable() 或者使用自旋锁 spin_lock() 都可以。
非抢占式内核:
如果内核是非抢占的,也就是说只要线程不主动让出 cpu,那么是不会发生调度的,这个时候使用一个 while(1) 死循环就能构造出 soft lockup 的现象。
判断内核是不是抢占内核,可以使用 uname -a 来查看,其中包含 PREEMPT 则是抢占式内核;否则是非抢占式内核。我使用的虚拟机是非抢占式内核,所以不用关抢占。
内核模块代码如下,在内核模块中创建了一个线程,这个线程中是一个死循环。
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/kthread.h>
#include <linux/delay.h>
#include <linux/spinlock.h>static struct task_struct *softlockup_thread;static int infinite_loop_thread(void *data) {printk("soft lockup thread, tid: %d\n", current->pid);while (!kthread_should_stop()) {// This loop will never exit, causing a soft lockup.}return 0;
}static int __init softlockup_init(void) {printk("soft lockup example module loaded\n");softlockup_thread = kthread_run(infinite_loop_thread, NULL, "softlockup_thread");return 0;
}static void __exit softlockup_exit(void) {kthread_stop(softlockup_thread);printk("soft lockup example module unloaded\n");
}module_init(softlockup_init);
module_exit(softlockup_exit);
MODULE_LICENSE("GPL");
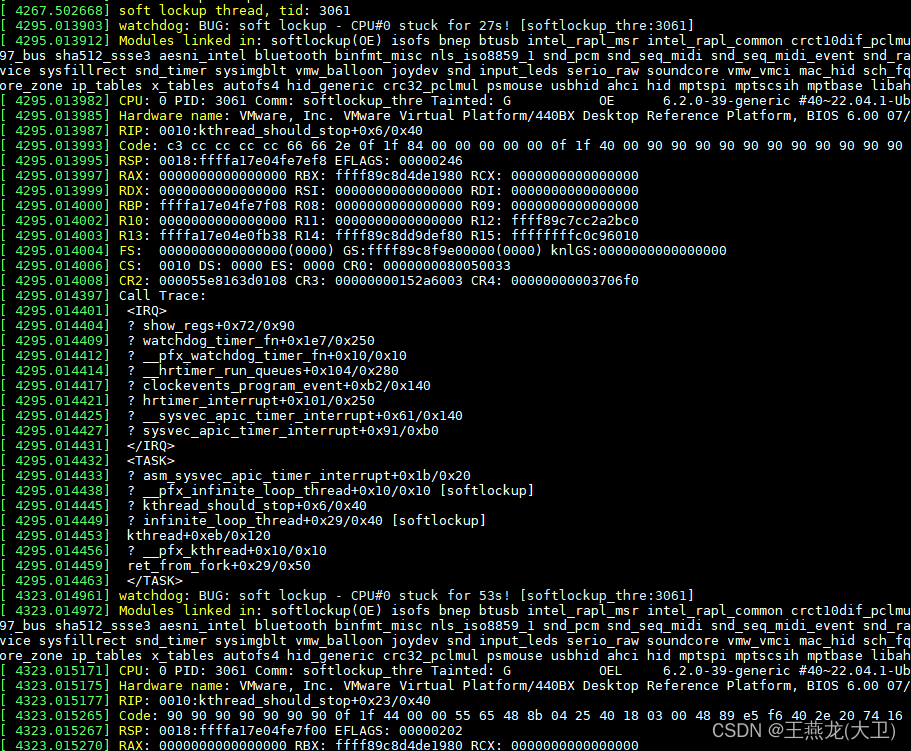
内核打印的信息如下,提示 BUG 是 soft lockup,打印了线程号,也打印出了线程的调用栈。
2.4 配置参数
| /proc/sys/kernel/watchdog_thresh | 多长时间没有调度,才算 soft lockup,超时时间就是基于这个参数来定的。默认情况下这个参数是 10s,soft lockup 的时间是这个参数的两倍,20s。 |
| /proc/sys/kernel/softlockup_panic | 发生 soft lockup 的时候要不要 panic,默认情况下是不 panic,打印错误信息。 |
| /proc/sys/kernel/soft_watchdog | soft lockup 是不是使能,默认是 1,是使能的 |
| /proc/sys/kernel/softlockup_panic | 发生 soft lockup 的时候,要不要打印所有核上的调用栈,默认是关闭的 |
3 hard lockup
3.1 检测对象
soft lockup 只是检测在一定时间内,是不是没有发生过线程调度。一般情况下,线程不调度,但是中断还是可以正常处理的。
hard lockup 是检测中断的,如果一个核上长时间没有响应中断,可能引入比较大的问题。
3.2 检测原理
hard lockup 检测机制和 soft lockup 检测机制比较类似。维护一个 counter,这个 counter 记录着中断计数。另外有一个定时器来检测,如果一定时间之内,中断计数没有更新,那么就说明没有响应中断,也就会被判定为 hard lockup。
维护中断信息的 counter 在内核中是一个 per cpu 变量 hrtimer_interrupts,这个变量的更新是在 soft lockup 中提到的定时器中进行更新的,定时器每触发一次,就会将这个变量增加 1。定时器是中断触发,所以这个变量可以表示中断响应情况。
判断是不是发生了 hard lockup 是在函数 is_hardlockup() 中判断的。从如下代码中也可以看出,如果最新的中断计数和上次的中断计数是相等的,那说明在这两次检测之间没有响应中断,也就会判为 hard lockup。
bool is_hardlockup(void)
{unsigned long hrint = __this_cpu_read(hrtimer_interrupts); if (__this_cpu_read(hrtimer_interrupts_saved) == hrint)return true;__this_cpu_write(hrtimer_interrupts_saved, hrint);return false;
}hard lockup 的检测是使用了 NMI perf event 来完成的,NMI 是不可屏蔽中断。
3.3 异常打印信息
异常打印信息在函数 watchdog_overflow_callback() 打印。
static void watchdog_overflow_callback(struct perf_event *event,struct perf_sample_data *data,struct pt_regs *regs)
{...if (is_hardlockup()) {int this_cpu = smp_processor_id();/* only print hardlockups once */if (__this_cpu_read(hard_watchdog_warn) == true)return;pr_emerg("Watchdog detected hard LOCKUP on cpu %d\n",this_cpu);print_modules();print_irqtrace_events(current);if (regs)show_regs(regs);elsedump_stack();if (sysctl_hardlockup_all_cpu_backtrace &&!test_and_set_bit(0, &hardlockup_allcpu_dumped))trigger_allbutself_cpu_backtrace();if (hardlockup_panic)nmi_panic(regs, "Hard LOCKUP");__this_cpu_write(hard_watchdog_warn, true);return;}...return;
}3.4 配置参数
| /proc/sys/kernel/watchdog_thresh | hard lockup 检测周期,默认是 10s。hrtimer_interrupts 在 watchdog_timer_fn 中更新,每 4s 更新一次。所以相邻两次检测之间至少发生 2 次中断,如果中断计数没有增长,那么就说明发生了 hard lockup |
| /proc/sys/kernel/ nmi_watchdog | 开关 |
4 workqueue stall
内核中的 workequeue 就类似于用户态使用的线程池。
线程池里边有一个队列,还有一定数量的线程。线程池的使用者向队列中提交任务,然后线程池里的线程负责执行这些任务。
对线程池里的任务有一个基本的要求就是,这个任务是可以结束的,也就是说任务中不能有死循环。但是线程池本身也无法限制用户提交什么任务,任务中有没有死循环。所以我们在用户态开发线程池的时候,有时也会开发线程池的检测逻辑,当任务提交到队列的时候加一个时间戳,检测逻辑检测线程池中任务的时间戳,根据超时时间来打印告警信息。
内核中的 workqueue stall 与我们用户态线程池的异常检测是类似的。

4.1 检测对象
内核中的 work queue,即工作队列。判断工作队列中的任务是不是很长时间都没有得到处理,如果是的话就打印告警信息。
4.2 检测原理
也是使用一个定时器来检测,定时器回调函数是 wq_watchdog_timer_fn(),定时器超时时间默认是 30s。
在操作 workqueue 的时候(入队一个 work 或者处理一个 work),更新这个 workqueue 的时间戳。在定时器中根据这个时间戳进行检测,如果时间戳和当前时间的差值超过了超时时间,那么就会打印告警信息。
4.3 异常打印信息
打印告警信息的代码如下。
static void wq_watchdog_timer_fn(struct timer_list *unused)
{...if (time_after(now, ts + thresh)) {lockup_detected = true;pr_emerg("BUG: workqueue lockup - pool");pr_cont_pool_info(pool);pr_cont(" stuck for %us!\n",jiffies_to_msecs(now - pool_ts) / 1000);}...
}这篇关于[linux][异常检测] hung task, soft lockup, hard lockup, workqueue stall的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







