本文主要是介绍Solr搜索引擎第六篇-Solr集成中文分词器IKAnalyzer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 第一步:新建java maven工程
- 第二步:定义三个java类
- 第三步:定义三个配置文件
- 第四步:打包三个类为jar
- 第五步:拷贝IKAnalyzer-lucene7.5.jar和ikanalyzer-2012_u6.jar
- 第六步:拷贝配置文件
- 第七步:定义新的FieldType
- 测试
在 Lucene搜索引擎-分词器一篇中讲述到Lucene如何集成中文分词器IKAnalyzer,这里Solr集成中文分词器IKAnalyzer是在此基础之上的,这里的solr版本为7.5。
第一步:新建java maven工程
pom.xml引入中文分词器IKAnalyzer
<!-- ikanalyzer 中文分词器 -->
<dependency><groupId>com.janeluo</groupId><artifactId>ikanalyzer</artifactId><version>2012_u6</version><exclusions><exclusion><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId></exclusion><exclusion><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId></exclusion><exclusion><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId></exclusion></exclusions>
</dependency>
第二步:定义三个java类
IKAnalyzer4Lucene7:
package com.dalomao.framework.lucene.analizer.ik;import org.apache.lucene.analysis.Analyzer;public class IKAnalyzer4Lucene7 extends Analyzer {private boolean useSmart = false;public IKAnalyzer4Lucene7() {this(false);}public IKAnalyzer4Lucene7(boolean useSmart) {super();this.useSmart = useSmart;}public boolean isUseSmart() {return useSmart;}public void setUseSmart(boolean useSmart) {this.useSmart = useSmart;}@Overrideprotected TokenStreamComponents createComponents(String fieldName) {IKTokenizer4Lucene7 tk = new IKTokenizer4Lucene7(this.useSmart);return new TokenStreamComponents(tk);}}
IKTokenizer4Lucene7:
package com.dalomao.framework.lucene.analizer.ik;import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;import java.io.IOException;public class IKTokenizer4Lucene7 extends Tokenizer {// IK分词器实现private IKSegmenter _IKImplement;// 词元文本属性private final CharTermAttribute termAtt;// 词元位移属性private final OffsetAttribute offsetAtt;// 词元分类属性(该属性分类参考org.wltea.analyzer.core.Lexeme中的分类常量)private final TypeAttribute typeAtt;// 记录最后一个词元的结束位置private int endPosition;/*** @param* @param useSmart*/public IKTokenizer4Lucene7(boolean useSmart) {super();offsetAtt = addAttribute(OffsetAttribute.class);termAtt = addAttribute(CharTermAttribute.class);typeAtt = addAttribute(TypeAttribute.class);_IKImplement = new IKSegmenter(input, useSmart);}/** (non-Javadoc)* * @see org.apache.lucene.analysis.TokenStream#incrementToken()*/@Overridepublic boolean incrementToken() throws IOException {// 清除所有的词元属性clearAttributes();Lexeme nextLexeme = _IKImplement.next();if (nextLexeme != null) {// 将Lexeme转成Attributes// 设置词元文本termAtt.append(nextLexeme.getLexemeText());// 设置词元长度termAtt.setLength(nextLexeme.getLength());// 设置词元位移offsetAtt.setOffset(nextLexeme.getBeginPosition(),nextLexeme.getEndPosition());// 记录分词的最后位置endPosition = nextLexeme.getEndPosition();// 记录词元分类typeAtt.setType(nextLexeme.getLexemeTypeString());// 返会true告知还有下个词元return true;}// 返会false告知词元输出完毕return false;}/** (non-Javadoc)* * @see org.apache.lucene.analysis.Tokenizer#reset(java.io.Reader)*/@Overridepublic void reset() throws IOException {super.reset();_IKImplement.reset(input);}@Overridepublic final void end() {// set final offsetint finalOffset = correctOffset(this.endPosition);offsetAtt.setOffset(finalOffset, finalOffset);}
}
IKTokenizer4Lucene7Factory:
package com.dalomao.framework.lucene.analizer.ik;import java.util.Map;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeFactory;public class IKTokenizer4Lucene7Factory extends TokenizerFactory
{private boolean useSmart = false;public IKTokenizer4Lucene7Factory(Map<String, String> args) {super(args);String useSmartParm = (String)args.get("useSmart");if ("true".equalsIgnoreCase(useSmartParm))this.useSmart = true;}public Tokenizer create(AttributeFactory factory){return new IKTokenizer4Lucene7(this.useSmart);}
}
第三步:定义三个配置文件
扩展词:lucene_ext.dic
厉害了我的国
停用词:lucene_ext_stopword.dic
,
?
、
我
的
你
IK配置文件:IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties> <comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">lucene_ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">lucene_ext_stopword.dic</entry>
</properties>
第四步:打包三个类为jar
将前面定义的三个类达成jar包,命名为IKAnalyzer-lucene7.5.jar。
备注:具体如何打包请参看IntelliJ IDEA单独对java类打JAR包
第五步:拷贝IKAnalyzer-lucene7.5.jar和ikanalyzer-2012_u6.jar
将这个IKAnalyzer-lucene7.5.jar和 IKAnalyzer的jar(ikanalyzer-2012_u6.jar)拷贝到solr的web应用的lib目录下(solr-7.5.0/server/solr-webapp/webapp/WEB-INF/lib)
第六步:拷贝配置文件
将之前定义的三个配置文件拷贝到solr安装目录的应用classes目录下( solr-7.3.0/server/solr-webapp/webapp/WEB-INF/classes),如果没有classes目录则需要新建
第七步:定义新的FieldType
在内核主目录下conf/managed-schema.xml文件中定义一个新的FieldType,如下:
<fieldType name="zh_CN_text" class="solr.TextField"><analyzer><tokenizer class="com.dalomao.framework.lucene.analizer.ik.IKTokenizer4Lucene7Factory" useSmart="true" /> </analyzer>
</fieldType>
测试
以上全部步骤做完以后,重启Solr服务器实例,然后登陆web测试
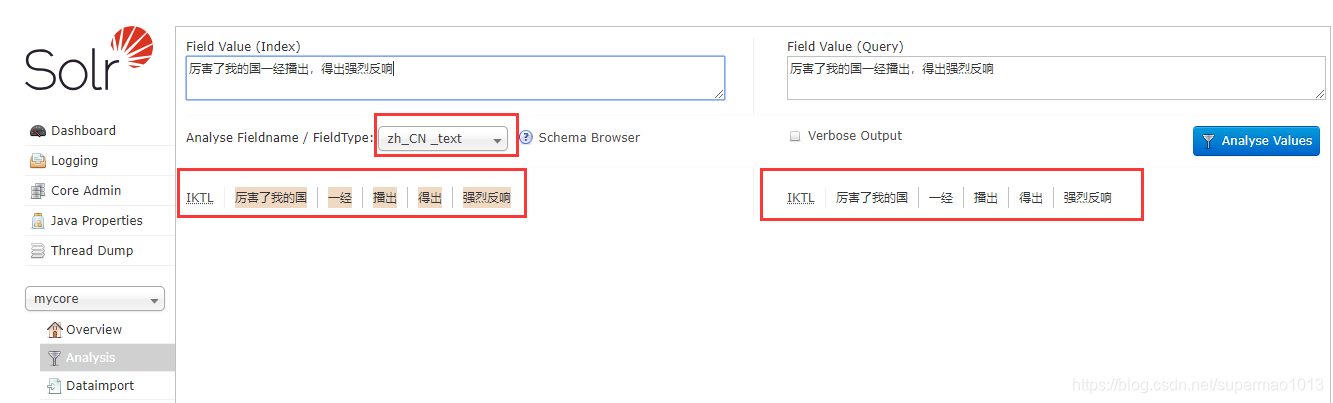
测试成功!
这篇关于Solr搜索引擎第六篇-Solr集成中文分词器IKAnalyzer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






