本文主要是介绍基于深度强化学习的海战场目标搜寻路径规划,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
源自:系统工程与电子技术
作者:杨清清 高盈盈 郭玙 夏博远 杨克巍
摘 要
海战场是未来大国冲突的主阵地之一, 强大的海战场目标搜寻能力是执行海上训练和作战的最后一道屏障, 同时也因其复杂多变的环境和重要战略地位成为战场联合搜救中最艰难最核心的部分。面向海战场目标搜寻的存活时间短、实时性要求高等特点, 提出一种基于深度强化学习的海战场目标搜寻规划方法。首先, 构建了海战场目标搜寻场景数学规划模型, 并将其映射为一种强化学习模型; 然后, 基于Rainbow深度强化学习算法, 设计了海战场目标搜寻规划的状态向量、神经网络结构以及算法框架与流程。最后, 用一个案例, 验证了所提方法的可行性与有效性, 与常规应用的平行搜寻模式相比大大提高了搜寻成功率。
关键词
海战场 ; 目标搜寻 ; 路径规划 ; 动态规划 ; 深度强化学习
引言
海战场越来越成为大国军事对抗的主战场, 海战场目标搜寻是海上作战的重要构成要素, 是待救军事人员的最后一道希望, 随着以人为本理念的深入, 海上搜救问题得到越来越多的关注。当遇险目标位置不明时, 须进行海上搜寻。海上搜寻在整个搜救过程中是最昂贵、最危险和最复杂的部分, 也是发现和救助遇险目标的唯一途径。海战场搜救行动成功与否的关键在于搜寻预案的制定, 目前实际搜救过程中搜寻方案的制定过多依赖于主观决策者的主观判断和历史的经验指导, 行动的组织存在一定的盲目性, 搜寻任务规划缺乏系统性。因此, 研究定量化的搜寻预案设计方法与技术, 建立科学、高效、易实施的海战场搜寻方法至关重要[1]。
在调研过程中发现, 海战场待搜寻目标具有存活时间短、待搜寻区域广、探测概率低、漂流轨迹难以预测等特征, 要求目标搜寻规划方法必须能够快速响应, 且支持实时规划[2]。但是当前我国海战场目标搜寻能力距离国际先进水平尚有一定差距[3]。在实际搜救过程中, 针对未知位置的海上目标搜寻问题, 大多仍然采用机械的覆盖搜寻方法, 效率较低, 且难以准确量化实时调整搜寻方案。在研究方面, 传统的目标搜寻规划求解方法, 如精确优化算法、启发式算法、元启发式算法等只能针对明确的搜寻场景进行求解, 而无法应对搜寻态势实时变化的情形[4]。且由于无人机的快速发展, 传统搜寻模式和研究方法均不太适用于基于无人机的灵活多变的搜寻模式需求。而强化学习是一种不断与环境交互反馈, 调整自身策略以应对环境变化的动态规划方法, 得到了多种实际场景的应用验证[5-8], 适用于海战场目标搜寻路径规划问题的优化求解。因此, 可结合强化学习等智能方法拓展搜寻方案的制定方法, 设计海战场目标搜寻的快速响应算法, 提高搜寻效率, 进而提升海上作战效能。
当前的深度强化学习方法一般分为两种: 价值学习和策略学习[9]。为了能在有限计算条件下, 快速获得较为精确的计算结果, 本文将海战场待搜寻区域进行网格化处理, 同时将搜寻主体的动作空间离散化, 缩小决策空间, 适用于采用基于价值的学习方法。基于价值的深度强化学习方法代表性算法是深度Q网络(deep Q-network, DQN)算法[10]。
然而, DQN基于使用单个价值网络的训练效率较低, 且完整的分布信息很大程度上被丢失[8]。为了解决DQN算法本身存在的不足, 后续研究者对其进行了大量改进, 如优先Q网络[11]、双Q网络[12]、竞争Q网络结构[13]等。近年, 也有学者提出分布式Q学习算法[14]、噪声网络结构[15]。但是以上这些算法都可以在某个方面提升DQN的性能, 而且都是基于同一个网络框架。Hessel等将上述所有方法进行整合, 提出通用性很强的Rainbow算法[16], 引入多步学习机制[17-18], 可以在训练前期更准确地估计目标价值以加快训练速度, 在学习效率和学习效果上都优于其他算法[19]。
本文面向海战场目标搜寻规划问题, 考虑问题的快速响应和实时规划要求, 构建了具有典型海战场搜救场景特征的搜寻模型, 研究基于深度强化学习的规划方法, 旨在实现搜寻规划的实时性、高效性和精确性, 为提升我国海战场目标搜寻成功率提供先进方法参考与算法支撑。
1 海战场目标搜寻模型
首先, 构建海上搜寻地图维护模型, 对搜寻环境进行形式化描述, 并对搜寻概率更新机制进行建模。基于搜寻理论和搜寻代价进行目标函数建模。通过构建以上数学模型, 量化搜寻过程中的任务进展程度和目标满足程度。本文考虑无人机的快速响应能力、广域搜寻能力、长距通信能力等优势, 假设其为海战场目标搜寻的主要设备。
1.1 海上搜寻地图的形式化描述
将任务区域E划分成Lx×Ly个网格, 如图 1所示。每个网格都是独立的, 将每个网格的中心点坐标作为该网格的位置坐标。假设初始先验信息已知, 每个栅格(m, n)赋予一定的目标包含概率(probability of contain, POC)初始值pmn, 即目标存在于该栅格的概率[20], (m, n)的取值范围为m∈{1, 2, …, Lx}, n∈{1, 2, …, Ly}。
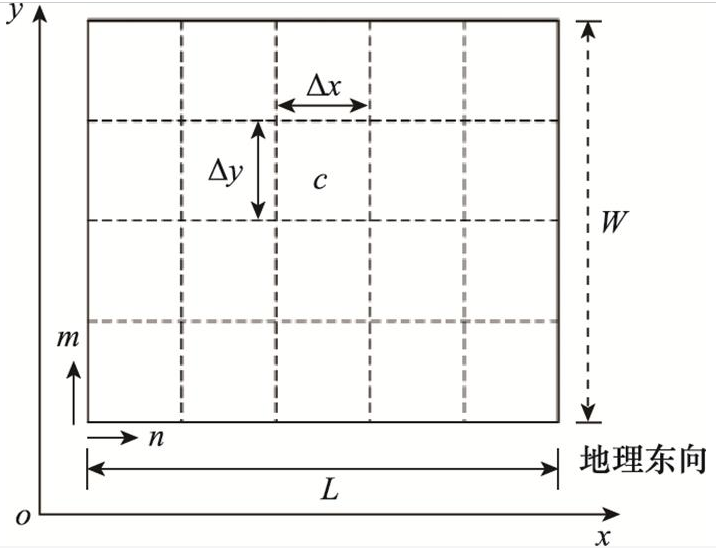
图1 搜寻地图形式化描述示意图
本文假定待搜寻区域100%包含失事目标, 因此整个待搜寻区域的POC为1。假设初始先验信息已知, 且已进行归一化处理, 即满足:

(1)
1.2 搜寻概率地图更新机制
待搜寻目标的漂流轨迹预测是海上搜救的一个重要研究方向, 在实际搜寻过程中, 每个栅格的目标存在概率会随着海流、海浪、潮汐等影响因素的改变而变化, 实时获取POC矩阵需要结合海上部署传感器、气象卫星等多源信息的处理, 计算复杂度较高[21]。本文重点验证算法的适用性和有效性, 简化了实时变化因素。为了降低计算复杂性, 仅考虑搜寻行动对目标存在概率值所产生的后验影响, 忽略海洋环境因素的影响。
若无人机在一定时间内完成了对待搜寻区域的搜寻任务后没有发现遇险目标, 则需要更新待搜寻区域的POC矩阵, 并建立下一时刻的目标存在概率模型。目标存在于子区域(m, n)内的先验概率为pmn, 则在(m, n)中搜寻到目标的概率P(Smn)表示为

(2)
其中, POD(S|pmnT)为目标真实存在于子区域(m, n), 且被无人机发现的概率。
当目标类型和无人机搜寻方式固定时, 搜寻目标发现概率(probability of detection, POD)函数相对固定。假设无人机在栅格内执行搜寻任务, 满足Koopman的3个随机搜寻条件, 则可得无人机的目标探测概率函数为
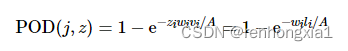
(3)
式中: v为无人机i的飞行速度; z为无人机i的飞行时间; l为无人机i在时间内搜寻航行的总路程; w为无人机i的探测宽度即扫海宽度; A为搜寻栅格单元的面积; j为搜寻单元数(j=1, 2, …, xy)。式(3)中,扫海宽度是经过大量的搜救实验以及通过对历史搜救案例的总结得出的, 一般情况下, 可以通过查表得出[22]。
当无人机完成对(m, n)区域的搜寻后但未搜寻到目标时, 可基于贝叶斯原理更新目标存在于各个子区域的后验概率p′mn。若子区域已经被无人机搜寻, 则p′mn表示无人机完成对子区域(m, n)的搜寻且未搜寻到目标的条件下, 目标仍存在于(m, n)区域内的概率; 若(m, n)未被无人机搜寻, 此时p′mn表示POC矩阵更新后目标存在于子区域(m, n)的概率。p′mn计算过程如下所示:
(1) 当(m, n)被搜索过, 但没有发现目标, 则目标仍旧存在于(m, n)的概率为
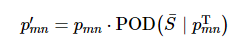
(4)
(2) 当(m, n)未被搜索过, 则目标存在于(m, n)的新概率p′mn则为POC矩阵归一化后(m, n)位置处的概率。
1.3 目标搜寻规划模型
常规的海战场目标搜寻方式仅确定待搜寻区域, 再利用平行线等固定搜寻模式来规划搜寻路径, 导致搜寻成功率(probability of success, POS)较低[23]。为此, 有必要以目标存在概率模型为基础, 在待搜寻区域E内规划搜寻路径。
因此, 海战场目标搜寻的规划模型即为: 在无人机有限的航程内, 对无人机的搜寻路径方案x进行规划, 以最大化目标发现的POS, 如下所示:

(5)
式中: x(m, n)为无人机是否搜寻子区域(m, n), 若是则为1, 否则为0;length(x) < L表示无人机搜寻路径长度小于其航程L。
2 海战场无人机搜寻目标的强化学习模型
2.1 环境空间
海洋监测中心通常基于蒙特卡罗随机粒子法进行漂流模拟得到海上遇险目标的POC矩阵, 并利用栅格法将待搜寻海域划分为若干子海域, 构建二维海洋环境栅格地图[23]。将目标海域E划分成Lx×Ly个栅格, 将每个网格的中心点坐标作为该网格的位置坐标。假设初始先验信息已知, 赋予每个子区域(m, n)一定的初始POC值pmn。每一个单元(m, n)都有一个属性值r, 表示子区域(m, n)的状态值, rmn(t)=-1表示t时刻以前子区域(m, n)已被无人机搜寻过, rmn(t)=1表示t时刻下无人机正处于子区域(m, n), rmn(t)=0表示t时刻及以前子区域(m, n)均未被搜寻过。
2.2 动作空间
动作空间的定义会影响到无人机路径规划的效果。如图 2所示, 将360°划分n等份, 角度间隔α=360°/n。假设n=8, 则α=45°。在每个决策时间点, 无人机可以采取以下行动, 比如: 左偏αik、直行或右偏αik。为方便建模, 无人机i的动作空间可表示为aik=[uik], 动作决策变量aik={1, 2, …, 8}, 分别表示: 上、右上、右、右下、下、左下、左和左上[24]。
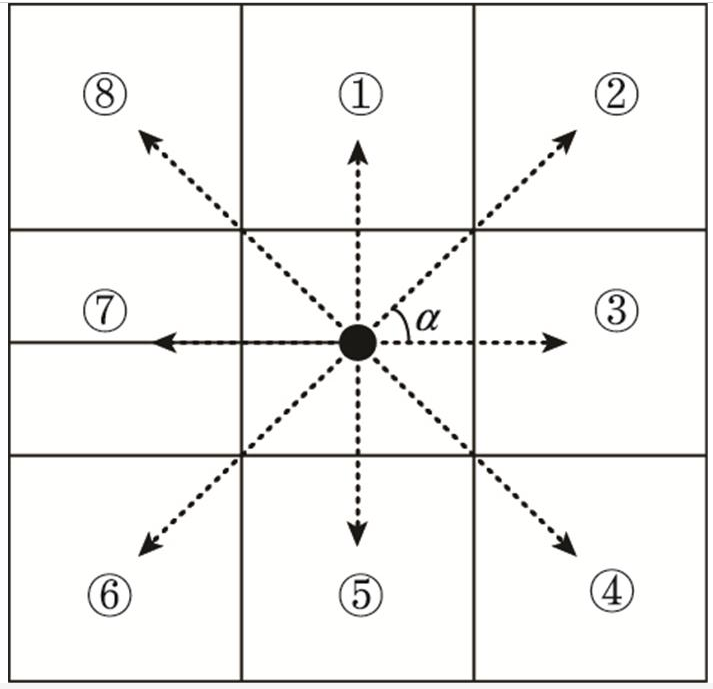
图2 动作空间
2.3 奖惩函数设计
在强化学习过程中, 无人机搜寻获取奖励值的大小不仅取决于学习算法的优劣, 也与奖励函数的定义密切相关[25]。强化学习算法通过设置奖励函数对无人机所做动作进行定量化评价, 引导整个无人机的搜寻路径学习过程。强化学习算法的总体目标是引导无人机获取最大的累计奖励值, 也就是找到一条由起始点至目标点的最优[26]。因此, 设计合适的奖励函数对于无人机在不同环境状态下的学习效果好坏具有重要意义[27]。
本文针对海上目标搜寻的实际情况, 基于最优搜寻理论中POC和POS等重要参数概念设立奖励机制, 并与稀疏奖赏函数相结合设计碰撞惩罚机制[28]。且在模型训练过程中奖励分为两个部分, 一个是针对每个行动的即时奖励, 另一个是针对整个行动回合表现的回合奖励。
2.3.1 即时奖励
{R1, R2, …,RL}表示无人机在一个回合(L步)中每一步的即时奖励集合。为尽量避免无人机重复往返同一子海域, 设置已搜寻过的海域搜寻效益奖励为rpunish。同时, 为避免无人机绕出目标海域或者进入危险区和障碍区, 同样设置越界惩罚为rpunish。随着搜寻时间的增加, 子区域(m, n)的pmn将以一定比例g(0 < g < 1)逐渐衰减, g值在搜寻开始前根据搜救情况具体设定, 设计第L步的即时奖励函数[23]如下:

(6)
2.3.2 奖励再分配
每个动作的最终奖励是对应即时奖励和回合奖励的加成。由于回合奖励是整个回合中所有动作的结果, 因此利用折扣因子对回合奖励进行重新分配: rt+γT-t·R, 其中γ为折扣因子。这种折扣计算方式假设越早阶段的动作对回合奖励的贡献越小, 折扣越大, 而越靠近回合结束时的阶段动作对回合奖励的贡献越大, 折扣越小。每个动作的最终奖励是相应即时奖励和折扣回合奖励的总和。
3 基于Rainbow的海战场目标搜寻规划深度强化学习算法
2018年, DeepMind在DQN的基础上提出了一种融合6个改进机制的基于价值的深度强化学习方法: Rainbow。其中融合的改进机制分别为: 双Q网络、优先经验回放、对决网络、多步学习、分布式学习、噪声网络。Rainbow被证明在多个基准测试中优于其他基于价值的深度强化学习算法[16]。因此, 本节采用Rainbow的思想设计海战场目标搜寻规划的深度强化学习算法。
3.1 状态向量设计
根据海战场目标搜寻规划问题的参数信息, 设置环境的当前状态包含区域大小、区域当前POC矩阵、区域各栅格是否被搜索过、当前动作、初始位置等信息。为了方便神经网络输入, 将状态信息转化成张量形式, 如表 1所示。

表1 状态向量规范化描述
3.2 带Noise、Dueling和Distributional的神经网络结构设计
3.2.1 利用噪声改进原始DQN的神经网络参数
假设原网络的参数为θ, 针对输入向量x, 有:
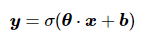
(7)
式中: σ是激活函数; y是输出向量。
为了增加神经网络的随机性, 鼓励智能体进行更广泛的探索, 一个有效方法是对θ增加随机噪声, 即θ=μ+σ°ξ, μ和σ分别是神经网络θ的均值和标准差, ξ是随机噪声, °表示点乘。增加噪声后的神经网络被称为噪声网络, 其对应的参数为θN=(θ, ξ), 参数数量比原始DQN多一倍。
3.2.2 利用对决对网络结构进行改进
对决网络对原始DQN的最外一层进行了扩展: 将原有神经网络的隐藏层连接到价值和优势两个独立部分, 然后, 将这两个部分结合起来后全连接到输出层, 如图 3所示。

图3 对决网络结构示意图
令对决神经网络的参数为θD, 其中价值网络为θV, 优势网络为θA, 则最优动作价值函数的对决神经网络预测定义为
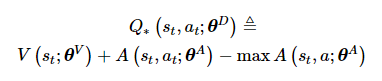
(8)
公式的最后一项是为了防止V和A的随意波动产生的不唯一性。在工程实现时, 右侧的
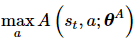
通常替换为, 以取得更好的效果。
3.2.3 改原有DQN中神经网络的值输出为值分布输出
在值分布神经网络中, 输入依旧是一个状态st, 输出则变成一个矩阵, 矩阵的一行代表一个动作对应价值的概率分布, 如图 4所示。

图4 值分布网络结构示意图
假设动作空间有m个动作, 针对每个动作的价值有N种可能取值z=[z1, z2, …, zN], 则针对每个动作a则有一个概率分布向量p=[p1a, p2a, …, pNa], 满足如下定义:
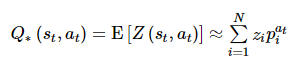
(9)
经过上述噪声、对决和值分布3种方法的加成, 原DQN的神经网络参数θ就变成θN2D, 后续将以θN2D作为神经网络的结构进行算法设计。
3.3 算法框架与流程
结合Rainbow算法和DQN基本思想, 设计海战场目标搜寻规划深度强化学习算法框架, 如图 5所示。

图5 海战场目标搜寻规划深度强化学习算法框架
具体流程如下。
步骤1 构建两个相同结构的神经网络: 预测网络θPN2D和目标网络θTN2D, 并初始化参数。
步骤2 根据当前观测状态st, 利用预测网络θPN2D预测无人机搜寻动作空间的值分布, 然后基于式(9)计算每个无人机搜寻动作的期望价值。
步骤3 根据ε-greedy策略, 从无人机搜寻动空间中选择一个动作at。
步骤4 产生新的状态st+1。
步骤5 若回合没有结束, 获取环境输出的临时奖励rt, 若回合结束, 获取环境输出的临时奖励rt和回合奖励Rt。
步骤6 更新当前状态为st+1, 并输入预测网络θPN2D, 转到步骤2。
步骤7 当回合结束时, 重新计算该回合所有动作的奖励值:

(10)
式中: r′t是每个状态下采取动作的最终回报值; λ(T-t)是奖励的折扣因子, 其作用是将回合奖励Rt更多地分配给后期的动作, 更少地分配给前期的动作。
步骤8 将[st、at、st+1、rt ]存储到记忆库中。
以上步骤是智能体与环境交互的过程, 每经过一定数量的交互, 智能体根据存储在记忆库中的轨迹数据, 对神经网络进行训练, 如下述步骤所示。
步骤9 利用优先经验回放策略从记忆库中采样数据。为记忆库中的每一条记忆赋予权重, 依据是导致预测值严重偏离目标值的那些情况应该是重点关注和训练的。因此, 首先计算预测网络的预测值和目标网络的目标值:
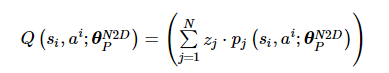
(11)
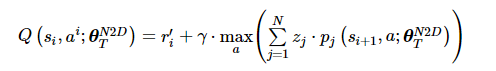
(12)
据此, 计算预测值和目标值的偏离程度:

(13)
然后, 计算每条记录被选中的概率, 与偏离程度的绝对值正相关, 满足:
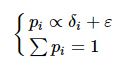
(14)
式中: ε为一个极小值, 避免概率为0。
然后, 按照概率从记忆库中抽样。
步骤10 将采样后的数据[si, ai, si+1, ri ]分别输入到预测网络θPN2D和目标网络θTN2D, 预测网络的预测值分布输出为
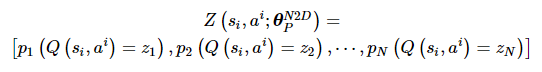
(15)
再根据目标网络θTN2D计算目标值分布:
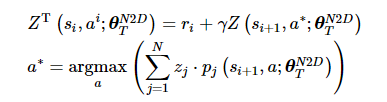
(16)
由于ZT(si, ai; θTN2D)的分布中的每一项都是pj(Q(si, ai)=ri+γzj), 因此需要与pj(Q(si, ai)=zj)对齐, 经过对齐调整之后, ZT(si, ai; θTN2D)变为ZHT(si, ai; θTN2D)。
步骤11 根据预测网络θPN2D和目标网络θTN2D的输出计算KL(Kullback-Leibler)散度。

(17)
步骤12 将KL散度作为损失函数, 对预测网络θPN2D进行训练, 损失函数关于参数θPN2D的梯度为

(18)
根据该梯度, 对θPN2D的参数执行一步梯度下降:

(19)
式中: α是深度神经网络的学习率。
4 实例应用研究
4.1 示例描述
本文以一次民用渔船海上事故为例, 对本文所提算法进行示例研究。2018年6月27日3时许, “碧海159”轮与木质渔船“鲁沾渔5186”在渤海湾(38°16′.0N, 118°08′.8E)处(套尔河2号浮和3号浮之间水域)发生碰撞, 商船轮舱破损进水, 宣布弃船求生, 渔船翻扣。商船上有船员23名, 渔船上9人。现场西南风4~5级, 能见度良好。3:30时,经评估, 此险情属船舶碰撞特大险情, 险情指挥由山东省海上搜救中心负责。海事部门和水产渔业部门投入了大量飞机和船舶开展了联合搜寻工作, 也协调了大型过往商船协助搜救。但是由于失事附近海域的海况开始变得恶劣, 成为搜救工作的一大难点。因此, 本文拟根据此案例背景采用所提出的算法调用无人机开展遇险目标搜寻工作。本文的训练样本数据参考北海预报中心提供的基于漂流预测模型的预测结果样本特征, 随机生成符合实际目标存在情况的概率密度值。
4.2 搜寻态势初始化
根据国家海上搜救环境保障服务平台的海洋气象数据, 获取在渤海海域该船舶发横侧翻的事故信息, 获得搜救信息为预测落水人员可能存在于一个15 nmile×20 nmile的连续海域内。在该海域内负责搜寻任务的无人机的起始位置随机产生, 设置栅格比例为1∶1, 即一个单位时间段内, 无人机可搜寻范围为1 nmile2。根据信息安全保密原则, 本文将样本数据脱敏后映射为特征相似的概率矩阵, 图 6为无人机开始搜寻时构建的POC矩阵热力图。

图6 搜寻区域POC预测热力图
图 7为搜救平台预测得到的落水人员初始POC分布, 图 8为归一化过后的POC分布,分别如下所示。
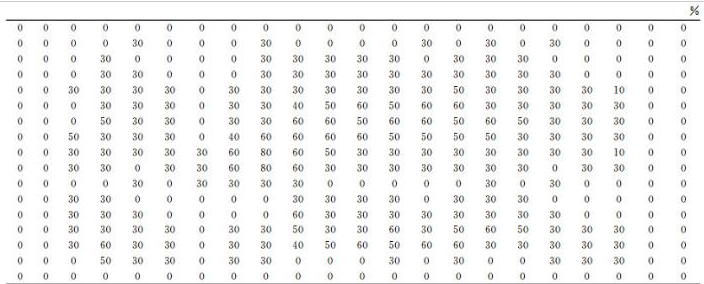
图7 搜救场景中预测得到的初始POC矩阵
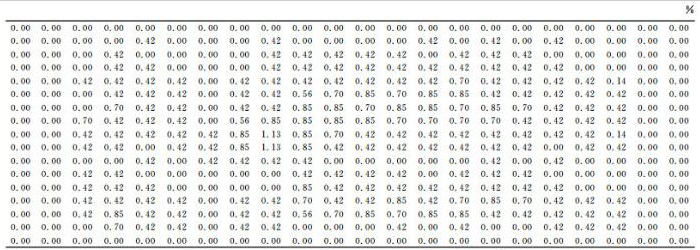
图8 归一化后的POC矩阵
4.3 参数设置
设无人机续航能力为20、30、40步(1步代表 1个栅格), 分析在不同续航能力情况下的优化结果, 算法其他参数设置如表 2所示。

表2 各项实验参数设置
4.4 实验结果展示与分析
4.4.1 损失函数与奖励函数曲线
损失函数曲线是评价算法是否收敛的重要依据, 奖励函数曲线是评价算法训练效果的依据。因此, 绘制训练过程的损失函数和奖励函数曲线图, 分别如图 9和图 10所示。

图9 不同航程下的损失值曲线
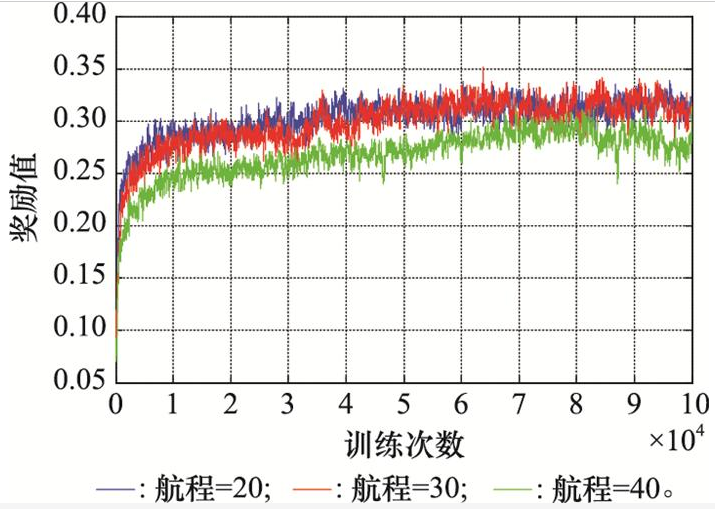
为了方便展示, 图 9只展示了2 000次训练的收敛曲线, 可以看出, Rainbow算法在不同航程情形下均能够快速收敛。图 10展示了每100次训练的平均奖励值, 可以看出, Rainbow算法在105次训练过程中能够稳步提升训练效果, 训练前期的提升效果较快, 后期提升越来越缓慢。
4.4.2 与其他搜寻模式的对比分析
针对本文所提出的算法, 与当前海上搜救实际业务中常用的平行搜寻模式[2]和基于遗传算法(genetic algorithm, GA)获取的近似最优搜寻路径进行对比。在相同的初始位置(1, 1)和相同的搜寻环境下对比搜索效果, 如图 11所示。

图11 不同航程下的测试结果
图 11(a)~图 11(c)分别表示3种搜寻模式的累计POC成功率对比, 图 11(d)~11(f)分别表示3种搜寻模式的搜寻路径。从中可以看出, 本文所提的智能搜寻模式在30步和40步的情况下效果最优, 在20步情况下, GA的效果最优。其原因在于GA的输入是初始POC矩阵, 且在优化过程中无法更新, 而Rainbow算法每个步骤观察到的都是最新的POC矩阵, 因此能够在后期搜索期间做出更合理的决策。实验显示出深度强化学习算法能够应对动态变化的环境。
图 11(d)~图 11(f)中, 蓝色箭头和线条表示基于常规平行搜寻模式产生的搜寻路径, 绿色箭头和线条表示基于Rainbow算法产生的搜寻路径, 红色箭头和线条表示基于GA产生的搜寻路径。可直观看出, 常规搜寻模式的路径较为规则, 但无法尽快搜寻到重点海域。相比之下, 基于Rainbow和GA的搜寻路径可使无人机快速覆盖目标存在概率最大的海域, 但GA无法应对动态变化的环境要素, 在实际应用中面临环境变化时往往需要重新进行优化, 而Rainbow则可以面对动态环境进行实时决策。
5 结束语
本文面向海战场目标搜寻规划问题, 考虑问题求解的快速响应性和实时动态性要求, 提出一种基于Rainbow深度强化学习算法的海战场目标搜寻规划方法, 构建了海战场目标搜寻规划的强化学习模型与深度强化学习算法。案例分析中, 验证了所提算法能够在经过一定训练后稳定收敛, 训练后的强化学习智能体在各种航程条件下的效果均优于常规平行线搜寻模式。下一步研究应考虑多个多种类型搜寻设备同时进行搜寻的情形, 也将考虑更贴合实际海洋搜寻环境的仿真模型, 基于多智能体深度强化学习方法研究海战场多设备目标搜寻规划方法, 进一步提升海战场目标搜寻的成功率和效率。
本文仅用于学习交流,如有侵权,请联系删除 !!
这篇关于基于深度强化学习的海战场目标搜寻路径规划的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




