本文主要是介绍挑战杯 基于大数据的社交平台数据爬虫舆情分析可视化系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- **实现功能**
- **可视化统计**
- **web模块界面展示**
- 3 LDA模型
- 4 情感分析方法
- **预处理**
- 特征提取
- 特征选择
- 分类器选择
- 实验
- 5 部分核心代码
- 6 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于大数据的社交平台数据爬虫舆情分析可视化系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
基于Python的社交平台大数据挖掘及其可视化。
2 实现效果
实现功能
- 实时热点话题检测
- 情感分析
- 结果可视化
- Twitter数据挖掘平台的设计与实现
可视化统计
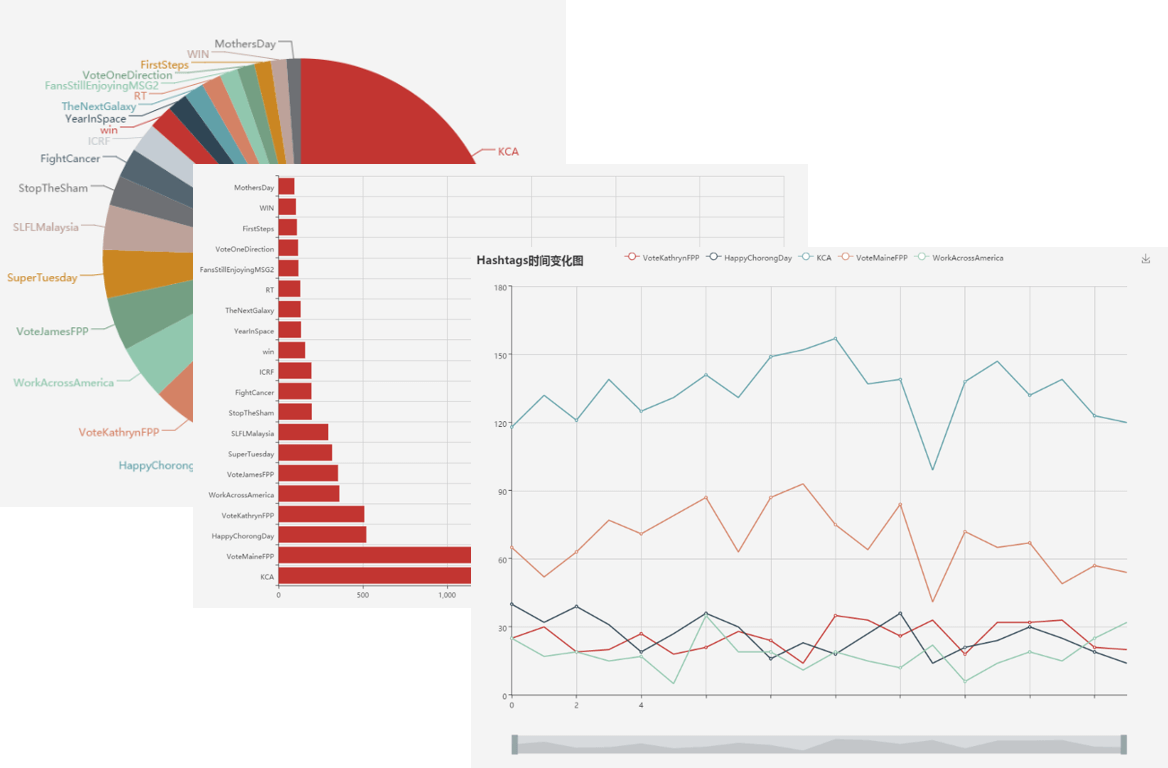
Hashtag统计
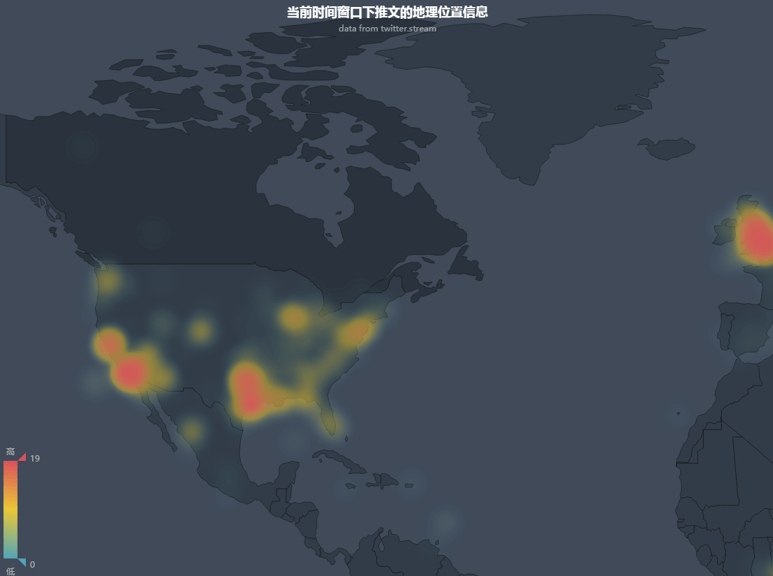
地理位置信息的可视化
话题结果可视化
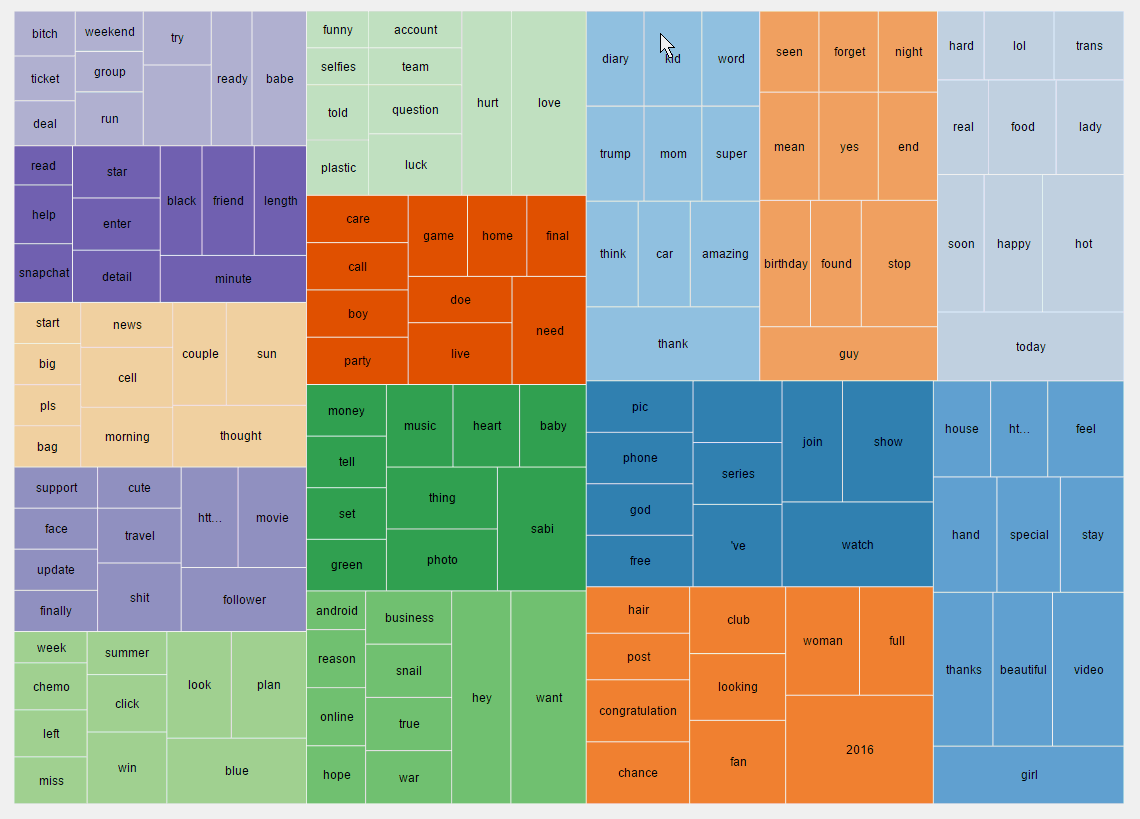
矩阵图
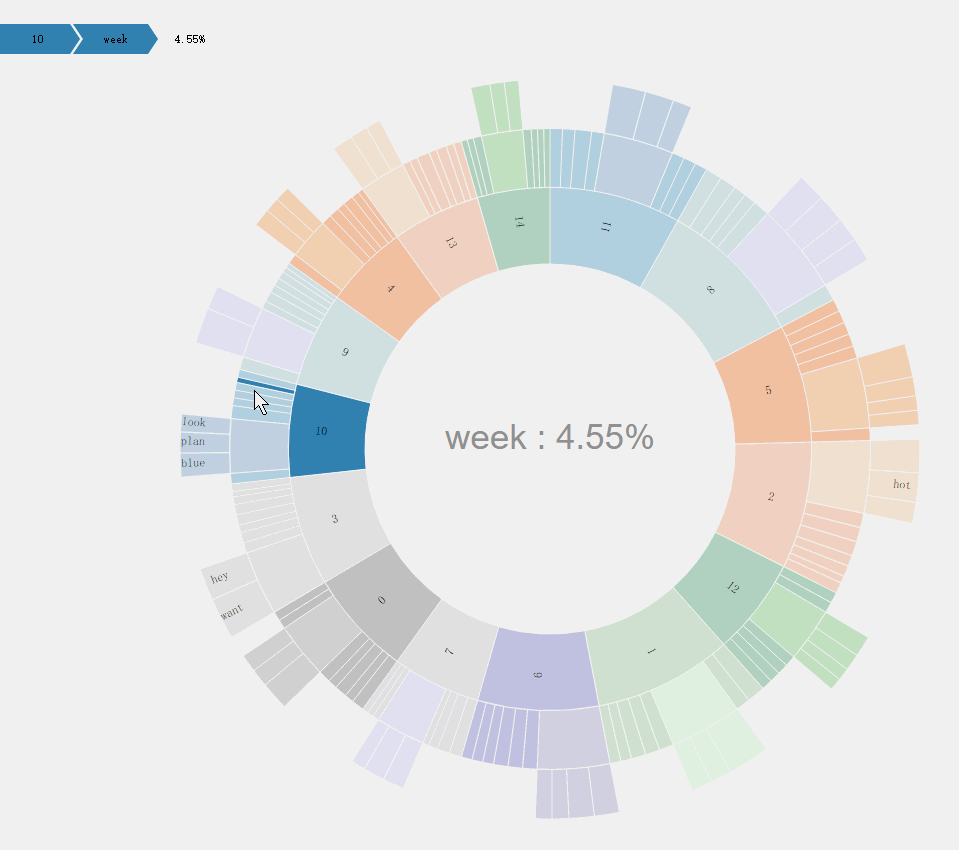
旭日图
情感分析的可视化
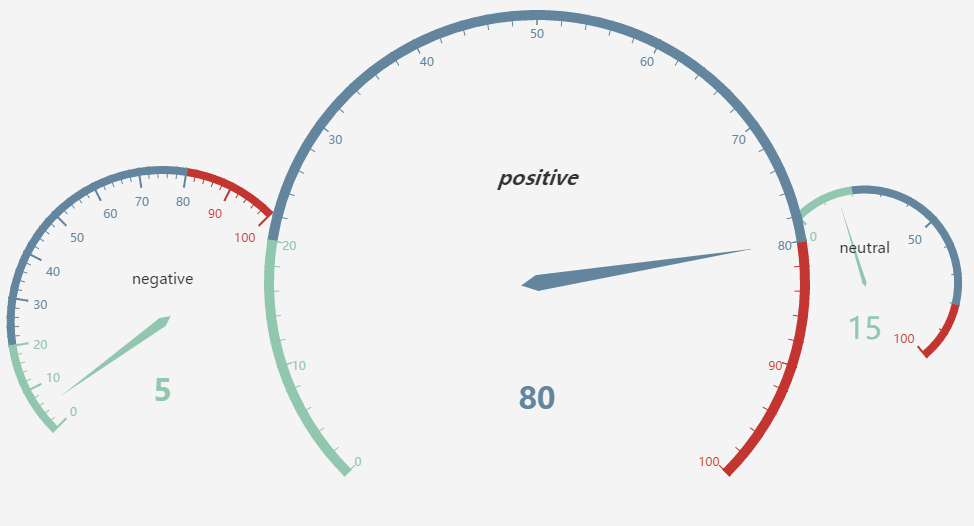
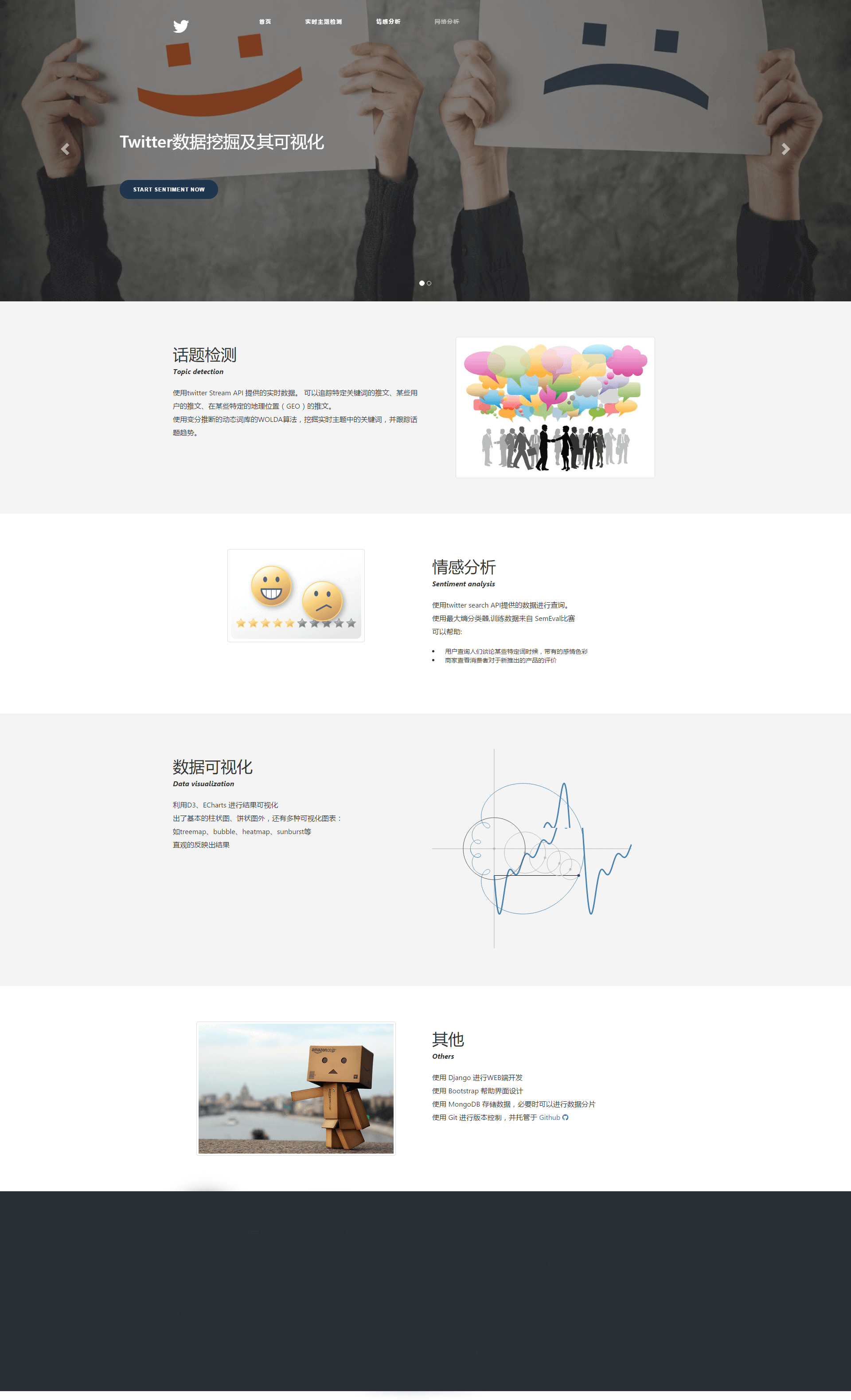
web模块界面展示
3 LDA模型
2003年,D.Blei等人提出了广受欢迎的LDA(Latentdirichlet
allocation)主题模型[8]。LDA除了进行主题的分析外,还可以运用于文本分类、推荐系统等方面。
LDA模型可以描述为一个“上帝掷骰子”的过程,首先,从主题库中随机抽取一个主题,该主题编号为K,接着从骰子库中拿出编号为K的骰子X,进行投掷,每投掷一次,就得到了一个词。不断的投掷它,直到到达预计的文本长

可以用矩阵的乘法来表示上述的过程:
回到LDA模型来说,LDA模型的输入是一篇一篇用BOW(bag of
words)表示的文档,即用该文档中无序的单词序列来表示该文档(忽略文档中的语法和词语的先后关系)。LDA的输出是每篇文档的主题分布矩阵和每个主题下的单词分布矩阵。简而言之,LDA主题模型的任务就是已知左边的矩阵,通过一些方法,得到右边两个小矩阵。这里的“一些方法”即为LDA采样的方法,目前最主要的有两种,一种是变分贝叶斯推断(variationalBayes,
VB),另一种叫做吉布斯采样(Gibbs Sampling),其中吉布斯采样也被称为蒙特卡洛马尔可夫 (Markov Chain Monte
Carlo,MCMC)采样方法。
总的来说,MCMC实现起来更加简单方便,而VB的速度比MCMC来得快,研究表明他们具有差不多相同的效果。所以,对于大量的数据,采用VB是更为明智的选择。
4 情感分析方法
本文采用的情感分析可以说是一个标准的机器学习的分类问题。目标是给定一条推文,将其分为正向情感、负向情感、中性情感。
预处理
- POS标注:CMU ArkTweetNLP
- 字母连续三个相同:替换 “coooooooool”=>“coool”
- 删除非英文单词
- 删除URL
- 删除@:删除用户的提及@username
- 删除介词、停止词
- 否定展开:将以"n’t"结尾的单词进行拆分,如"don’t" 拆分为"do not",这里需要注意对一些词进行特殊处理,如"can’t"拆分完之后的结果为"can not",而不是"ca not"。
- 否定处理:从否定词(如shouldn’t)开始到这个否定词后的第一个标点(.,?!)之间的单词,均加入_NEG后缀。如perfect_NEG。 “NEG”后缀
特征提取
文本特征
-
N-grams
- 1~3元模型
- 使用出现的次数而非频率来表示。不仅是因为使用是否出现来表示特征有更好的效果[16],还因为Twitter的文本本身较短,一个短语不太可能在一条推文中重复出现。
-
感叹号问号个数
- 在句子中的感叹号和问号,往往含有一定的情感。为此,将它作为特征。
-
字母重复的单词个数
- 这是在预处理中对字母重复三次以上单词进行的计数。字母重复往往表达了一定的情感。
-
否定的个数
- 否定词出现后,句子的极性可能会发生翻转。为此,把整个句子否定的个数作为一个特征
-
缩写词个数等
-
POS 标注为[‘N’, ‘V’, ‘R’, ‘O’, ‘A’] 个数(名词、动词、副词、代词、形容词)
-
词典特征(本文使用的情感词典有:Bing Lius词库[39]、MPQA词库[40]、NRC Hashtag词库和Sentiment140词库[42]、以及相应的经过否定处理的词库[45])
- 推文中的单词在情感字典个数 (即有极性的单词个数)
- 推文的 总情感得分:把每个存在于当前字典单词数相加,到推文的 总情感得分:把每个存在于当前 - 字典单词数相加,到推文的 总情感得分:把每个存在于当前字典单词数相加,到推文总分,这个数作为一特征。
- 推文中单词最大的正向情感得分和负。
- 推文中所有正向情感的单词分数 和以及 所有负向情感单词的分数和。
- 最后一个词的分数
-
表情特征
- 推文中正向 情感 和负向的表情个数
- 最后一个表情的极性是 否为正向
特征选择
本文 特征选择主要是针对于 N-grams 特征 的,采用方法如下:
设定min_df(min_df>=0)以及threshold(0 <= threshold <= 1)
对于每个在N-grams的词:
统计其出现于正向、负向、中性的次数,得到pos_cnt, neg_cnt, neu_cnt,以及出现总数N,然后分别计算
pos = pos_cnt / N
neg = neg_cnt / N
neu = neu_cnt / N
对于 pos,neg,neu中任一一个大于阈值threshold 并且N > min_df的,保留该词,否则进行删除。
上述算法中滤除了低频的词,因为这可能是一些拼写错误的词语;并且,删除了一些极性不那么明显的词,有效的降低了维度。
分类器选择
在本文中,使用两个分类器进行对比,他们均使用sklearn提供的接口 。第一个分类器选用SVM线性核分类器,参数设置方面,C =
0.0021,其余均为默认值。第二个分类器是Logistic Regression分类器,其中,设置参数C=0.01105。
在特征选择上,min_df=5, threshold=0.6。
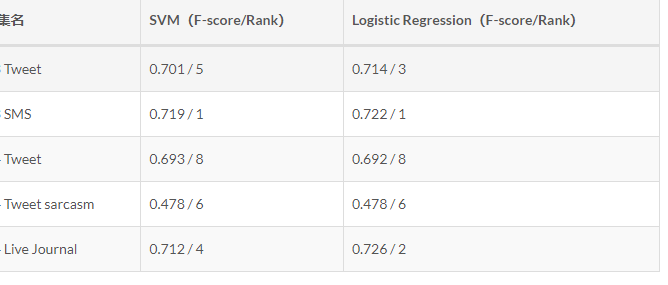
实验
- SemEval(国际上的一个情感分析比赛)训练数据和测试数据
- 评价方法采用F-score
- 对比SemEval2016结果如下
测试集名
5 部分核心代码
import jsonfrom django.http import HttpResponsefrom django.shortcuts import renderfrom topic.models.TopicTrendsManager import TopicTrendsManagerfrom topic.models.TopicParameterManager import TopicParameterManagerdef index(request):return render(request, 'topic/index.html')# TODO 检查参数的合法性, and change to post methoddef stream_trends(request):param_manager = TopicParameterManager(request.GET.items())topic_trends = TopicTrendsManager(param_manager)res = topic_trends.get_result(param_manager)return HttpResponse(json.dumps(res), content_type="application/json")def stop_trends(request):topic_trends = TopicTrendsManager(None)topic_trends.stop()res = {"stop": "stop success"}return HttpResponse(json.dumps(res), content_type="application/json")def text(request):return render(request, 'topic/visualization/result_text.html')def bubble(request):return render(request, 'topic/visualization/result_bubble.html')def treemap(request):return render(request, 'topic/visualization/result_treemap.html')def sunburst(request):return render(request, 'topic/visualization/result_sunburst.html')def funnel(request):return render(request, 'topic/visualization/result_funnel.html')def heatmap(request):return render(request, 'topic/visualization/result_heatmap.html')def hashtags_pie(request):return render(request, 'topic/visualization/result_hashtags_pie.html')def hashtags_histogram(request):return render(request, 'topic/visualization/result_hashtags_histogram.html')def hashtags_timeline(request):return render(request, 'topic/visualization/result_hashtags_timeline.html')6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
这篇关于挑战杯 基于大数据的社交平台数据爬虫舆情分析可视化系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






