本文主要是介绍locust能监控服务器性能吗,重新定义 Locust 的测试报告_性能监控平台,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
当我们使用 Locust 做性能压测的时候,压测的过程和展示如下:
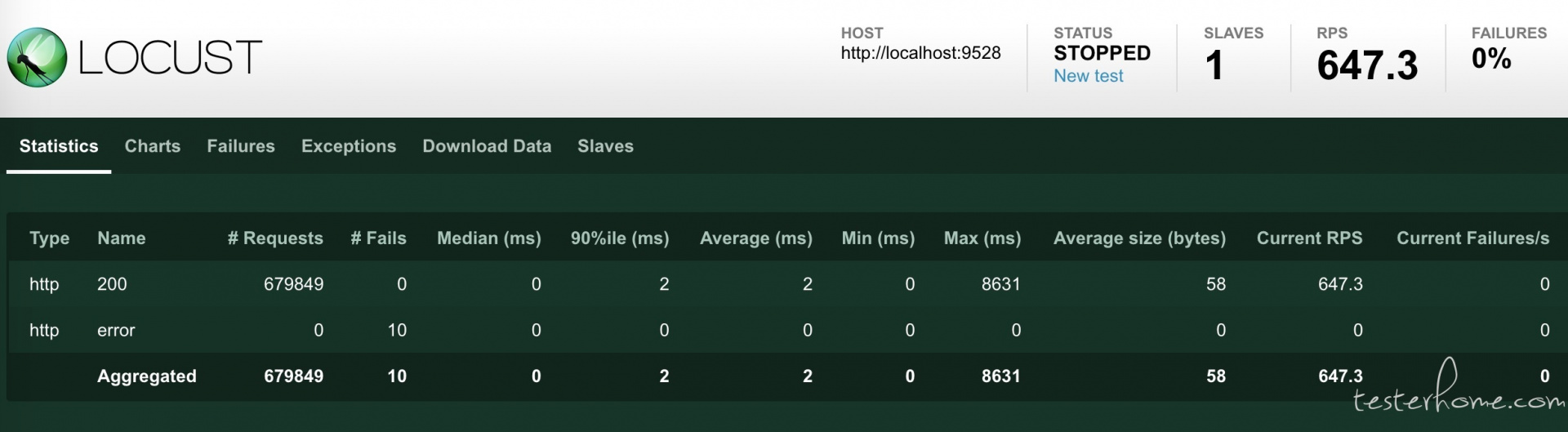
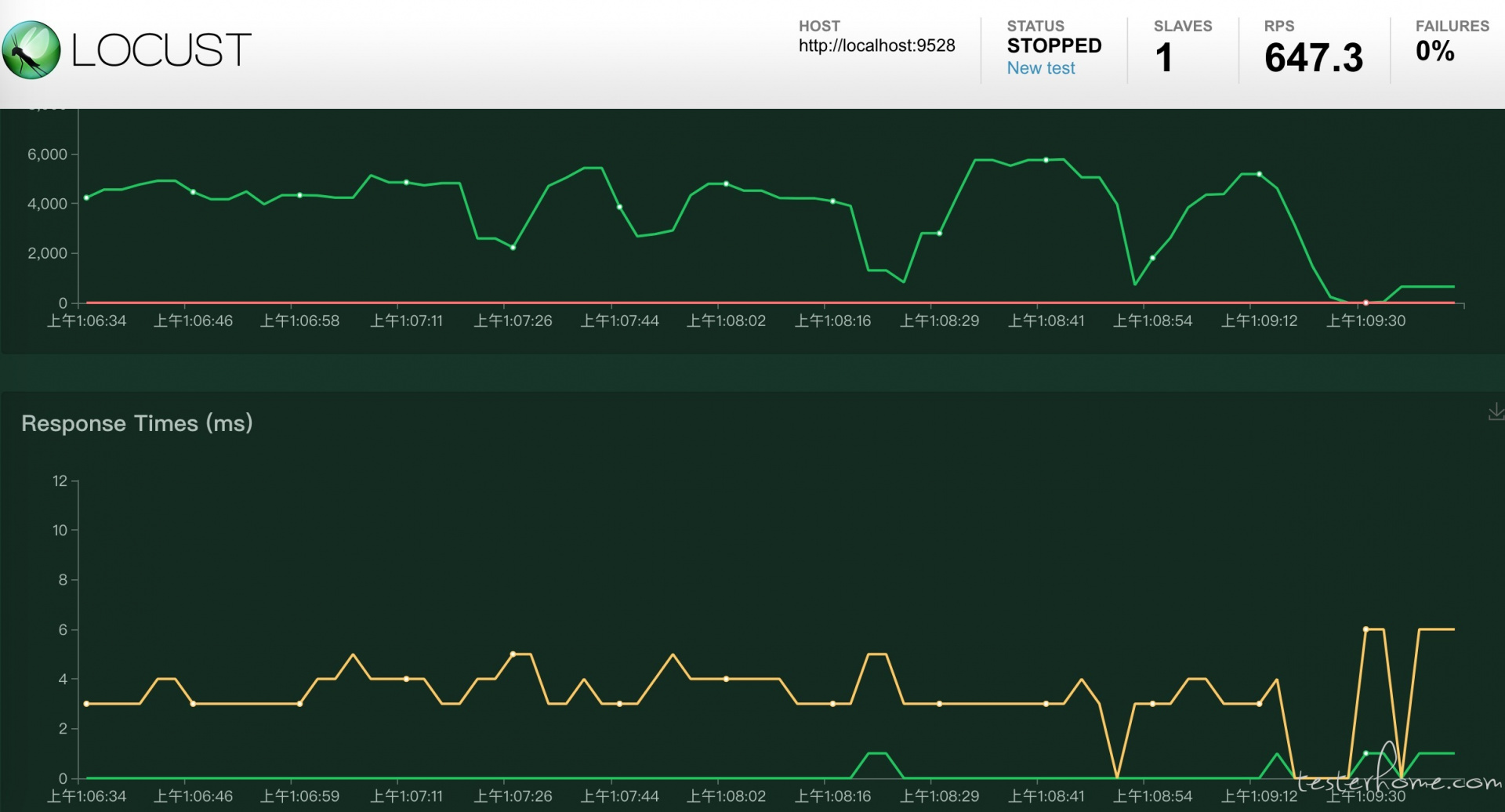
其中波动图是非持久化存储的,也就是刷新后,波动图就清空了。尽管 Statistics 中显示的信息比较完整,但是都是瞬时值,并不能体现出时序上的变化。像 Failures、Exceptions、Slaves 分在不同的 tag 查看起来也比较麻烦。Locust 的测试报告也只有简单的 csv 文件,需要下载。
从上面我们可以看到 Locust 虽然提供了跨平台的 web 模式的性能监控和展示,但是有以下明显缺陷:
rps、平均响应时间波动图没有持久化存储,刷新后便丢失
整体统计信息只是表格的形式,不能体现波动时序
测试报告过于简陋且只有文字版,只能下载存档
方案
方案其实很多,但为了减少投入成本和最大化利用现用的开源工具,选择以下方案:
Locust + Prometheus + Grafana
简单总结起来就是:
实现一个Locust的prometheus的exporter,将数据导入prometheus,然后使用grafana进行数据展示。
不难发现 Jmeter 在网上有许多类似方案的介绍,但很遗憾的是我没有找到很好实现 Locust 监控平台的方案。
搜索了一圈后发现 boomer 项目下有一个年久失修的 exporter 实现——prometheus_exporter.py, 而且作者并没有提供 grafana 之类的 Dashboard 设置,因此决定基于他的基础上,继续完成整个流程,我将在下面讲述。
Docker 环境
Docker 环境不是必须的,但是用过都说好。我们这次实战是在 docker 中完成的,因为它实在是太方便了,如果你也想快速尝试一下本文的监控平台方案,建议先准备好 docker 环境。
编写 exporter
如 Locust 的官方文档所介绍的 Extending Locust 我们可以扩展 web 端的接口,比如添加一个 /export/prometheus 接口,这样 Prometheus 根据配置定时来拉取 Metric 信息就可以为 Grafana 所用了。这里需要使用 Prometheus 官方提供的 client 库,prometheus_client,来生成符合 Prometheus 规范的 metrics 信息。
在 boomer 原文件的基础上我做了一些修改和优化,在 Readme 中添加了 Exporter 的说明,并提交 Pull Request。由于篇幅原因这里不展示代码了,完整代码(基于 Locust 1.x 版本)可以查看这里prometheus_exporter
为了方便演示,下面编写一个基于 Python 的 locustfile 作为施压端,命名为 demo.py:
#!/usr/bin/env python
# coding: utf-8
"""
Created by bugVanisher on 2020-03-21
"""
from locust import HttpLocust, TaskSet, task, between
class NoSlowQTaskSet(TaskSet):
def on_start(self):
# 登录 data = {"username": "admin", "password": "admin"}
self.client.post("/user/login", json=data)
@task(50)
def getTables(self):
r = self.client.get("/newsql/api/getTablesByAppId?appId=1")
@task(50)
def get_apps(self):
r = self.client.get("/user/api/getApps")
class MyLocust(HttpUser):
task_set = NoSlowQTaskSet
host = "http://localhost:9528"
我们把 master 跑起来,启动两个 worker。
# 启动master
locust --master -f prometheus_exporter.py
# 启动worker
locust --slave -f demo.py
在没有启动压测前,我们浏览器访问一下
http://127.0.0.1:8089/export/prometheus
返回结果如下:
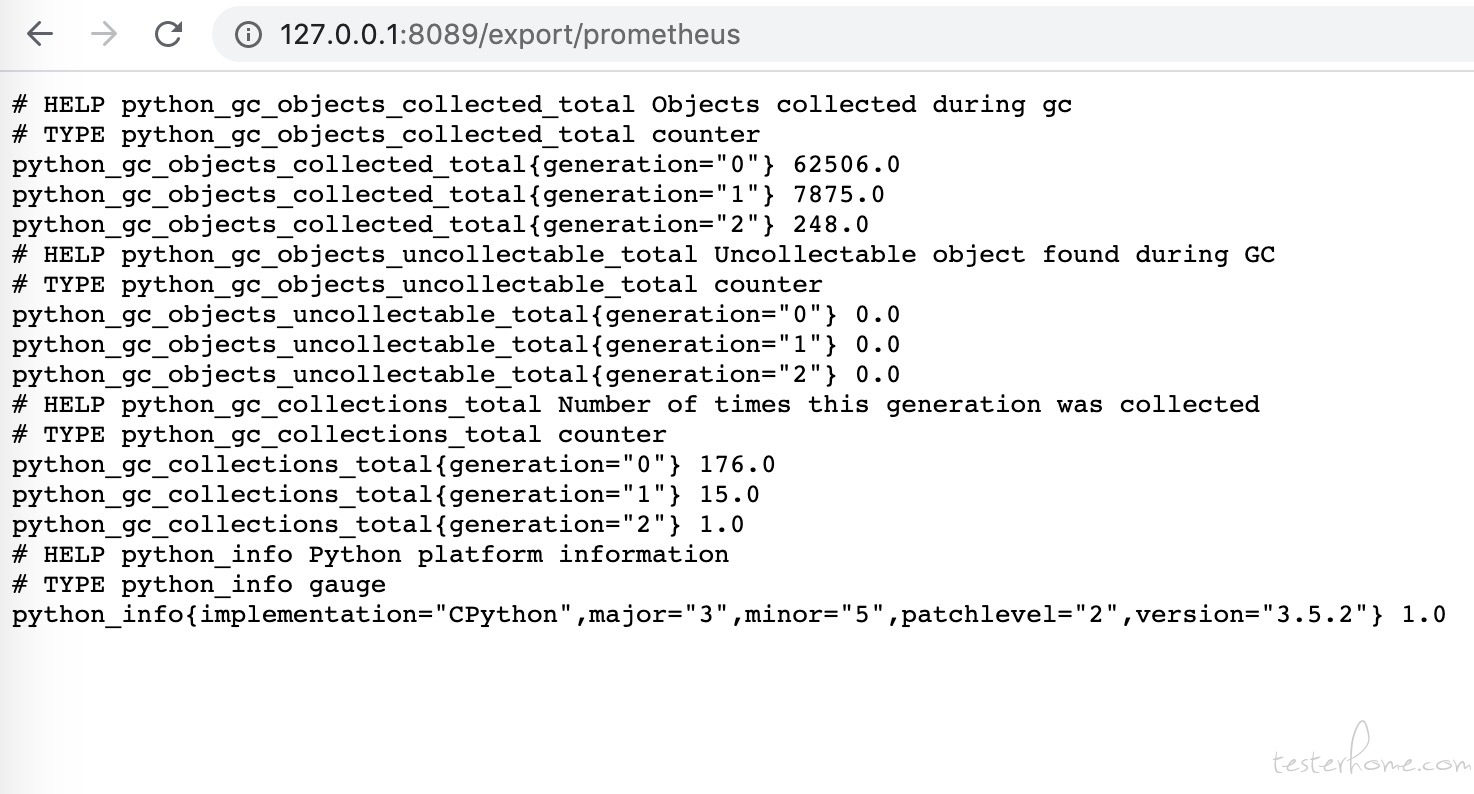
这是使用 prometheus_client 库默认产生的信息,对我们数据采集没有影响,如果想关注 master 进程可以在 grafana 上创建相应的监控大盘。
接着我们启动 10 个并发用户开始压测,继续访问下上面的地址:
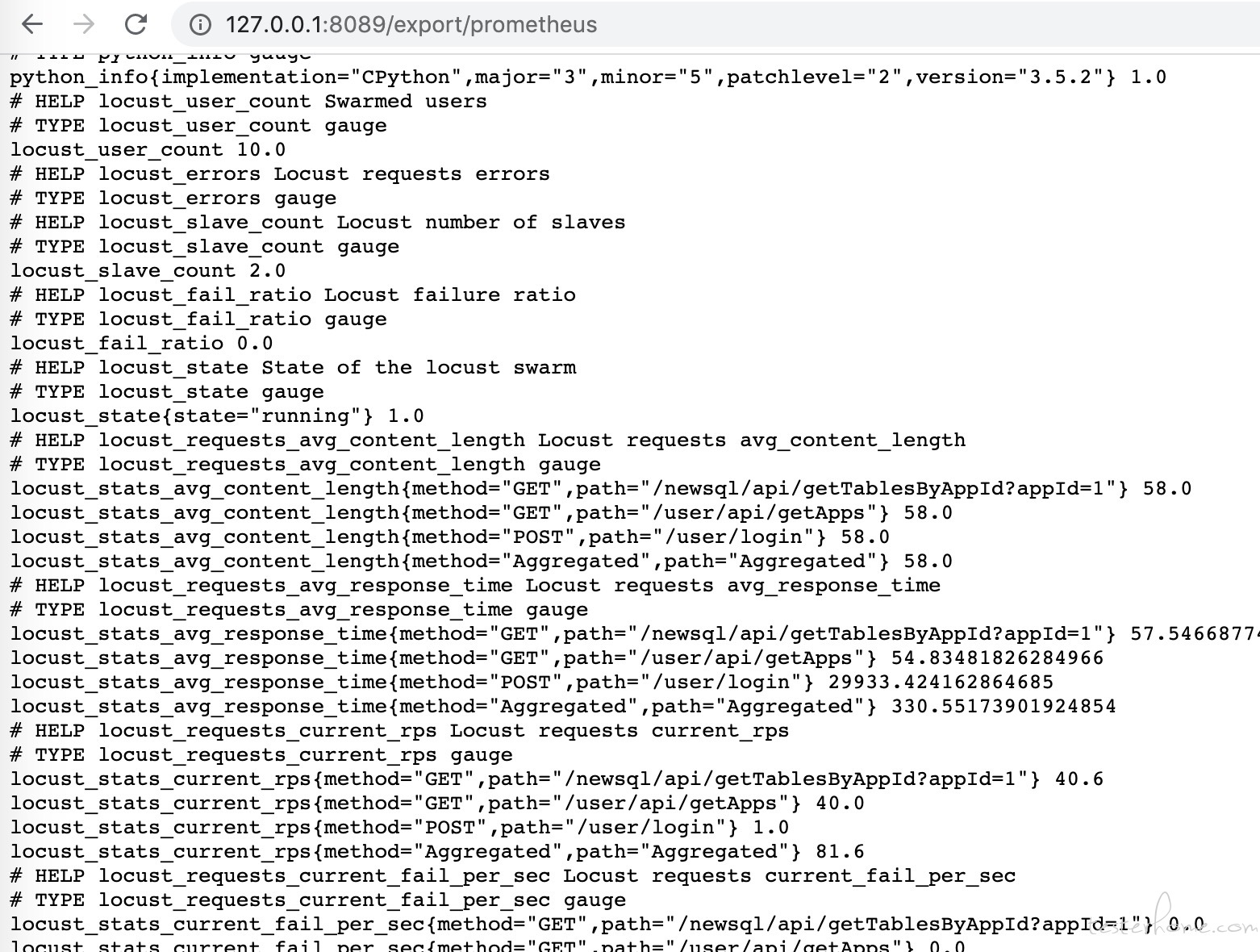
可以看到,locust_stats_avg_content_length、locust_stats_current_rps 等信息都采集到了。
Prometheus 部署
exporter 已经 ready 了,接下来就是把 prometheus 部署起来,拉取 metric 数据了。
1) 准备好了 docker 环境,我们直接把 prometheus 镜像拉下来:
docker pull prom/prometheus
2) 接下来我们创建一个 yml 配置文件,准备覆盖到容器中的/etc/prometheus/prometheus.yml
global:
scrape_interval: 10s
evaluation_interval: 10s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: locust
metrics_path: '/export/prometheus'
static_configs:
- targets: ['192.168.1.2:8089'] # 地址修改为实际地址
labels:
instance: locust
3) 启动 prometheus,将 9090 端口映射出来,执行命令如下:
docker run -itd -p 9090:9090 -v ~/opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
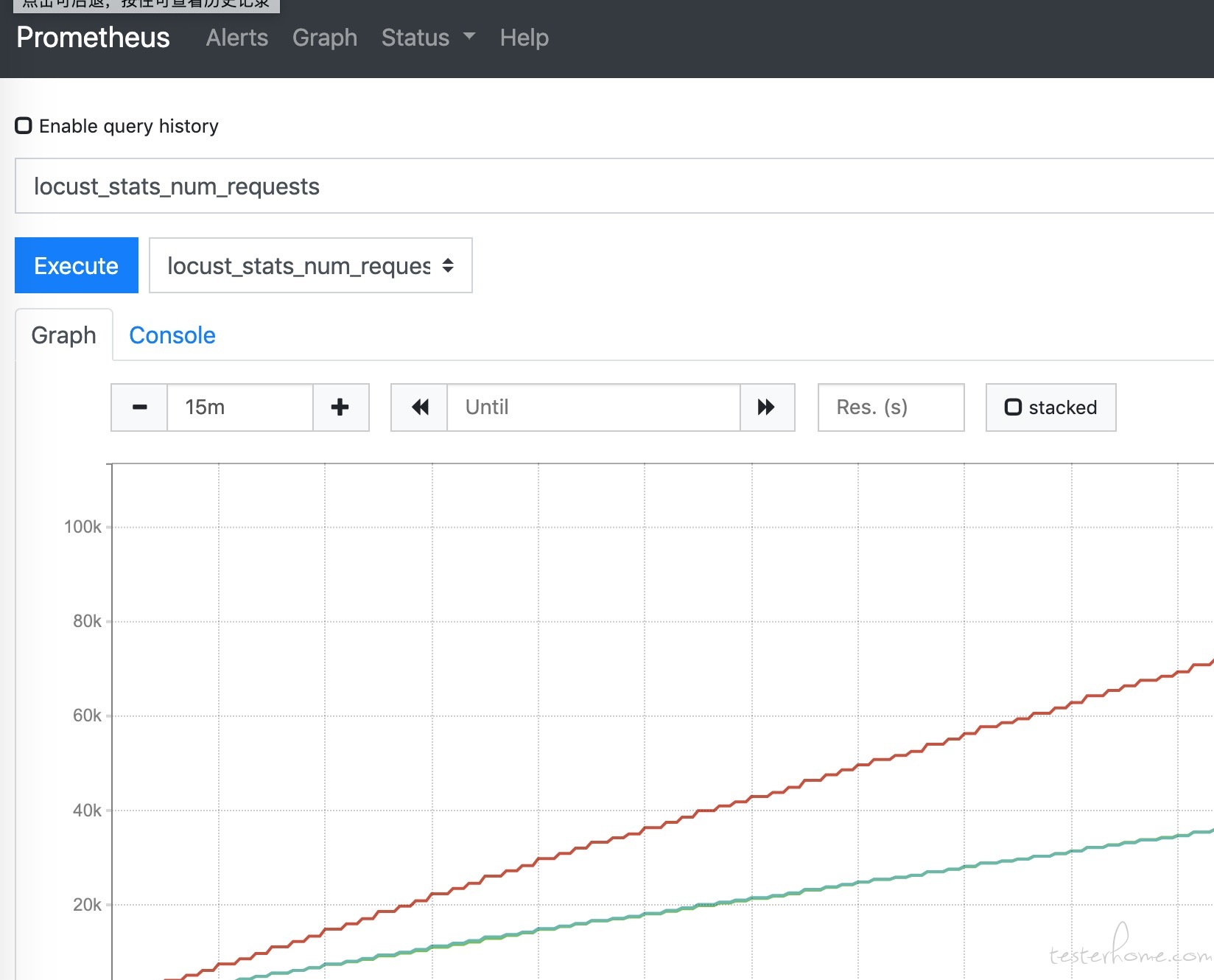
接下来我们访问 Prometheus 的 graph 页面,查询下是否有数据了。
http://127.0.0.1:9090/graph
Grafana 部署和配置
1)首先我们需要下载 grafana 的镜像:
docker pull grafana/grafana
2) 启动一个 grafana 容器,将 3000 端口映射出来:
docker run -d -p 3000:3000 grafana/grafana
3)网页端访问 localhost:3000 验证部署成功
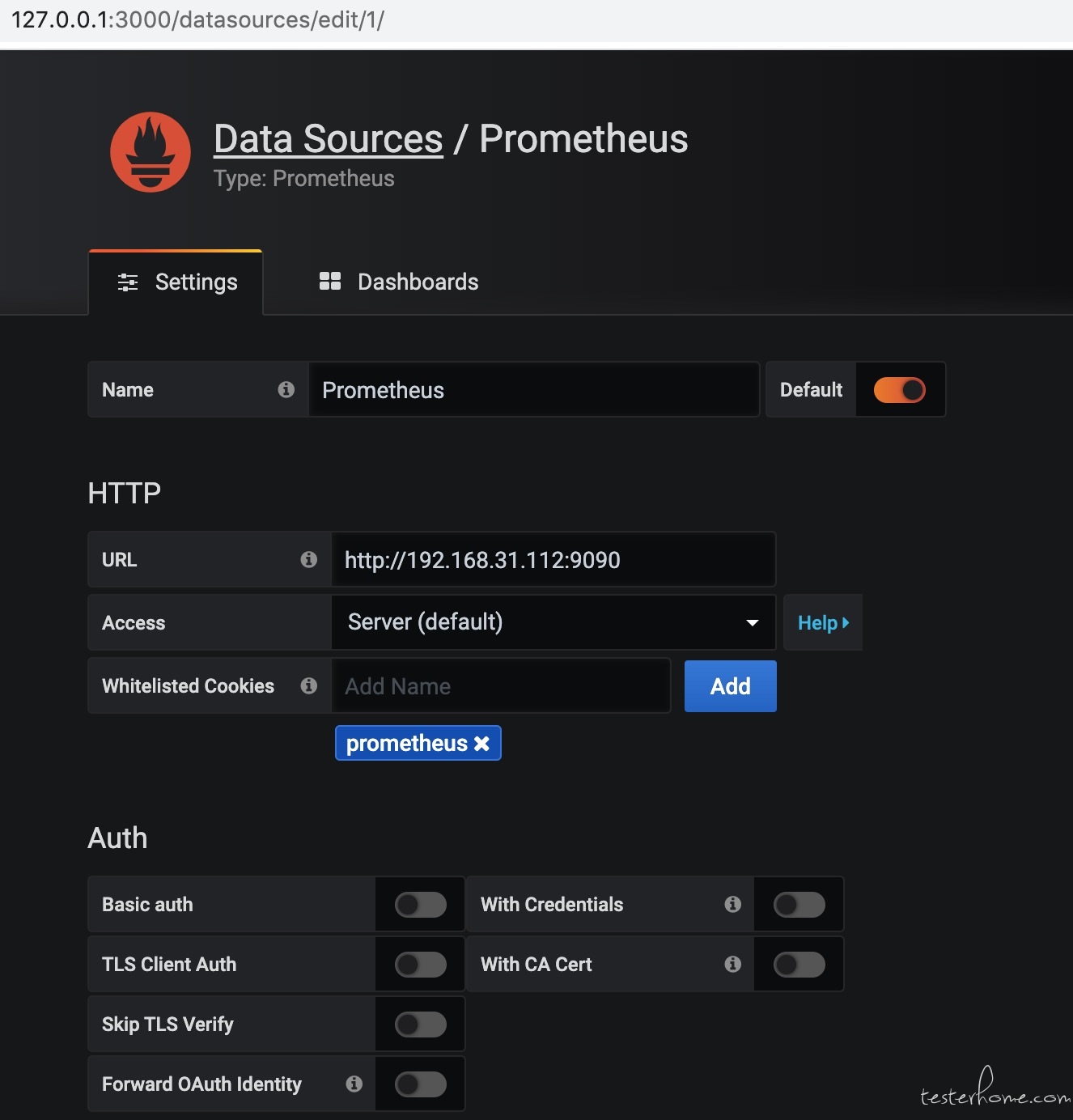
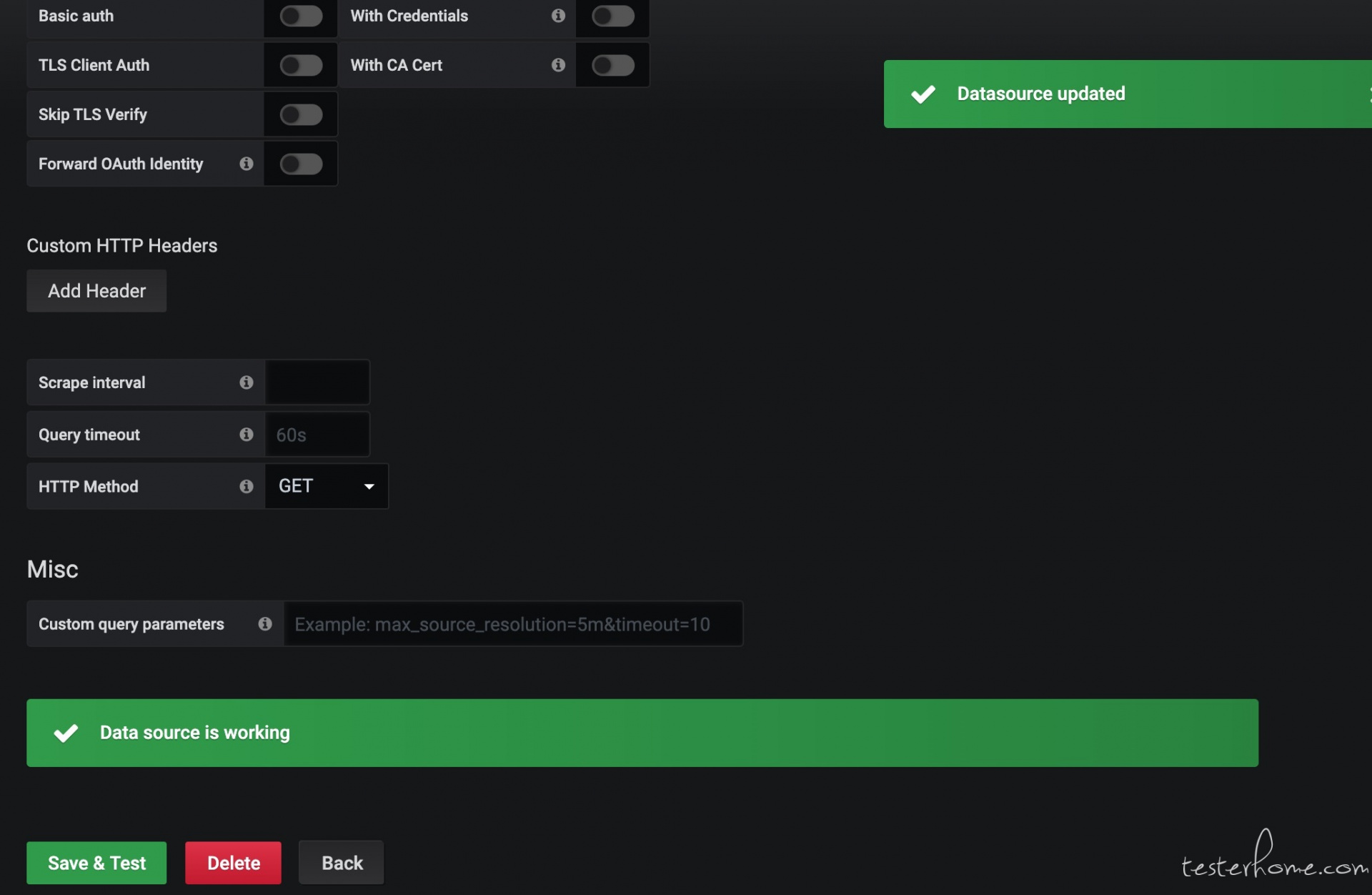
4) 选择添加 prometheus 数据源
5) 导入模板
导入模板有几种方式,选择一种方式将dashboard模板导入。
效果展示
经过一系列『折腾』之后,是时候看看效果了。使用 Docker + Locust + Prometheus + Grafana 到底可以搭建怎样的性能监控平台呢?相比 Locust 自带的 Web UI,这样搭建的性能监控平台究竟有什么优势呢?接下来就是展示成果的时候啦!
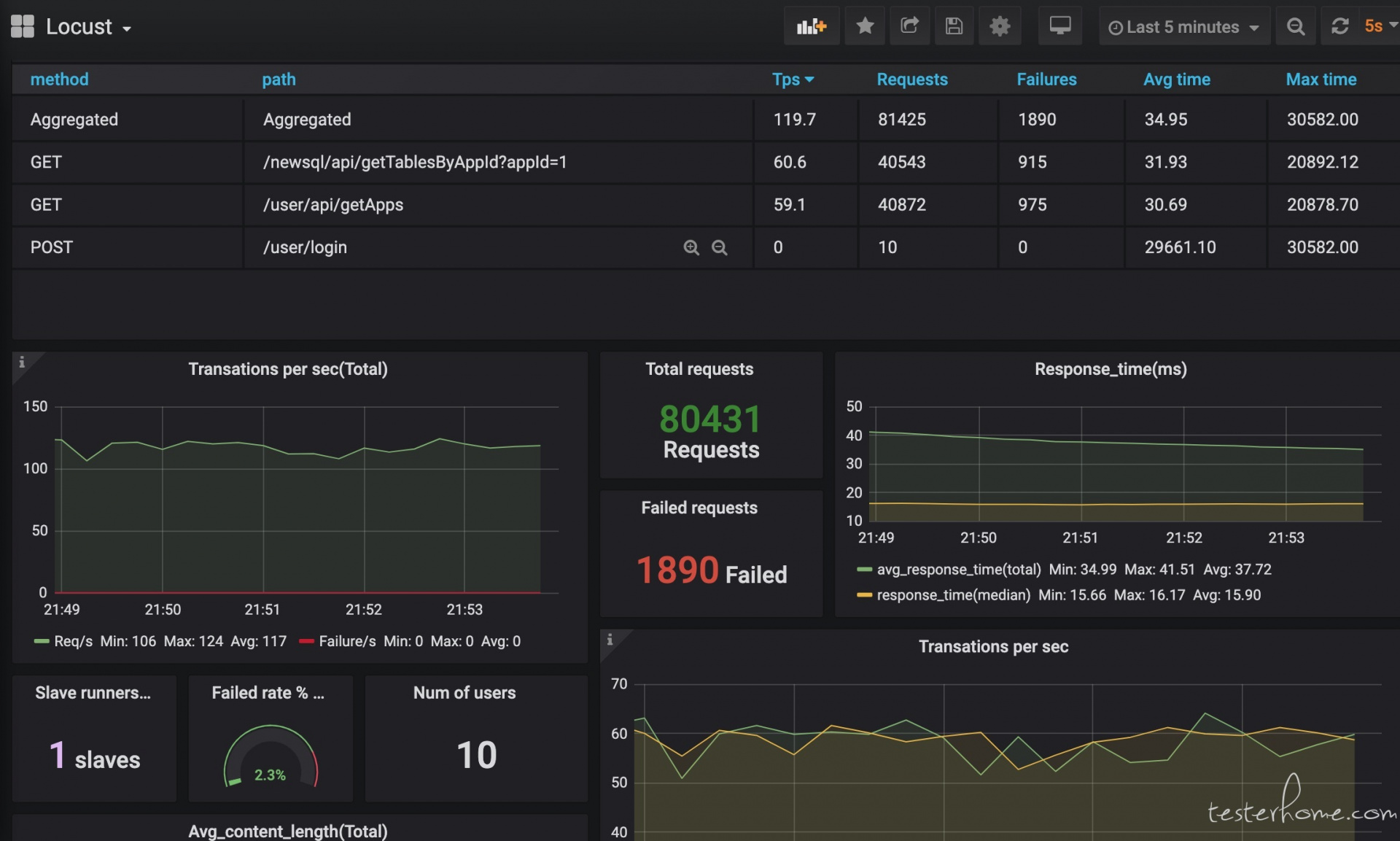
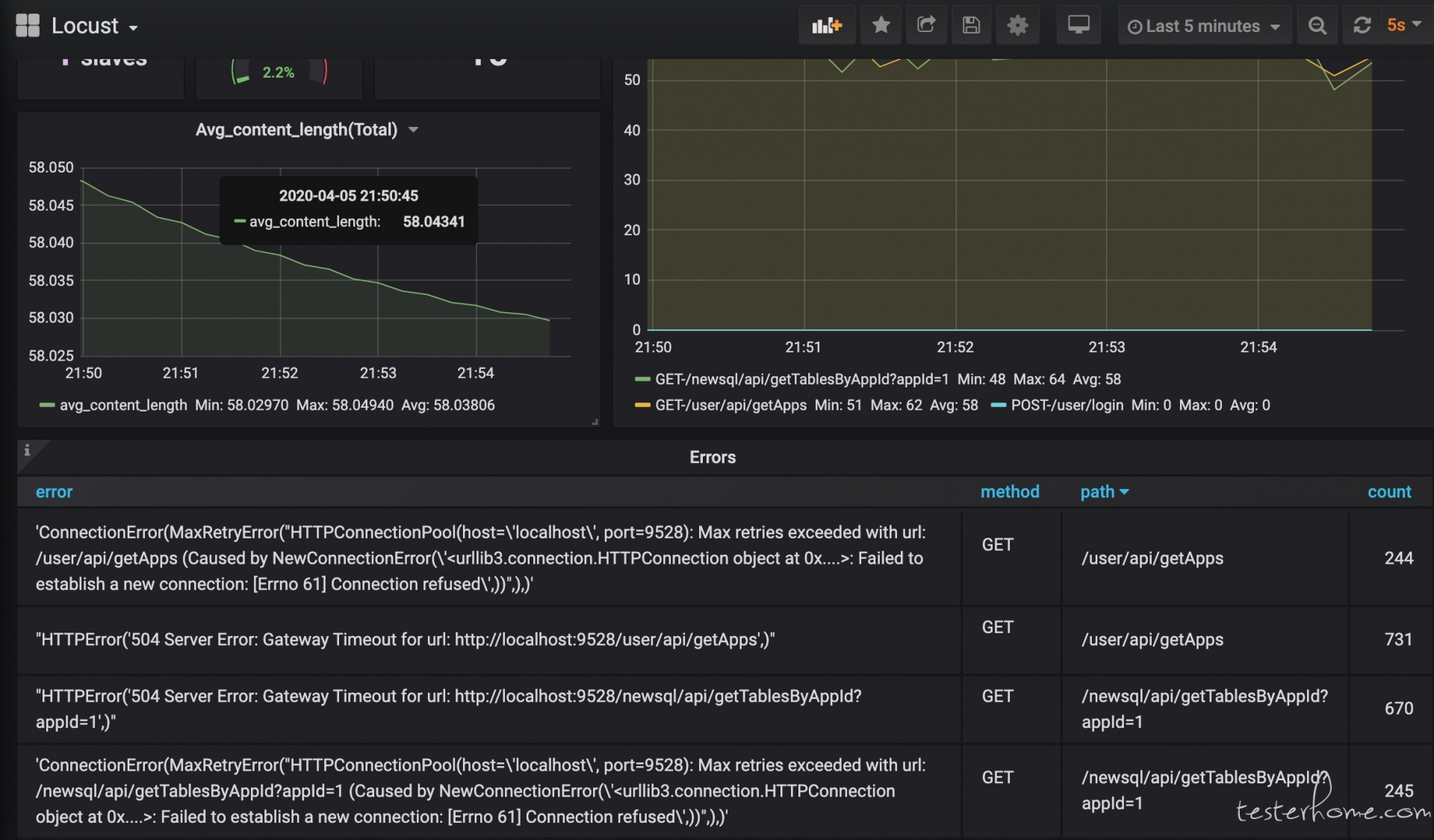
这个监控方案不仅提供了炫酷好看的图表,还能持久化存储所有压测数据,可以使用 Share Dashboard 功能保存测试结果并分享,相比 Locust 自带的 Web UI,简直太方便!如果结合 boomer,压测性能和压测报告应该也能让老板满意了!
写在最后
关于 Locust 的三篇系列文章,我结合自己的认知和实践终于写完了,对 Locust 的玩法也只是抛砖引玉,但我觉得也足够了,因为有些人已经通过我的分享做了一些东西,比如这篇文章。
以前我不习惯分享交流,喜欢闭门造车,但是从去年开始,我逼着自己去写 GitHub Pages 博客—— bugvanisher,逼着自己除了输入还要输出,去总结,去分享,我明白这才是能够更快成长的方式,共勉~
这篇关于locust能监控服务器性能吗,重新定义 Locust 的测试报告_性能监控平台的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






