ikanalyzer专题

solr 错误:Caused by: org.wltea.analyzer.lucene.IKAnalyzer
一、 问题描述 CDH5.15.2的solr集群下,创建ik分词器的实例,但是报错。Ik分词器的配置文件都已经上传各个节点solr对应目录下,但是还是报错: solrctl collection --create test_ik4 -s 2 -c test_ik -r 1 -m 3报错<?xml version="1.0" encoding="UTF-8"?> <response> <

‘access denied (“java.io.FilePermission“...... “IKAnalyzer.cfg.xml“ “read“(elasticsearch很容易踩到的坑)
出现的错如下:access_control_exception', 'access denied ("java.io.FilePermission" “C:\Program%20Files\ElasticSearch\elasticsearch-7.8.1\plugins\ik\config\IKAnalyzer.cfg.xml” “read”) 刚开始碰到这个问题就立马去更改文件夹权限,然后发现
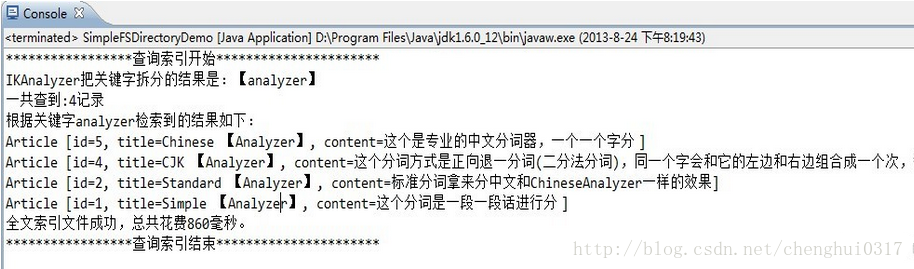
Lucene 实例教程(二)之IKAnalyzer中文分词器
转自作者:永恒の_☆ 地址:http://blog.csdn.net/chenghui0317/article/details/10281311 最近研究数据库模糊查询,发现oracle数据库中虽然可以用instr来替代like提高效率,但是这个效率提高是有瓶颈的,可以用搜索引擎技术来进一步提高查询效率 一、前言 前面简单介绍了Lucene,以及如何
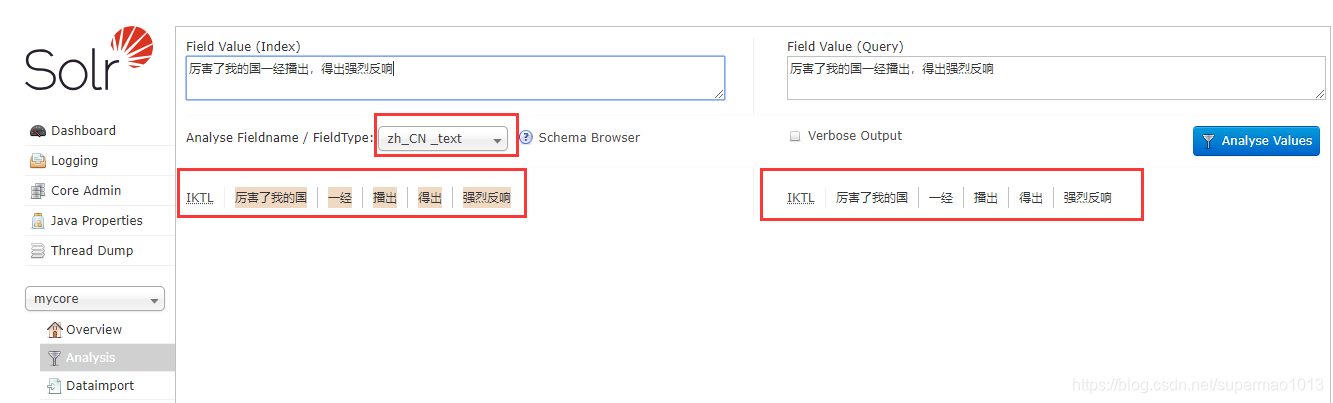
Solr搜索引擎第六篇-Solr集成中文分词器IKAnalyzer
文章目录 第一步:新建java maven工程第二步:定义三个java类第三步:定义三个配置文件第四步:打包三个类为jar第五步:拷贝IKAnalyzer-lucene7.5.jar和ikanalyzer-2012_u6.jar第六步:拷贝配置文件第七步:定义新的FieldType测试 在 Lucene搜索引擎-分词器一篇中讲述到Lucene如何集成中文分词器IKAnalyzer,
IKanalyzer 分词器(???)
//今天看了看IKanalyzer 扩充词汇看得我一头雾水 分词器的使用还没理解直接搞扩充词汇有点知识脱节 //谁能举个例看看怎么扩充???? 网上提供的方法是: .基于api 我的想法如下 利用一个数据库表保存实时动态添加的词元,如果对应的实体类有更新,就执行添加词元的操作 具体的话就是从数据库读取词元,然后存在List<String> termList,执行 Dictionary.

中文分词工具-IKAnalyzer下载及使用
关键字:中文分词、IKAnalyzer 最近有个需求,需要对爬到的网页内容进行分词,以前没做过这个,随便找了找中文分词工具,貌似IKAnalyzer评价不错,因此就下来试试,在这里记录一下使用方法,备查。 下载解压之后主要使用和依赖以下文件: IKAnalyzer2012_u6.jar — IKAnalyzer核心jar包 I

IKAnalyzer分词器jar包下载
本IKAnalyzer为solr5.5.4版本的jar文件,如其他版本请找到对应的版本。注:不同的solr版本会对应不同的IKAnalyzer中文分词器,由于不能上传jar文件,请在下载后修改文件后缀名!下载地址为:http://download.csdn.net/download/songyou05/9989018
改写IKAnalyzer分词器
ik4solr4.3 solr4.3的ik分词器([https://github.com/lgnlgn/ik4solr4.3] 主要改动不是我完成的,只是指点。使用maven) 支持从solr自己的环境中获取自定义词典(使用solr的ResourceLoader, 只需要把字典文件放到conf目录里) 增加一个定时更新的停用词、同义词工厂类 ============我是分割线

在Solr中配置中文分词IKAnalyzer
1、在配置文件schema.xml(位置{SOLR_HOME}/config/下),配置信息如下: <!-- IKAnalyzer 中文分词--> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="

Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二) 之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装。这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索。 一、创建Core: 1、首先在solrhome(solrhome的路径和配置见Solr6.5在Centos6上的安装

Lucene5学习之使用IKAnalyzer分词器
之前的示例中,使用的是默认的StandardAnalyzer分词器,不能有效的进行中文分词,下面演示下如何在Lucene5.0中使用IKAnalyzer分词器。 首先下载IKAnalyzer分词器源码,IKAnalyzer分词器源码托管在OSChina的git上。下载地址: http://git.oschina.net/wltea/IK-Analyzer-2012FF 请如图下载