1、什么是SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。
当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息。
2)自动容错。
3)近实时搜索。
4)查询时自动负载均衡。
注意:一般使用zookeeper,就是将他当作一个注册中心使用。SolrCloud使用zookeeper是使用其的管理集群的,请求过来,先连接zookeeper,然后再看看分发到那台solr机器上面,决定了那台服务器进行搜索的,对Solr配置文件进行集中管理。
2、zookeeper是个什么玩意?
顾名思义zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小猪)的管理员, Apache Hbase和 Apache Solr 的分布式集群都用到了zookeeper;Zookeeper:是一个分布式的、开源的程序协调服务,是hadoop项目下的一个子项目。
3、SolrCloud结构
SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud需要由多台服务器组成,由zookeeper来进行协调管理。
下图是一个SolrCloud应用的例子: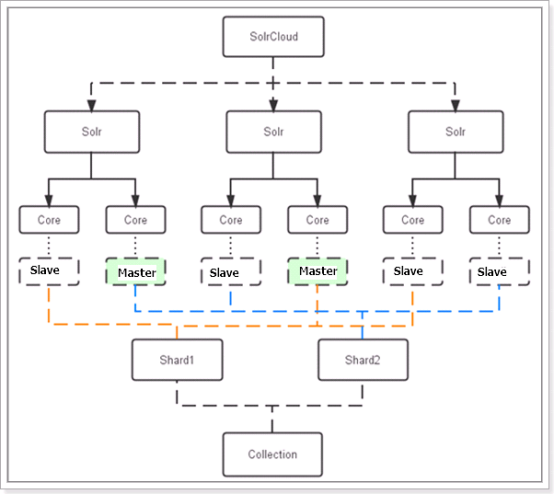
对上图进行图解,如下图所示:
1 1)、物理结构 2 三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。 3 2)、逻辑结构 4 索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。 5 用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。 6 a、collection 7 Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。 8 比如:针对商品信息搜索可以创建一个collection。 9 collection=shard1+shard2+....+shardX 10 b、Core 11 每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。 12 c、Master或Slave 13 Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。 14 d、Shard 15 Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。 16 注意:collection就是一个完整的索引库,分片存储,有两片,两片的内容不一样的。一片存储在三个节点,一主两从,他们之间的内容就是一样的。
如下图所示: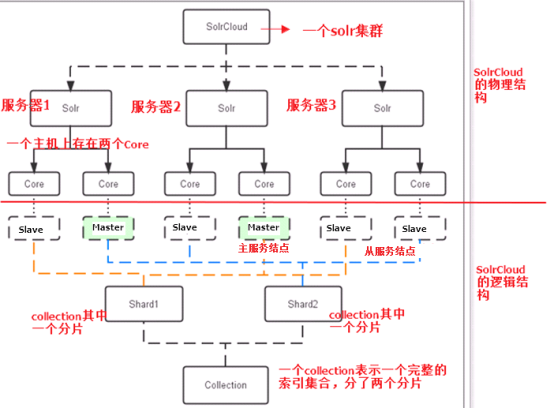
4、SolrCloud搭建
本教程的这套安装是单机版的安装,所以采用伪集群的方式进行安装,如果是真正的生成环境,将伪集群的ip改下就可以了,步骤是一样的。
SolrCloud结构图如下:
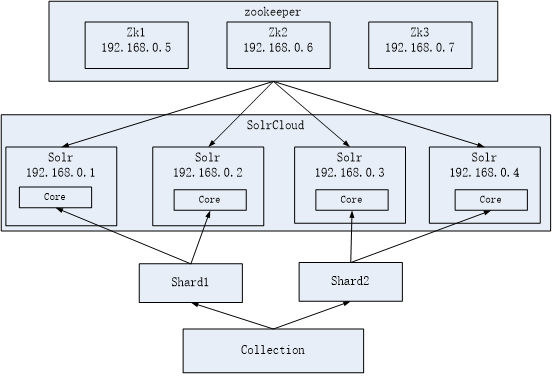
环境准备,请安装好自己的jdk。
注意,我搭建的是伪集群,一个虚拟机,分配了1G内存,然后搭建的集群。
5、zookeeper集群安装。
第一步:解压zookeeper,tar -zxvf zookeeper-3.4.6.tar.gz将zookeeper-3.4.6拷贝到/usr/local/solr-cloud下,复制三份分别并将目录名改为zookeeper1、zookeeper2、zookeeper3。
1 # 首先将zookeeper进行解压缩操作。 2 [root@localhost package]# tar -zxvf zookeeper-3.4.6.tar.gz -C /home/hadoop/soft/ 3 # 然后创建一个solr-cloud目录。 4 [root@localhost ~]# cd /usr/local/ 5 [root@localhost local]# ls 6 bin etc games include lib libexec sbin share solr src 7 [root@localhost local]# mkdir solr-cloud 8 [root@localhost local]# ls 9 bin etc games include lib libexec sbin share solr solr-cloud src 10 [root@localhost local]# 11 # 复制三份分别并将目录名改为zookeeper1、zookeeper2、zookeeper3。 12 [root@localhost soft]# cp -r zookeeper-3.4.6/ /usr/local/solr-cloud/zookeeper1 13 [root@localhost soft]# cd /usr/local/solr-cloud/ 14 [root@localhost solr-cloud]# ls 15 zookeeper1 16 [root@localhost solr-cloud]# cp -r zookeeper1/ zookeeper2 17 [root@localhost solr-cloud]# cp -r zookeeper1/ zookeeper3
第二步:进入zookeeper1文件夹,创建data目录。并在data目录中创建一个myid文件内容为"1"(echo 1 >> data/myid)。
1 [root@localhost solr-cloud]# ls 2 zookeeper1 zookeeper2 zookeeper3 3 [root@localhost solr-cloud]# cd zookeeper1 4 [root@localhost zookeeper1]# ls 5 bin CHANGES.txt contrib docs ivy.xml LICENSE.txt README_packaging.txt recipes zookeeper-3.4.6.jar zookeeper-3.4.6.jar.md5 6 build.xml conf dist-maven ivysettings.xml lib NOTICE.txt README.txt src zookeeper-3.4.6.jar.asc zookeeper-3.4.6.jar.sha1 7 [root@localhost zookeeper1]# mkdir data 8 [root@localhost zookeeper1]# cd data/ 9 [root@localhost data]# ls 10 [root@localhost data]# echo 1 >> myid 11 [root@localhost data]# cat myid
第三步:进入conf文件夹,把zoo_sample.cfg改名为zoo.cfg。
1 [root@localhost zookeeper1]# ls 2 bin CHANGES.txt contrib dist-maven ivysettings.xml lib NOTICE.txt README.txt src zookeeper-3.4.6.jar.asc zookeeper-3.4.6.jar.sha1 3 build.xml conf data docs ivy.xml LICENSE.txt README_packaging.txt recipes zookeeper-3.4.6.jar zookeeper-3.4.6.jar.md5 4 [root@localhost zookeeper1]# cd conf/ 5 [root@localhost conf]# ls 6 configuration.xsl log4j.properties zoo_sample.cfg 7 [root@localhost conf]# mv zoo_sample.cfg zoo.cfg 8 [root@localhost conf]# ls 9 configuration.xsl log4j.properties zoo.cfg 10 [root@localhost conf]#
第四步:修改zoo.cfg。
修改:dataDir=/usr/local/solr-cloud/zookeeper1/data
注意:clientPort=2181(zookeeper2中为2182、zookeeper3中为2183)
可以在末尾添加这三项配置(注意:2881和3881分别是zookeeper之间通信的端口号、zookeeper之间选举使用的端口号。2181是客户端连接的端口号,别搞错了哦):
server.1=192.168.110.142:2881:3881
server.2=192.168.110.142:2882:3882
server.3=192.168.110.142:2883:3883
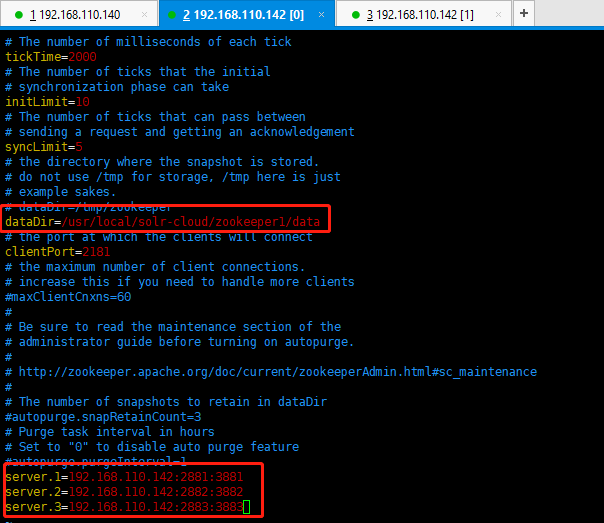
第五步:对zookeeper2、zookeeper3中的设置做第二步至第四步修改。
zookeeper2修改如下所示:
a)、myid内容为2
b)、dataDir=/usr/local/solr-cloud/zookeeper2/data
c)、clientPort=2182
Zookeeper3修改如下所示:
a)、myid内容为3
b)、dataDir=/usr/local/solr-cloud/zookeeper3/data
c)、clientPort=2183
1 [root@localhost conf]# cd ../../zookeeper2 2 [root@localhost zookeeper2]# ls 3 bin CHANGES.txt contrib docs ivy.xml LICENSE.txt README_packaging.txt recipes zookeeper-3.4.6.jar zookeeper-3.4.6.jar.md5 4 build.xml conf dist-maven ivysettings.xml lib NOTICE.txt README.txt src zookeeper-3.4.6.jar.asc zookeeper-3.4.6.jar.sha1 5 [root@localhost zookeeper2]# mkdir data 6 [root@localhost zookeeper2]# cd data/ 7 [root@localhost data]# ls 8 [root@localhost data]# echo 2 >> myid 9 [root@localhost data]# ls 10 myid 11 [root@localhost data]# cat myid 12 2 13 [root@localhost data]# ls 14 myid 15 [root@localhost data]# cd .. 16 [root@localhost zookeeper2]# ls 17 bin CHANGES.txt contrib dist-maven ivysettings.xml lib NOTICE.txt README.txt src zookeeper-3.4.6.jar.asc zookeeper-3.4.6.jar.sha1 18 build.xml conf data docs ivy.xml LICENSE.txt README_packaging.txt recipes zookeeper-3.4.6.jar zookeeper-3.4.6.jar.md5 19 [root@localhost zookeeper2]# cd conf/ 20 [root@localhost conf]# ls 21 configuration.xsl log4j.properties zoo_sample.cfg 22 [root@localhost conf]# mv zoo_sample.cfg zoo.cfg 23 [root@localhost conf]# ls 24 configuration.xsl log4j.properties zoo.cfg 25 [root@localhost conf]# vim zoo.cfg 26 [root@localhost conf]# cd ../.. 27 [root@localhost solr-cloud]# ls 28 zookeeper1 zookeeper2 zookeeper3 29 [root@localhost solr-cloud]# cd zookeeper3 30 [root@localhost zookeeper3]# ls 31 bin CHANGES.txt contrib docs ivy.xml LICENSE.txt README_packaging.txt recipes zookeeper-3.4.6.jar zookeeper-3.4.6.jar.md5 32 build.xml conf dist-maven ivysettings.xml lib NOTICE.txt README.txt src zookeeper-3.4.6.jar.asc zookeeper-3.4.6.jar.sha1 33 [root@localhost zookeeper3]# mkdir data 34 [root@localhost zookeeper3]# ls 35 bin CHANGES.txt contrib dist-maven ivysettings.xml lib NOTICE.txt README.txt src zookeeper-3.4.6.jar.asc zookeeper-3.4.6.jar.sha1 36 build.xml conf




