solr专题

Solr 使用Facet分组过程中与分词的矛盾解决办法
对于一般查询而言 , 分词和存储都是必要的 . 比如 CPU 类型 ”Intel 酷睿 2 双核 P7570”, 拆分成 ”Intel”,” 酷睿 ”,”P7570” 这样一些关键字并分别索引 , 可能提供更好的搜索体验 . 但是如果将 CPU 作为 Facet 字段 , 最好不进行分词 . 这样就造成了矛盾 , 解决方法
Solr部署如何启动
Solr部署如何启动 Posted on 一月 10, 2013 in: Solr入门 | 评论关闭 我刚接触solr,我要怎么启动,这是群里的朋友问得比较多的问题, solr最新版本下载地址: http://www.apache.org/dyn/closer.cgi/lucene/solr/ 1、准备环境 建立一个solr目录,把solr压缩包example目录下的内容复制

大型分布式redis+solr+Linux+nginx+springmvc+mybatis电商项目
http://edu.csdn.net/course/detail/2798?locationNum=13&fps=1
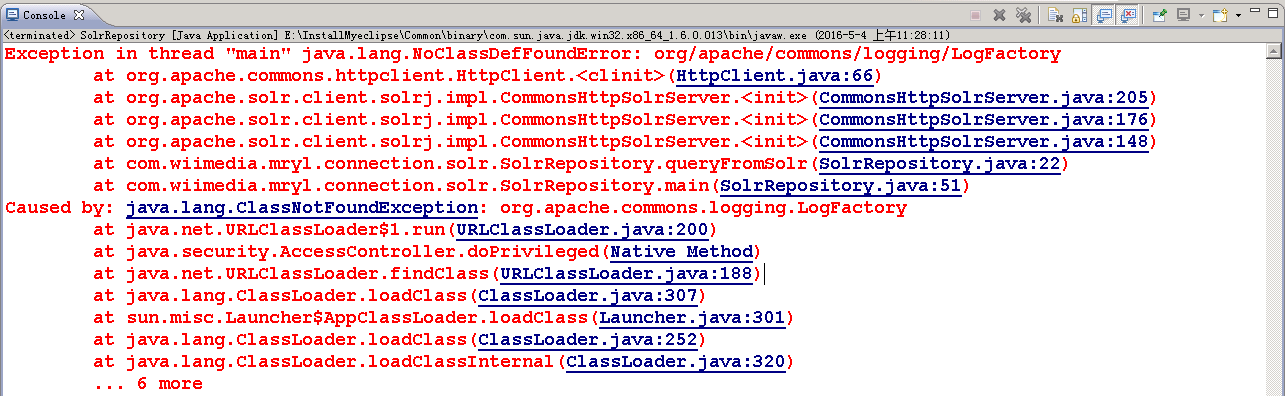
Solr使用:3.Solr添加文档到索引
1.首先在创建好的CORE中添加自己需要的Field.打开 E:\Solr2016-05-03\SolrHome\solr\MySolr\conf\schema.xml 2.用JAVA程序进行添加 2.1 需要引入的Jar包 2.2 程序代码 package com.wiimedia.mryl.connection.solr; import java.io.IOExcep
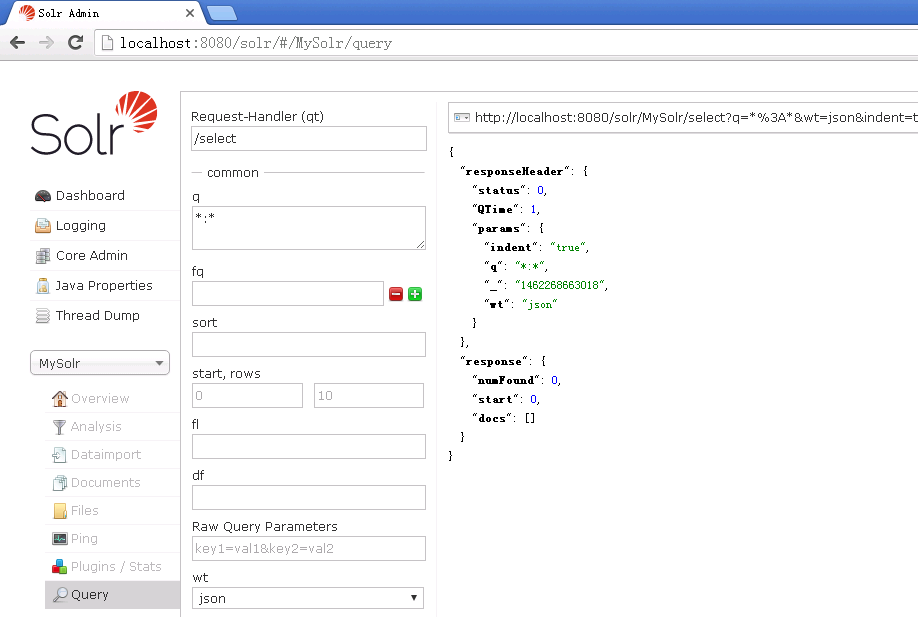
Solr使用:2.Solr核的创建
1.将 E:\Solr2016-05-03\solr-5.3.1\dist文件夹中 : (1)solr-dataimporthandler-5.3.1jar (2)solr-dataimporthandler-extras-5.3.1.jar 两个jar包复制到 E:\Solr2016-05-03\apache-tomcat-7.0.68\webapps\solr\WEB-INF\li

Solr高亮及搜索逻辑探寻
Solr高亮及搜索逻辑探寻 原文:http://leoluo.top/2017/11/21/Solr%E6%95%B0%E5%AD%97%E9%AB%98%E4%BA%AE%E5%BC%82%E5%B8%B8/ Blog:Why So Serious Github: LeoLuo22 CSDN: 我的CSDN 0x00 前言 马上就要发版本了,这次版本要新上对产品和功能
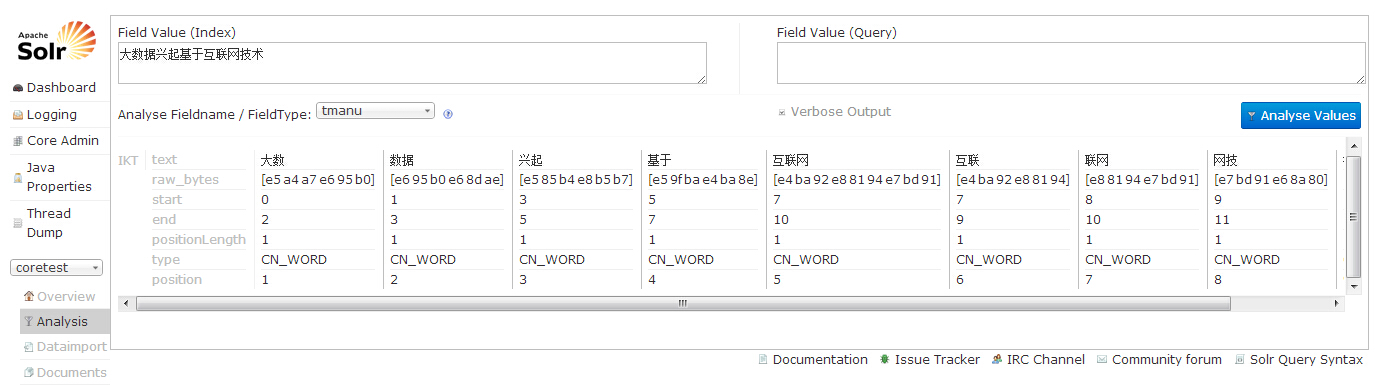
solr环境搭建(三)
前一篇链接 http://blog.csdn.net/u013252072/article/details/50070213 前一篇已经介绍介绍如何添加collection,本篇接上篇介绍如何添加IKAnalyzer分词器 下载IKAnalyzer所需要的jar包和文件 1、解压IKAnalyzer.zip 2、将IKAnalyzer2012FF_u1.jar放在t
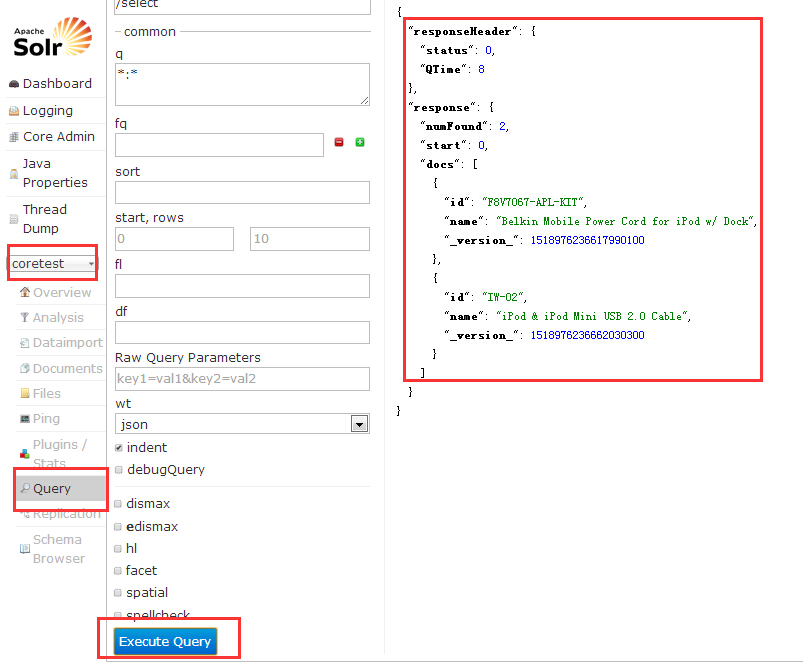
solr环境搭建(二)
前一篇链接 http://blog.csdn.net/u013252072/article/details/50069861 前一篇已经介绍solr环境是如何搭建,本篇接上篇介绍如何添加collection 1、在E:\solr\solrhome目录下,新建一个coretest文件夹。 2、在解压的solr-4.10.0\example\multicore\core0目录中,复

solr环境搭建(一)
1、到apache下载solr,地址: http://mirrors.hust.edu.cn/apache/lucene/solr/ 2、解压出solr-4.10.0 3、复制solr-4.10.0\example\webapps中的solr.war文件到tomcat安装目录中的webapps文件夹下 4、运行tomcat。(忽略怎么运行tomcat),tomcat会自动解
转发 Elastic Search 和 Solr 你用哪个?
1、搜索引擎选择: Elasticsearch与Solr 链接 2、ElasticSearch(ES)和solr的关系和区别 链接 3、[译]ElasticSearch vs. Solr 链接 4、全文搜索引擎 Elasticsearch 入门教程 链接
solr安装(windows版)
首先需要在 http://archive.apache.org/dist/lucene/solr/ 下载solr-4.10.3.zip 下载完毕后解压solr-4.10.3.zip 这是解压后的solr文件结构 打开example目录 webapps文件夹下有个solr.war solr文件夹是solrhome的例子目录 将solr.war包解压到tomca
Solr如何使用in语法查询
Solr可以用 AND、|| 布尔操作符 表示查询的并且, 用OR、&& 布尔操作符 表示或者 用NOT、!、-(排除操作符不能单独与项使用构成查询)表示非 如果要用在查询的时候使用类似sql的in(1,2,3,4) 可以这样post_id:(1,2,3,4)或者post_id:1 OR post_id:2 OR post_id:3 OR post_id:4

Solr8如何加密Solr的DataInputHandler(DIH)使用的数据库密码
问题背景: 最近有个之前的项目在做等保,漏扫发现solr数据导入配置文件中会暴露数据库密码,很不安全,要求整改,需要将配置文件中的数据库密码加密,于是调查了一下解决方案,发现官方提供了解决方案。 官方解决方案地址:文档地址 具体步骤如下图所示: 解释一下: 第一步:此步分为三小步 1.创建文件/var/solr/data/dih-encryptionkey,用于存放加密秘钥 2.授

服务器(5)--搭建Solr集群+搭建Zookeeper集群(下篇)
背景:看完《服务器(5)--搭建Solr集群+搭建Zookeeper集群(上篇)》是不是很想知道,Solr集群的搭建过程,别急别急,下面就给大家详细的介绍一下Solr集群的搭建过程。 一、Solr集群的搭建 第一步:安装四个tomcat,修改其端口号不能冲突。8080~8083 tomcat01:(02,03,04的端口号依次加一)

【taotao】solr
【solr】 Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请 求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式 的返回结果。 【特点】 1. 高效、灵活的缓存功能 2. 垂直搜索功能 3. 高亮显示搜索结果 4. 通过索引复制提高高可用

solr - defType - 查询权重排序
Solr的defType有dismax/edismax两种,这两种的区别,可参见:http://blog.csdn.net/duck_genuine/article/details/8060026 下面示例用于演示如下场景: 有一网站,在用户查询的结果中,需要按这样排序: VIP的付费信息需要排在免费信息的前头点击率越高越靠前发布时间越晚的越靠前 这样的查询排序使用
window下部署Solr
主要步骤如下: 1、下载solr-4.7.2.zip;下载地址:http://archive.apache.org/dist/lucene/java/ 2、解压缩solr-4.7.2.zip,解压后目录结构如下: 3、将example/webapps目录下的solr.war复制到tomcat的webapps目录中; 4、启动tomcat服务器,这时候会报错,暂时不用管,只是为了解
apache lucene solr 官网历史版本下载地址
lucene的历史版本下载地址: http://archive.apache.org/dist/lucene/java/ solr的历史版本下载地址: https://archive.apache.org/dist/lucene/solr/


solr单机环境的搭架(1)
一配置solr环境 1.下载solr 2.配置solr(最好单独分离出一个tomcat,一台机器启动多个tomcat参见:http://www.cnblogs.com/lxlwellaccessful/p/6746341.html) a.在下载的solr文件夹下的\example\solr\下将文件全部考到一个文件夹中(本人是放在E:\MySoft\solr\home中的)
Solr集群的搭建和使用(2)
1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使 用SolrCloud来满足这些需求。 SolrCloud是基于Solr和Zookeeper的分布式搜索

【Solr 学习笔记】Solr 源码启动教程
Solr 源码启动教程 本教程记录了如何通过 IDEA 启动并调试 Solr 源码,从 Solr9 开始 Solr 项目已由 ant 方式改成了 gradle 构建方式,本教程将以 Solr 9 为例进行演示,IDE 选择使用 IntelliJ IDEA。 Solr github 地址:https://github.com/apache/solr JDK 版本:jdk17 关于系统版本可以参考:
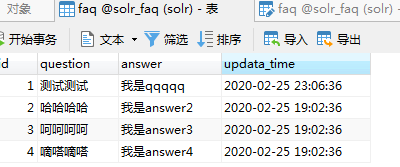
AnyQ如何配置solr动态读取数据库——AnyQ系列之二
一、anyq容器host模式运行 由于anyq容器,后期还会有其他端口需要访问,比如solr的webapp页面端口就是8900,等等。所以可以采用host方法run一个新的容器。 #提交anyq镜像,生成新镜像anyq-host,并run新的anyq-host容器docker stop anyqdocker commit anyq anyq-host#使用--privileged=tru

Solr集群(即SolrCloud)搭建与使用
1、什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用
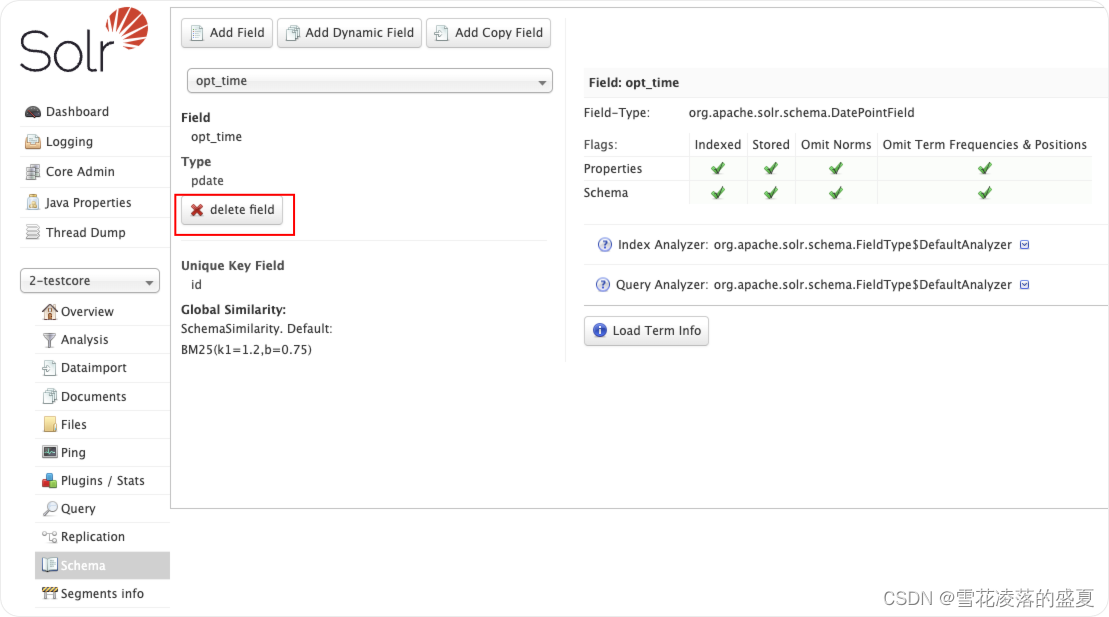
Solr7.4.0报错org.apache.solr.common.SolrException
文章目录 org.apache.solr.common.SolrException: Exception writing document id MATERIAL-99598435990497269125316 to the index; possible analysis error: cannot change DocValues type from NUMERIC to SORTED_